Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Why Traditional Storage Systems Fail to Support Big Data

3 Big Data Challenges (And How to Overcome Them)
Big data has many qualities—it’s unstructured, dynamic, and complex. But, perhaps most importantly: Big data is big. Humans and IoT sensors are producing trillions of gigabytes of data each year. But this isn’t yesterday’s data—it’s modern data, in an increasingly diverse range of formats and from an ever-broader variety of sources.
This is leading to a chasm between today’s data and yesterday’s systems. The sheer size and scale, along with its speed and complexity, is putting a new kind of stress on traditional data storage systems. Many are just plain ill-equipped, and organisations that want to make use of this goldmine of data are running into roadblocks.
Why is this happening? What are the key big data challenges to know? If you’re looking to harness the power of big data, will your storage solutions be enough to overcome them?
1. Big Data Is Too Big for Traditional Storage
Perhaps the most obvious of the big data challenges is its enormous scale. We typically measure it in petabytes (so that’s 1,024 terabytes or 1,048,576 gigabytes).
To give you an idea of how big big data can get, here’s an example: Facebook users upload at least 14.58 million photos per hour. Each photo garners interactions stored along with it, such as likes and comments. Users have “liked” at least a trillion posts, comments, and other data points.
But it’s not just tech giants like Facebook that are storing and analysing huge quantities of data. Even a small business taking a slice of social media information—for example, to see what people are saying about its brand—requires high-capacity data storage architecture.
Traditional data storage systems can, in theory, handle large amounts of data. But when tasked to deliver the efficiency and insights we need many simply can’t keep up with the demands of modern data.
The Relational Database Conundrum
Relational SQL databases are trusty, timeworn methods to house, read, and write data. But these databases can struggle to operate efficiently, even before they’ve met maximum capacity. A relational database containing large quantities of data can become slow for many reasons. For example, each time you insert a record into a relational database, the index must update itself. This operation takes longer each time the number of records increases. Inserting, updating, deleting, and performing other operations can take longer depending on the number of relationships they have to other tables.
Simply put: The more data that is in a relational database, the longer each operation takes.
Scaling Up vs. Scaling Out
It’s also possible to scale traditional data storage systems to improve performance. But because traditional data storage systems are centralized, you’re forced to scale “up” rather than “out.”
Scaling up is less resource-efficient than scaling out, as it requires you to add new systems, migrate data, and then manage the load across multiple systems. Traditional data storage architecture soon becomes too sprawling and unwieldy to manage properly.
Attempting to use traditional storage architecture for big data is doomed to fail in part because the quantity of data makes it unrealistic to scale up sufficiently. This makes scaling out the only realistic option. Using a distributed storage architecture, you can add new nodes to a cluster once you reach a given capacity—and you can do so pretty much indefinitely.
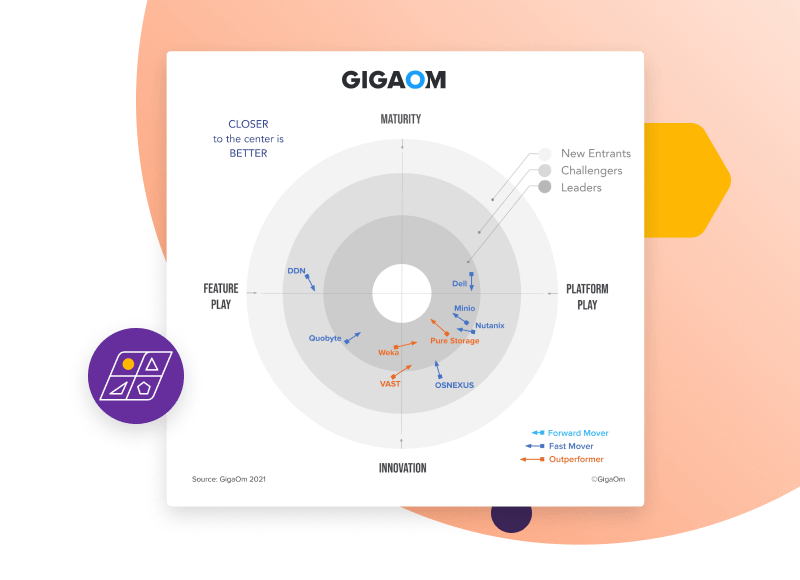
GigaOm Radar for High-Performance Object Storage
Everpure Is Positioned as a Leader in the GigaOm Radar for High-Performance Object Storage.
2. Big Data Is Too Complex for Traditional Storage
Another major challenge for traditional storage when it comes to big data? The complexity of data styles. Traditional data is “structured.” You can organize it in tables with rows and columns that bear a straightforward relation to one another.
A relational database—the type of database that stores traditional data—consists of records containing clearly defined fields. You can access this type of database using a relational database management system (RDBMS) such as MySQL, Oracle DB, or SQL Server.
A relational database can be relatively large and complex: It may consist of thousands of rows and columns. But crucially, with a relational database, you can access a piece of data by reference to its relation to another piece of data.
Big data doesn’t always fit neatly into the relational rows and columns of a traditional data storage system. It’s largely unstructured, consisting of myriad file types and often including images, videos, audio, and social media content. That’s why traditional storage solutions are unsuitable for working with big data: They can’t properly categorize it.
Modern containerized applications also create new storage challenges. For example, Kubernetes applications are more complex than traditional applications. These applications contain many parts—such as pods, volumes, and configmaps—and they require frequent updates. Traditional storage can’t offer the necessary functionality to run Kubernetes effectively.
Using a non-relational (NoSQL) database such as MongoDB, Cassandra, or Redis can allow you to gain valuable insights into complex and varied sets of unstructured data.
3. Big Data Is Too Fast for Traditional Storage
Traditional data storage systems are for steady data retention. You can add more data regularly and then perform analysis on the new data set. But big data grows almost instantaneously, and analysis often needs to occur in real time. An RDBMS isn’t designed for rapid fluctuations.
Take sensor data, for example. Internet of things (IoT) devices need to process large amounts of sensor data with minimal latency. Sensors transmit data from the “real world” at a near-constant rate. Traditional storage systems struggle to store and analyse data arriving at such a velocity.
Or, another example: cybersecurity. IT departments must inspect each packet of data arriving through a company’s firewall to check whether it contains suspicious code. Many gigabytes might be passing through the network each day. To avoid falling victim to cybercrime, analysis must occur instantaneously—storing all the data in a table until the end of the day is not an option.
The high-velocity nature of big data is not kind to traditional storage systems, which can be a root cause of project failure or unrealized ROI.
4. Big Data Challenges Require Modern Storage Solutions
Traditional storage architectures are suitable for working with structured data. But when it comes to the vast, complex, and high-velocity nature of unstructured big data, businesses must find alternative solutions to start getting the outcomes they’re looking for.
Distributed, scalable, non-relational storage systems can process large quantities of complex data in real time. This approach can help organisations overcome big data challenges with ease—and start gleaning breakthrough-driving insights.
If your storage architecture is struggling to keep up with your business needs—or if you want to gain the competitive edge of a data-mature company—upgrading to a modern storage solution capable of harnessing the power of big data may make sense.
Pure offers a range of simple, reliable storage-as-a-service (STaaS) solutions that are scalable for any size of operations and suitable for all use cases. Learn more or get started today.
Browse key resources and events

TRADESHOW
Pure Accelerate 2026
June 16-18, 2026 | Resorts World Las Vegas
Get ready for the most valuable event you’ll attend this year.

PURE360 DEMOS
Explore, learn, and experience Everpure.
Access on-demand videos and demos to see what Everpure can do.

VIDEO
Watch: The value of an Enterprise Data Cloud
Charlie Giancarlo on why managing data—not storage—is the future. Discover how a unified approach transforms enterprise IT operations.

RESOURCE
Legacy storage can’t power the future
Modern workloads demand AI-ready speed, security, and scale. Is your stack ready?
Personalize for Me