Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
41:18 Webinar
5 Reasons to Use Storage Snapshots for Databases
Join this session to learn how storage snapshots can play a big role in delivering benefits, such as data reduction, ease of management, efficiency gains, and more.
This webinar first aired on 14 June 2023
Click to View Transcript
I love that loud voice. That's awesome. Uh, welcome to this afternoon's session. Five reasons to use story snapshots for your database. I eins. I'm a principal field solution architect here at Pure. I've been here at pure seven years.
I'm based in the UK, but I have an air role. I'm also an or was director and support the local business across Europe and Middle East and Africa. Antony, I'm Anthony Noo. I'm a principal field solution architect at Pure. Uh, my specialty is SQL Server Cloud, specifically Azure.
I've been a Microsoft MVP for the last seven years, so I get to work directly with the sequel server engineering team to bring new innovations to the market. So that's us. Hopefully you're in the right session and we're gonna have some fun this afternoon. If you struggle with the accent, it's because I'm from the UK.
So you have to bear with us. So we're going to count down 5 to 1. Some of the reasons that we think snapshots are great for your databases and this is what we've seen from customer conversations and our own practical experiences. Because we've both been data professionals. DB a S in previous life.
So, uh, we've worn your shoes. And, uh, this is our take number five initiating a database, and we're gonna throw the ball back and forward Talk about Oracle open source as well as Microsoft. So number five store snapshots for standby databases. So in the orca world, we talk about a standby. Uh, it's our It's our target for data protection.
So for for DR, this is typically in AAA a data recovery site AD R site. And we have If we have a large production database, you store it. This has been really painful. Uh, the bigger the database, the harder it is to stand up a standby database. You have to copy the data over there, configure it and then turn on the,
uh, redo streams that it applies. We can use storage snapshots to make this a bit easier. So any database size any location could be local, could be remote. Could be in the cloud with a zoo and AWS and cloud block store. We can take a production database snapshot, send that to our DR site,
and then use that as a way of shortcut in the creation of the standby Typically, this is done in an R man. Restore or file copy. Use a snapshot. Save yourself some time. What about Microsoft? So the same thing. The ability to get a database cloned, a replicated and cloned to another site.
And I think the real superpower of this is if I move that database from site A to site B, whether it be on Prem to cloud or on Prem to on Prem or even within the same data centre the first time that data moves between those locations, it's going to be the data reduced data stream. So on average for SQL server, it's about a 4 to 1 data reduction ratio about similar in Oracle space.
So for easy math, let's say I have a 40 terabyte database and a 4 to 1 data compression ratio. That initial stream is only 10 terabytes. It has to go between the two devices, right? And the way that we replicate data is very, very storage efficient. And so the next time I take a snapshot and then I ship that to the target site.
The only thing that's gonna ship to that target site is the blocks that aren't already there, right? And so the next day it's not a 40 terabyte or even a 10 terabyte database transfer. It's just what's changed since the previous snapshot. And so that gives you the ability to have that 40 terabyte database always refreshed at that target site.
If you need access to that, and you can do that in a storage efficient way across any of the platforms that we're talking about here today, thank you. So this is a not quite a standby, but it's also part of that same sort of use case scaling up AM SQL. So, uh, in an A world, we we don't have this so we don't have the concept of read replicas. But this is my and some other open source
databases do so they have a source database, and you want to scale up the solution. You create read replicas these take time. So here we got a one terabyte database network. Five copies, 69 minutes. It's not very efficient. The bigger the database, the longer it's gonna take.
Let's swap that out and put a flash of rain. Take some snapshots. Now we can do this really fast. Instant. It's similar in the in the sequel server space. Uh, the same concept exists the ability to have a read replica and and DB a S love to have that, because you can have scale out read performance for your platforms. And the ability to snapshot and clone those
databases is fantastic to build those replicas. Because in the previous state, if I wanted to build four read only replicas, I'd literally would have to take a backup and restore it four times, right? Think about the IO that goes along with that to perform that workload. And so that could take a very long time, depending on the size of the data doing that
inside of an array or even between arrays, those operations could become instant or nearly instant, depending on if it's a, uh, same array or between arrays. And it's not just seeing time because these are reed replicas. They are a copy of each other, so they're really space efficient. So as the source changes, you know the data reduction is going to kick in,
and these are going to you down to next to nothing so you can have as many read replicas as you like for free instant creation, and they consume no space. Nice number before production support. So, uh, I've been a DB a for a very, very long time. And there's a couple of things that we wind up having to do as database professionals with
regards to getting access to data. And that's really kind of gonna be the foundation of the entire talk today, right? Is getting access to data to the people that want to consume it. And so we're kind of jump through some of these things here, but I think about not ever having to give someone access to the actual production system. In your environment, it sounds pretty cool,
right? But if you need to go and troubleshoot a data anomaly, I could take a clone off of production and troubleshoot that anomaly somewhere else. Right? Maybe the business process failed or something. Calculation isn't correct inside the database for some reason. And so we can go do that on another device. Now we can.
Then if there was a data anomaly or even a physical corruption, we can go and test that fix somewhere else and have the confidence in that fix. When I go back to production and execute that change. Right? And that adds a lot of stability to platforms and database platforms over time.
Uh, we also in in the data warehousing world. The idea of being able to get access to data generally means I'm gonna go run some sort of procedure against production, figure out what data I don't have in the data warehouse, and then bring that data across to the other system. Well, what if we could just take a snapshot of production and attach it to the data warehouse
and then pull that data out on directly in a data warehouse server? And so production doesn't have to deal with the IO burden or the or the buffer pool issues or the network transfer of having to do all of that work, right? So production go can go on and being that low latency system that you would need for that transactional type workload,
right, and the other. And the final part here is kind of de risking production changes. Imagine being able to go into your change manager process and say that the rollback time is instant right? That's a pretty fantastic capability to have, uh I've worked in a lot of, uh, a lot of different industries health care, transportation and legal,
where there's lots of third party applications where some application vendor just slides a T sequel script across the table and says, Run this in production to upgrade your database. Right? Who's had that experience before? Right? And so imagine when you run that in Dev and you run that in, uh, your pre environments and everything works great.
And then you get the production of what happens. Something goes wrong, right? And so leveraging snapshots. We can snapshot the database or a collection of databases and revert them back to the previous state. And if it's part of a larger application upgrade where you're changing Web servers and application servers in the middle tier,
imagine being able to snapshot that whole platform and reverting the entire environment back to the previous state. Right. That gives you the ability to revert back from a failed, um, a failed upgrade process very instantly, right, without having to put your cape on and get in there and figure out how to get that system into a good state.
Just revert it back to a previous state. Yeah, I love that use case. It's easy to think about it doing it ad hoc on demand, but also for your support guys every night. Just create them a new support environment. So they got end of end of day figures so that it's there the next morning when they come in.
Nice touch backup window challenges. You know, we hear all the time. Backups are getting longer. Database productions database are getting bigger. The window that we can do our backups in is getting compromised, shrinking. Maybe you're being removed.
Companies want to work 24 by seven, and it's a pain. It's really hard to make sure that you can have a repeatable backup process that you know is going to complete in a timely manner. Cos what we want to avoid is that scenario where you come in and the ops team have killed the backups because it's compromised in the online day.
It's not where you want to be. So what we can do with a storage snapshot, we can offload the backup onto another host. We call this a mount host. Uh, so we remove the backup workload from the production database server we run that against a secondary server and that secondary server can be configured for
backups. It's designed for backups. So maybe it's additional network interfaces in there. Maybe it's actually rather than having a single 10 gig interface for application traffic. It has multiple 40 gig interfaces for backup traffic. So you have a storage network for your NFS or SMB backups.
So it's a really powerful way of doing this. You know, we can move the backups from there onto there. Uh, we could also use our standby database. You know, we can actually take a back up from there so we can work out the best way of running the backup. So we take that load of our production server.
Would you have the same sort of thing as SQL? Yes. An additional, uh, concept to add there, though, is, um, the tech TV is a process on SQL server that checks the integrity of the physical integrity and logical integrity of the database. And you want to do check DB, uh, with basically within your full backup window?
Uh, I think a full backup. Another full backup. You definitely want to run. Check DB somewhere in between that spam because if the database if there's a corruption in the database, you still need to be able to recover, uh, in. But check DB much like backup is a very IO intense process. It literally reads every database page and
checks it for physical and logical in integrity. And it's a very IO intensive process and one of the first things to go much like bullet Point number two here. When you have IO pressure in a system, especially in 24 7 shops, the first thing to go is people will stop running check DB right. They don't think that it's a required task or the business says Stop doing that because
you're impacting user workload. Uh, you'd be surprised the number of 24 7 companies that don't do check DB but leveraging the same exact technique. I can snapshot clone to another instance and just have a dedicated instance to run Check DB. Now, if there's a failure of check TB, I have a copy of physical extra copy of the database. I can develop the fix and then go back to production and confidently fix that corruption
in the, um, the production database without having to go and figure out what blog article to read to figure it out and then go execute that as I'm a little nervous after too much coffee in the middle of the night trying to fix that issue in, or we would use our man to validate our database. Uh, also, we can use DP verify to check the database blocks.
So this is talking about moving the date, still running a backup, but running it on a different server. So we also have the option of taking a snapshot and having that as a backup. But then that does mean that you have the risk of a block corruption. So you it's doubly important there to make sure that the integrity of your source databases
who's ever lived through a physical database corruption, anybody? No, it's not fun. Number two develop agility. Oh, yeah, this one for me. Yeah. Uh, so we'll we'll start with, uh, a customer story.
I worked with a financial software company in New York, uh, last year, and they developed software, and I forget the exact number of versions. But let's say they had 10 supported versions of their application that were in their install base that they had to run all of their, uh, tests against before they released. And what they wanted to be able to do was get copies of databases of multiple databases to
run their tests across all these different versions of the application that they had to support. And so they came to us, and they're like, What can we do? And like, Well, you can take snapshots and clones and take as many snapshots and clones as you want to run against these 10, uh, regression tests that they wanted to run in their data set.
And so and we could do this inside the array instantly and independent of the size of data. And so they had customer databases that they wanted to test all the way up to the tens of terabytes. But having to do that with backup and restore, put a lot of, um, let's just say dead air time on the developers where they'd go kick off the resource and they go do something else for a couple of days and then come back and run their
tests. And so leveraging this pattern here, they could snapshot and clone run their tests. If there's a failure, fix it. Snapshot and clone run their tests right? And the idea here is developers can stay in context in their task and complete those things more quickly, right? So giving them, making them more productive to
do what they want. And so at the top here I see, we can see that it's space efficient database clones. So if I want to cut 100 copies of 100 terabyte database, that's just 100 terabytes inside the array. Now, as data changes, uh, while that snap those snapshots and clones exist, that'll be surfaced as a metric in the array,
about how much space is dedicated to snapshots. And so you'll see that. And so for a provision. In our sizing standpoint, you just have to make sure that you have enough capacity to support your workflows. The other part is from a developer standpoint, we can give them the ability to write code to access the arrays, to do these things that we're talking about so we don't have to go and
log into the array and cut a bunch of copies of a bunch of volumes to give to the developers. We can write code in powershell Python Rest, answerable, terraform, bash, curl. What are the other ones that you guys use? Do you want any code examples? Code dot Pure storage dot com and you can find some of the scripts that Anthony and myself Yeah, and so that being able to give the
developers the ability to execute these tasks without having to ring you up or open a ticket right. But putting safeguards around it such that they can only have access to the things that they need to have access to. So I work a lot in the SQL server space, so we see customers that are doing scheduled snapshots via things like SQL Server Agent or something similar in your side of the fence.
Yeah, lots of my customers use answerable. It's a really popular automation tool because it doesn't just automate the, uh, the storage platform. We could automate the database platform and using the answerable Linux modules, we can stop services. We can unmount file systems, so it gives us the ability to end to end automation, addressing some of the concerns
that a lot of storage administrators have about giving DB a access to the array. Uh, some some houses. That's not possible. So we could then deploy a portal. So the the developer, the Q a team, you know, they have had access to a portal, and that makes the connection to the database server and to the flash away.
So that's completely hidden away from them. They don't see the code. They just see a interface with a simple button that says refresh really easy. Yeah. We've seen some customers even go so far as to build service out integrations with some sort of approval process, uh, before it goes and executes the workflow to take snapshots in here,
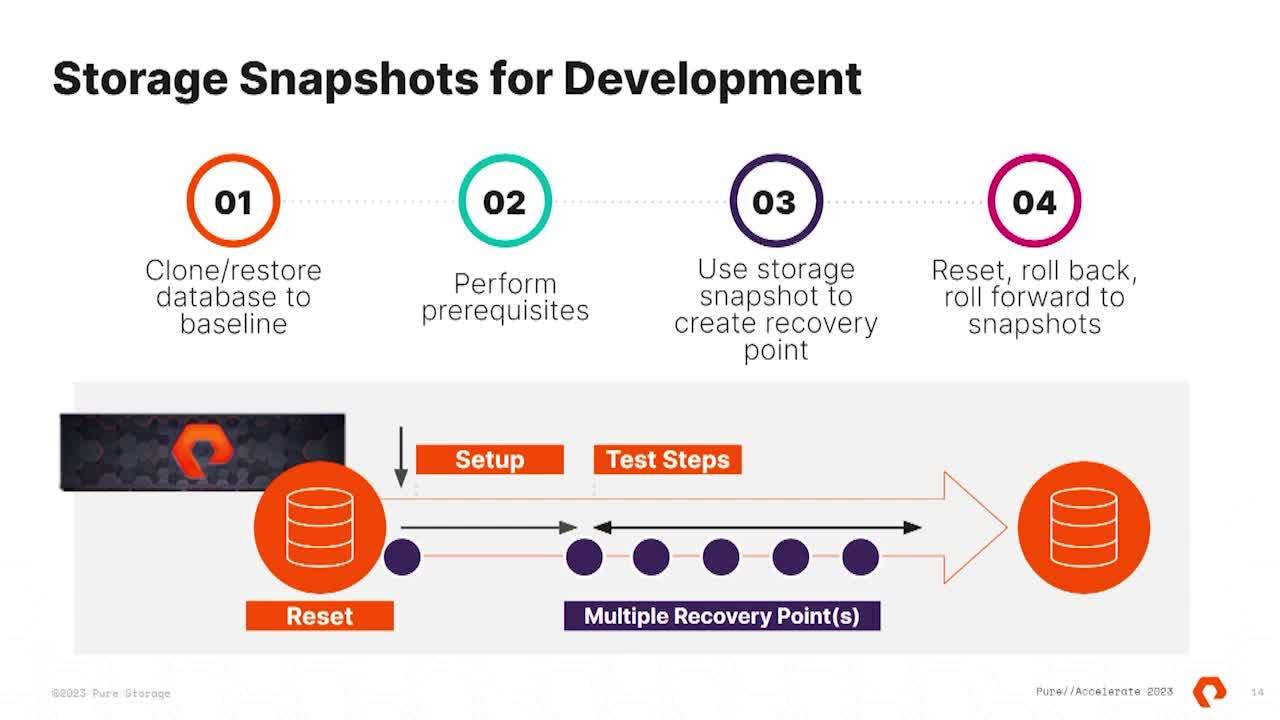
right? Uh, yeah. And so the idea here is that we're gonna We're gonna meet you where you are in your automation journey to get access to this data again. Independent of the size of the data on the array. Yeah. So this really is that process really mapped out? You know, in the visual respect.
So here you can see we've got our baseline database on the far left, you know, And that could be initiated from a Standley. It could be initiated from a clone, a backup or you know, ideally, a snapshot from your production system and you're using that. But it doesn't matter how you get the data on the flash away.
It might not have been a flash away as a source database, but we've got our baseline. We then want to, uh, do our prerequisites in the development test. Say so. We do ops, empty workflow tables. If it's a copy of production, maybe, uh, some manufactured data, this data bill on other data or synthetic data that we load to satisfy our testing could be
additional database schemers. But all the stuff that we need before we do our testing, then we create multiple recovery points. So once we've got one after our set up, take a snapshot. Do step one snapshot. Step two, Snapshot, Step three, snapshot. All of those points.
Give us the ability now to roll right back to the beginning, reset the test. There's a problem of our initial setup Or go back to step one, get better outcomes by doing, rinse and repeat. What we find is if developers have to wait two weeks, if that's your SL A for a database
refresh. They don't ask for a refresh. What they'll do is carry on testing with dirty databases, and every time they do a test run, it becomes less representative, so enable the developers to take advantage of the snapshot. It's not just about the production database. It's about the development database.
Yeah, one of the It's interesting from an automation standpoint. There's a there's a It's the simplest thing in the API, but there's the ability to add a suffix to a snapshot. And so when you take a snapshot in the array, you'll see the uh, whether it's a protection group or a volume a dot and then an integer value that increases
right. Well, we can control the suffix or it's after that dot in the snapshot name. And so when you start building work flows, you can leverage that as to identify and give your developer some logic about what that snapshot really means at that point in time. So we see this also a lot in the data warehousing space, where you might have a multi phase data warehouse process.
That's seven steps right, and it's moving hundreds of gigabytes of data between the system and maybe I need to revert back to step three, not go all the way back to step one and kick that flow off again. And so, with the snapshots of the suffix, you're able to go and say, You know what the actual checkpoint that I want to go back to was Step three right? And being able to leverage all the benefits of
what happened in steps one and two before the thing failed. Or if there's a development life cycle like this where I want to get access to a particular phase of data over time. Because oftentimes as developers, when we're changing data in a database, it's not one big bang. Change is I've changed some stuff. It's kind of a checkpoint.
Validate and move to the next phase in a database change, especially if we're doing like a schema change for an application upgrade. Yeah, what I'd add on that one is we've got this as a straight line for multi Cobos and that's going back in there. But every single one of those points, we could create a clone of that which is completely independent so we can start
branching so we could do all the set up and maybe the setup takes a long time because you've added manufacture data. But you want to do tasks in parallel. So you give a copy to the U. I testers one to the report, developers one to the business owner that's doing application regression testing. And they could all work independently,
really powerful. You know, if we get to step three and we know we know our data load has been complete and we're good to go there, you know, let the business carry on testing, But you give a copy to the team that's going to do performance tuning. So you know, we can use the snapshots. Give us that development ability to shrink.
Timelines don't have to work. Sequential. I had AAA Bank in London really strange way of working until they adopted pure. They had team Red team blue team Reds data destroyed team blues data so they couldn't test together so they would negotiate which team was working on the on the database and actually swap weeks so that one team could do their
testing without. If you're developing a report and someone's adding new data, you're not getting consistent results. So they had to work independently. They had to say No, stop what you're doing. Let us do some work and then they'd hand over. Now they just do it as many as they want. In parallel,
there's no blocks. Sometimes you get a challenge. I'm not sure. Have you have the same concept in SQL Server? We got flashback so normal we can flash the database back to a point in time. No, we don't have that flash back. So we got a flashback query as well. We can query back in time, but flashback. If we're doing it at the database level,
it rolls the database back and the further you go back, the longer it takes. If we do it this way, we can roll the whole environment back. So let that sink in. Not just the database but the database environment it is in. So if you're doing an application, upgrade, database upgrade.
So for Oracle 19 C is the long term support version. You may be running 21 C, which is the innovation release 23 C free developed petition is out now, so you could be playing with that. But 23 C is going to be going in G a later this year. So when you do your upgrade from 19 to 23 plan the use of snapshots.
Think of your snapshot as the database plus the Oracle binaries. So now take a snapshot as is, do your database upgrade. OK, done that. Revert it back. Do it again. Do it again. Rinse and repeat, tune the process,
Document the steps. And as for that, you know that earlier slide when you do it for real, you've done it many times. So you know how long it takes. And you know the outcomes of each step. You, you practised it.
So it's always been fearful when you do a database upgrade on a production system. Yes, I've done that on UAT. It is UAT the same. Well, maybe not. Use a snapshot, roll the whole environment back. Do that rinse and repeat, you'll get better outcomes.
Yeah, So even another, uh, facet of that is, if I so I generally have never upgraded a sequel server before. Do you know that? No. I always build new and migrate the data right. And because the idea is, I want to leave the baggage behind because sequel servers in my world generally live about 3 to 5 years, uh, in production before they phase off and have them
move forward, right? And so it's I always take the advantage of Let's leave the stuff behind, build a new pristine box and cut over to that. And historically, I would use a powershell to do backup and restore to do that. But that becomes the size of data operation, right?
And so imagine, uh, in your down time window when you have the upgrade, right? So or pre or the preproduction testing. You know, clo snapshot clone to the new server. Run all of your testing, you know, fix the bugs and keep iterating on that process. But the actual cut over is just snapshot clone to that new box and then DNS pointers to that
new server. And so now your database upgrades are instant right or whatever the TT L is for your DNS to update. So good stuff. Really cool. Yeah. Number four reset. Roll back. Roll forward to snapshots.
This is one point where I say that not all snapshots are the same. If you've used the pure snapshots every time you do one, they're completely independent. They're immutable. We don't write our snapshots. We create volumes from snapshots, but you can on that timeline.
It's not just a question of going backwards. If you go back too far, you can go forward again, not saying that all the other vendors can do. So. It's when you've used snapshots. Maybe you've had a bad experience on the database side. You know, maybe you've used a copy on right, and the performance wasn't good enough.
You know, it's the way they're implemented and pure does it best. So you haven't used snapshots of your database and your development Life cycles definitely have a go. Yeah, there's, uh, What we haven't covered so far is that there's zero performance impact on production, right? So think about safe mode. What safe mode does in your platforms?
It's gonna periodically take snapshots all the time under the hood, and none of the applications know the wiser right zero proof impact. Same thing with it's an ad hoc or periodic snapshot in the array. It's gonna go take a snapshot of the database or the volume support in a database and clone that and that clone will 100% always be a recoverable database.
So, um, historically, you're talking about things like people might have had a bad experience snapshots. But the idea here is that we've implemented in a way that that database will always be recoverable. There's no performance impact on production. There's no IO that has to go along with that, Uh, but it's not a free lunch.
Uh, if you think about what you're doing with an array, if I have production and I snapshot and clone another database, well, now I have two databases, so I have to make sure that I have the workload capacity to support that. If I'm querying both. Well, I just need to make sure that I don't overrun that platform on production.
But that's where a Sync replication becomes great where I can take a database, replicate the volumes to another one clone and go and have that workload across multiple arrays in my data centre. I guess it's it's another use case around the development side. We've got the the reset the environment there in many financial organisation and highly
regulated environments, they won't allow developers access to production data. Yeah, it's just not not the thing to do so use your so you know, this could be the production system. Take a snapshot on your production platform. You do the data cleansing there, the ossification, the move in sensitive data. Take another snapshot there when you clean that up, and then you replicate that clean version
to the development platform. And then the developers can then work completely independently on a clean set of data that you ordered as a happy for them to use. So it's it's a version of that, but it's just like where the where the production system starts and that's following on from Anthony's about using the, uh, the snapshot.
Ay replication. Yeah, go ahead. Oh, this one's you. Yeah, this is one. So if you want to get going with this, this is a, uh I said Anthony's got scripts on co dot pure storage dot com. I've got something called or on the, uh uh co dot pure storage. Com. It's an answerable playbook.
Uh, it automates the flash array, plus the database server you rate really nice code comments. So that's the the Github repository. Uh, it's it's really easy to read. If there's any questions, you can go back to us, but I Basically I as you say the same. I shut the The target database is down the way the answerable flow works.
It does tasks sequentially. Uh, but it won't move on to the next step until the slowest ones completed. So we could do this with one development database. I typically demonstrate a handful, but it could be 100. It doesn't make a difference, and we roll them all forward.
So I stop the production databases, I unmount the file systems. If it's a file system based one or if it's an a SM. If we unmount the disc groups, this is the same really process for for nearly all databases. We then take a snapshot of the production database. So unlike other technologies, we haven't had to go to the database server and install a
database account. We haven't had to create an additional operating system account. We haven't had to install any agents on that box. So we tick lots of boxes there from the compliance and security teams that don't like third party software. Running on the boxes don't like open accounts
for service accounts. So we take a snapshot on the production side. Once we've done that, I overwrite the volumes, my development, testing volumes. I remount them. This is answer modules. Doing this is now. It's not talking to the flash away. It's talking to the database server,
so it uses the Linux Mount Command to remount the volumes. I then start the database up. As we said, when we do a database clone, it's just metadata. So whether the database is 10 gig 100 gig, 10 terabytes, 100 terabytes, it doesn't matter. The size doesn't influence the time.
What influences the time is the power of the machine that's doing the work. So an Oracle database. It takes me a couple of minutes to shut it down and start it up. I've seen the SQL Server ones, and they're really impressive. You do it in seconds. It's nearly in on the SQL server side, the workflow is nearly identical.
You stop the target database, you then, or you can offline it in sequel server terms. You offline the disc, then you do the snapshot clone online to disc online to database, and it's magically there. Uh, the only opposing force where I've seen time become an issue is when you online the database. If there's what's called a long running
transaction, Uh, and that transaction is not committed. Has to roll back, right? We might have seen that before where your database is in recovery mode. And so if you take a snapshot and you change the terabyte of data and it's 99% of the way through that, what's gonna happen when I online it, it's gonna have to go undo that one
terabyte of data. And so you just don't want to get in a condition where you do a snapshot. After a very, very, very large data change event, Uh, SQL Server 2019 introduced a feature called Accelerated Data Recovery, which gives you constant time database recovery. So even in that one terabyte condition, the database would recover instantly.
And so you can attack that problem with a more modern version of SQL server so that we can do something similar though we will, you know, it's the same as doing a power cycle, or we look into the, uh, the logs, undo commute transactions and tidy up the, uh, the The rights haven't been committed yet. What I like to do when I do all database cloning is to make it obvious to developers
that are not working the production database. So if we stop at 0.4 is a copy of production, it's consumed no space. It's just metadata. The next step I like to do is rename the database the development name and potentially renamed directories and data files. So this orchestra is fully parameterized.
It's dynamic. The first thing I do is when it's SSH is on the server. It creates all the or directories because they may not be there. So the diag, the C dump U dump directories so it configures that up it then dynamically creates using a Gen two format and the template and answerable the scripts. So the new database name and the start up the
shutdown scripts and then answerable runs the commands. So that's a code example free to use. Download it. Tell me what you think. Number 10, boy, this is This is the biggie. We've been holding it back for number one, and it's strange. I guess it wouldn't have been that long ago. We would have said that,
you know, develop of agility or keeping your production system and your backups are really a number one Data protection. Now, this is what keeps us in our job. If your database goes down, was made unavailable. So availability and resiliency and the security of that database is really what our database jobs are about.
I did a presentation and I've been talking about it, you know, with the guardians of the database. It's our job to look after it. Uh, safe. Most snapshots is our superpower. We can't say Guardians. Guardians. We didn't know the marketing budget to get approved for that bad superhero. Right?
Go ahead for two snapshots. You want me to grab this one safe mode? Safe mode. OK, I already covered safe mode. No, no, no. OK, so safe mode, uh, is the ability for the array to take periodic snapshots of volumes in a protection group right and strongly encourage
you to leverage this in your platforms? And the idea is, it's a kind of a two key scenario to be able to go and delete any snapshots in the array with safe mode, right? So, again, protecting against rogue administrators or compromised credentials. I've lived through both of those scenarios and production systems and they're not fun. Like, not a lot of sleep has occurred.
And if I had these platforms or this ability to undo what happened in those scenarios, it would have changed a lot of things in that. Specifically, the one platform that I saw go down due to a rogue administrator was a document management system where there was a database and also a file store of hundreds of millions of files. What's fantastic about restoring 100 million hundreds of millions of files,
right? Nothing. And so leveraging this would have been able to revert the platform back to the previous state. Uh, before that person well went to jail. And so, um and then obviously compromised credentials. The idea here is that even if someone does get access to your credentials,
they'd have to involve our support organisation to go to remove that data. What you don't want is a disgruntled employee who's on his way out of the organisation and think before I go, I'm gonna delete all the backups. I'm gonna delete all the snapshots. No, this is gonna save you. And this goes back to our, uh, our 321, using our snapshots to protect our primary
database on the far left side there. So we have our flash array. We want to protect that. We want to get our backups off the primary array. So when you have a backup, if it's on your primary array, that's a single point of failure. That's a single position where you can lose all
your data, your production data for your backups. So always have your backups off Array snapshots are complimentary to your backups, so we have our snapshots on our primary array, and they are great. They they could be our get out of jail card. They could give us that instant recovery, as Anthony was talking about. You're doing an upgrade,
you roll back. That could be your first port of call your backups. There, we would say suspenders. You say suspenders and belts. We say belt and vases like chips, chips, chips and cookies and lot of different ways. A database service,
you know, get your database to back up to a flash blade. So your data backups off your primary array. One thing I like to get people to think about, um isn't really a backup strategy anymore, right? So you got data protection here, but really the rest resource strategy, right? That that first thing I'm gonna grab for is
gonna be an array based snapshot because that's an instantaneous operation to restore the database back to a previous state. Uh, another thing that we talk a lot about with customers is not reverting back. A whole database. Maybe the what was damaged inside the database was a subset of data. Or so maybe production is still running. But maybe I lost some reporting capacity or
something in the database that isn't bringing the database down. So leveraging backup and restore techniques, What would I have to do? I have to get a back up. I have to land that backup somewhere in the environment. Which means that database is, you know, tens of terabytes, potentially. And then to go get that data and stick it back
into production In an array based snapshot, I could take a previous snapshot, clone it back to the same instance put attached to the database with a different name and just take the rows out. And so that's instant and storage efficient. And so that's a pattern that we're seeing a lot of people use to get access to subsets of data. Uh, the other thing I talked to customers a lot about is again in that lower That that kind of
that tier zero resource strategy that flash, uh, the flash rate snapshot being the one I go to first is I still want backups. I still want native backups because I have kind of an information life cycle management process that I wanna, whether it be regulatory compliance. Or maybe there's again a business process that failed.
And I need a back up from three weeks to go to troubleshoot a data anomaly, right? And so we still I still want data backups, and I want that data flowing out of the data centre. But the ability to go and pick an arbitrary backup from some back previous point in time if the database damage was a logical one, not necessarily a physical one.
Yeah, I've worked on some databases, and they've been so large that the business won't accept to restore. So in that scenario, the the protection method is you fix everything in situ surgical fixes. So we talked about using snapshots and creating data fixes and applying them.
So on this side, we would maybe take a snapshot periodically and maybe use a snapshot to give us a before and after image. So we see what the data looks like there, and we create a snapshot, go back to that one and dream up at the same time. And then we can create a SQL statement to update the data,
as it was an hour ago from that snapshot. So it's they're complimentary. So our man backups, very few D BS, are going to stop taking our man backups. You know that they are core to the way we work. They actually give us us very granular recovery mechanisms. If we're using snapshots as a recovery method, you need to think about what your what's inside
that snapshot. It's a physical entity. So you if you've got multiple databases, especially in a SM, if you've got plus data plus FR a plus control redo, you may need to have more than one of those so that you can restore one database independently to another. So think about how you lay your database out on storage platform so you can restore one or many
databases. Yeah, I was just talking to a customer, Uh, a few minutes ago, Almost. Which is why I was, like, two minutes close to get in here. Uh, that exact question was asked to me is, How should I lay out? The database is like, Can I just put them all in one big giant volume?
Uh, on a physical server? Yeah. From a performance standpoint, I can put every database in my environment, uh, on a single volume and get the performance out of the array. But you have to think about the other use cases inside of SQL server inside the database engine that you're trying to protect. At a minimum, I'd want to have two volumes for my database and the transaction log because
there's special recovery patterns that I'd want to get out of that. But then also the snapshot, uh, the granularity of snapshot. Now, that statement I made about running everything off of one volume that's specific to physical servers. VM ware has a whole bunch of, uh, other constraints due to the architecture of VM ware.
But the idea here is we can get those snaps in the granularity of snaps out of the, uh out of the volumes, um, in the array. But there's also data reducing. So even if there is a whole collection of data on that source volume and I snap and clone it, it's just gonna be metadata operation in the array. So and it's easy to think of snapshots just on the flash away.
We also have snapshots on the flash blade, so it gives us the same protection, same safe mode, same way of protecting our primary data and also protecting our backups. Here's an example of some SP SQL code, you know, just so that we can, from a side, a database, we can take a snapshot. This is actually for a flash away.
Flash away. So quite a flash away session. Use rest API there to, uh, create a session, and I can connect the database and then from my database. Now I can take a flash away snapshot without visiting the flash away itself without visiting the operating system. Because not every DB a has access to the flash Ara.
Not every DB a has access to the Linux operating system. Some developers only get access to a database end point so we can give every day Every developer the ability to take a snapshot and have it fully automated. Here, we're taking a snapshot. I pass the, uh, URL and, uh, it's signed on the database. You can see it's signed on the pure user,
and it's taken a snapshot called Z or one PG And we can see that in the, uh in the bottom corner. And as Antony was talking about the the suffix It's got a suffix on the end and it's just a sequential number in this example NFS So we've really concentrated on the flash away and the snapshots there, but we can do the same on NFS.
So if we got our backups being sent to the flash blade and it's also true for SMB, we can take snapshots and we can have those against the policy. So maybe we have different retention policies on our flash away and flash blade, but safe modes turned on. So we've got our backups there. We know that if we need our backups, they're sound they're good to go.
They're gonna be available. Script here to take flash blade Snapshot. This is a python example, But you could code this in anything else? Another example of taking a flash blade snapshot from inside a database. So this is really powerful from an Oracle point of view. So for my arm man backup, I can say my backup's finished.
Take a snapshot. So I know that my backup is going to persist if I've got an R man policy, which says expire my database backups after one week, you can't delete these. These are read only file systems so we can protect those. So if someone got into my database and changed my expiry to one day,
that's not going to work. They're not going to be able to delete my backups. If someone's on my database server and is hunting for my backups and said, remove all files under Mount Backup, they're not going to be able to delete them. They've dot snapshots. If someone is on my database server with their flash blade credentials,
they can't delete them either because they've got safe mode turned on. We're protected
Is your team responsible for developing scalable enterprise applications on Oracle, SQL Server, MySQL, and other databases? Are you looking for efficient approaches to protect your data? Do you wish there was a quick way to speed up database replicas for production and dev/test scenarios? Join this session to learn how storage snapshots can play a big role in delivering benefits, such as data reduction, ease of management, efficiency gains, and more.
We Also Recommend...
Personalize for Me