Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
47:21 Webinar
Become a Performance Hero in 3 easy steps with Database Offloading
In this session we will cover how moving non-critical tasks to a secondary server can streamline your production databases.
This webinar first aired on 2 August 2022
The first 5 minute(s) of our recorded Webinars are open; however, if you are enjoying them, we’ll ask for a little information to finish watching.
Click to View Transcript
Hello and welcome to become a performance hero in three easy steps with database offloading. Today's webinar sponsored by pure storage and produced by actual tech media. My name is scott Becker and I'm from actual tech media and I'm excited to be your moderator for this special event and before we get to today's great content, we do have a few housekeeping items that will help you get the most out of this
session first. We want this to be an informative event for you so we encourage any questions in the questions box in our webinar control panel, our expert presenters will be responding to your questions there throughout the live event. We won't have a dedicated Q and a session at the end of the presentation so be sure to type in your questions as you have them. Don't wait or you'll you'll miss the experts
now that said, we will pass along your questions to the pure team at the end of the presentation as well. So don't worry if we didn't get to your question during the live event, you may hear back later. The Q and a panel is also the place to let us know about any technical issues. You might be experiencing a browser refresh will fix most audio,
video or slide advancement issues but if that doesn't work, just let us know in the Q and A and will provide further technical assistance. Now in the handout section of your webinar control panel, you'll find that we're offering several resources. There are a few links there from pure stories that you're gonna learn more about later But
you can click on those links at any time during the presentation. Those include a link to pure platform guides for both VM ware and for Microsoft and a link to find out more about what pure is going to be up to at VM ware, explore. That's the huge annual conference that you may know by its former name of VM World. Also in the handout section,
you'll see a link to the gorilla guide book club where you can get access to actual tech, media's great printed resources on technology topics as well as a link to the A. T. M. Event center which has our calendar of upcoming events. I encourage you to access those resources now and share them with your friends and colleagues.
Now at the end of this webinar event we will be awarding a $300 amazon gift card to one lucky registrant. Of course you must be in attendance during the live event to qualify for the prize. The official terms and conditions of today's prize drawing can be found in the handout section as well. Just scroll to the bottom and you'll find the
prize terms and conditions link there. And finally one of the best benefits of this event is the opportunity to ask a question of our expert presenters and as I said, they're going to be in chat throughout our presentation today. So to help encourage your questions, we have a special additional prize for you. That's another Amazon gift card.
This one for $50 for the best question at the end of the event, we'll look at all the questions, pick up the very best one and contact that prize winner and with that let's get to today's fantastic content. It is my pleasure to introduce you to our presenters. Today we have David Stillman whose principal field solution architect of pure storage and
Andy Yoon whose field solutions architect at Pure as well. So I'm gonna turn things over to David. Welcome everybody today. We're gonna talk about how to become a performance hero in three easy steps with database offloading. My name is David Simon a principal field solutions architect here focused on our VM ware
in our cloud solutions. While working here, I've been here for about 2.5 years and I cover all of our virtualization and cloud solutions. You can find me blogging at David Simon dot com and you can also find me contributing to the community on gIT hub as well as on twitter and I'm joined today with Andy yun. Hi everyone. My name is Andy and I'm also a field solution
architect here at pure storage and while I'm still somewhat new here at Pure, I've been working with sequel server for very, very long time, both as a database developer and as a database administrator. Um I speak at conferences on a fairly regular basis and a user groups and such and you can find me fairly actively on twitter as sequel. Beck and I also do a blogger here as well.
Alright, so let's get into it. So the challenge today is talking all about our database systems, our databases are the backbone for all of our different applications and for most of us they're always under constant pressure. Right? And you know, we're trying to squeeze as much performance out of our database queries and our
database systems as we possibly can. And the thing is as we try and struggle through a lot of the crazy workloads that we are under, that makes us as admins as um, developers also pretty crazy as we're trying to juggle a lot of different things. Right? Our production servers are only finite. They only have a finite amount of resources
that we can squeeze out of them. So what about this? There are certain things that we can do with our database workloads to share the load to pass it around. Are there things that we can offload elsewhere? And many of us are doing this today in various shapes or forms. But what David and I want to show you today is
how you can leverage database offloading techniques with pure storage technologies to do this even faster and more efficiently. So, as we talked about that. Right, we're gonna be sharing the load today, especially from an agenda. So from a VM ware perspective, we have a really great way of kind of how we're gonna start this off on why Pierre is just a
great platform for these virtualized workloads and how the VCR admins and the storage or the database admins can kind of share some of those perspectives. And then also from the sequel server perspective. And he's going to kind of jump into how we can take advantage of our snapshots and overall usage to kind of refresh some of those databases and offload that somewhere else.
So let's jump in and dive in. So let's talk about why we should run virtualized solutions on pier storage. Well, first of all, the flash array is really an ideal storage platform for VM ware. Whether it's our flash array X which is our latency optimized for sub millisecond latency or whether it's our flash array C that is made for those cost sensitive tier two applications.
And so when we think about the flashlight and how it was designed, it was truly designed for uptime and performance. But also when we think about features, all of our data is encrypted at rest with a global data reduction. So this is with this is with provisioning data duplication, as well as compression, we have both automatic and mainly configured Qs and by
the fall to a fault data protection. The best part about this is you as an admin. Don't have to worry about managing software updates because they're all delivered through the cloud by our support team When we think about best practices, all of them are available out of the box. So this here is optimized for multi path thing policy, whether it's gonna be Round Robin in 6.7 or Iran Robin latency and seven dot oh.
And when you think about it, all of our boss providers and be a necessary services are native from a VM. Our perspective when we think about data store sizing or even volume size, you don't have to worry about how you size them for performance because all of our volumes don't have any per volume limits. And when we think about connectivity, we are a block platform so we support fiber channel as
well as NBE over fabrics and really from an integration point of view, from a VM ware perspective really you name it from a VM ware perspective we are going to have some sort of integration and certification whether it's the center we realize Metro storage clustering site recovery manager, Virtual volumes Horizon B B I B where cloud foundation or being where validate designs, we have ties in into each one of those.
One of the biggest reasons we have that is we're actually a technical design partner with, I mean as they are developing these solutions, we work very closely with them and that provides us the ability to have day zero support if we think about from the VM ware perspective um let's start with the center, what is the simplest way to manage it. This is how we can abstract a storage admin or anyone who may not be familiar with storage to
really have a lot of these workflows done directly through the vee senior interface. So the idea here is that you never need to log into the interface. You can just do it all from the center. So whether that is managing and provisioning a cluster of the essex coast, right click that lifter and they create host group. It'll go ahead and do all the configuration at the array level,
such as creating the group, creating the host and adding either the WWF for fiber channel or the I Q N and configuring that. And so one click don't have to worry about incorrectly copying and pasting those past the address addresses. When we think about provisioning data stores again we can simplify that. Right click the cluster, create a data store, give it a b M F s type and give it a name and a
capacity. We'll go out and do all the hard work for you. Normally when you do that manually, you would have to create a volume manual sent to the host group, then go back to your V center and re scan your host and provision the data store and apply any particular settings that you need to within this workflow is going to be a very streamlined interface and then we also have the ability to take actual storage snapshots
through our plug in as well. So we do not need to rely on those VM based snapshots but we can handle all the offloading from the array and have those granular with balls or have them be mfs based snapshots for protection. When we think about monitoring um traditionally when you're looking at your VM, you really see only what the center thinks about the data,
not what is actually happening on the back end. So from a performance graphs, we actually have three ones that we will present to you. The first one is array load, it's how busy your array is. Um we're not gonna expose CPU memory, we're gonna show you how busy it is because if you're not using their resources, we probably are on the background when we think about volume
performance, we can tell you details into the latest C I O and throughput of individual volumes what the array actually sees. We can also do this from a capacity perspective as well, which is very important because a lot of the times when you do it in provisioning d c r c's one thing and the array sees the other. So how do you know what is actually written verse provisions and then what's actually consumed and the bottom capacity breakdowns
will actually show you what it's beats fear provision. What is array provision and then what is the actual unique space that is being consumed because again we have the global data reduction and then we'll also show you some overall rate capacity graphs. But over time we keep adding more and more features to our plug in and so over time we've added additional settings for host personality
when now the requirement, we've now done additional host connectivity if you need to validate the connectivity of your host or maybe a side of data store to another cluster providing those native performance graphs instead of just embedding them. But the biggest thing that has enabled us to make even more impact is the remote architecture um prior to this VM ware had a plug in that was directly installed on the B
center but they've now moved to a remote architecture which means the plug in is installed elsewhere and beating our access it. And this has really allowed us to do a lot more development and functionality that we have done previously. So two of the latest features we did was in so we released role based access control, which really was a big ask from customers and this really provides the granularity to do
individual task if your storage seems to want to give you full rights to the array. The other big thing that we just released in version 5.1 of our plug in is the ability to do point in time, the ball recovery. So previously you can just delete or recover disk that side in the recycle bin. But this new workflow allows you to recover a virtual machine or a disk from any point in time snapshot that is currently available on
the array and then the version 5.2 of our plug in. Um actually some really great stuff coming there to in regards to the mfs point in time. So stay tuned for that. We did talk about simplicity um and really from an automation standpoint, it's in there. So security has ever always been an aPI first
and so whether it is true rest aPI is whether it's power show if you realize orchestrator, python answerable or even terraform, we have integrations for that, whether it's for fail over and fail back testing, whether it's for complex orchestration or just really desired state configuration. All of these tasks are out there but really what we're coming down to is talking about offloading and we really have many ways to do
this. Um and so when we think about our protection and our data protection, the one that we're really gonna focus on today is gonna be our local recovery snapshots, how we can use those to refresh environments but we also have the ability to tie that in with also rock aging. Maybe we're doing asynchronous replication to another rack where we're doing our synchronous replication to another rack.
We can also do our active active Metro storage clustering, which is our synchronous replication, which is a zero R P 00 R T O stretch storage clustering but we can also tie that into what we call active activating, which allows us to have high availability within the data center or across two sites but still ship those snapshots off to a third site through our asynchronous replication.
And then from our archiving perspective we have a feature on our race called offloaded Cloud snap Offload allows you to offload snapshots to any nFS target or compatible. S three target um cloud snap allows you to offload natively to S three or as your blog. And then from also a general protection, we have integrations with many backup vendors for our delta snap api technologies when we're thinking about that offloading in that
protection. Well we have the ability to do those local snapshots, those can be done as low as every five minutes. And that's gonna be what we tie in with our asynchronous periodic replication. It's the scheduled shipping of snapshots to a secondary site as low as every five minutes. The second form of this is gonna be what we call active D R which is a continuous
replication. The third option we have is synchronous replication which is that active cluster, truly stretching that storage across two sites and having a single um europeo europeo. And then like I kind of covered earlier, we have the ability to do synchronous with third site and this is very important where we have the ability to utilize those snapshots for these environments.
One of the things that's really gonna enable us to do this, offloading is when we think about virtual volumes here, storage has been doing virtual volumes for some time now and we've been very successful because when we think about b m F s, we don't have the granularity that we really need. When you think about the nfs data store, it is one volume that consists of many applications,
many different s L a many different disks, not everything you may want to refresh your downstream when you have a V ball, it's going to be a first class citizen. So a VM is gonna be the equivalent of a volume group and then the individual, this will be the individual volumes on the array, which means that when we need to do any of those refreshing of environments, we truly are gonna have granularity if we think about it
this way. A traditional example that we thought was a how did we normally do that? Well in the event here we have a physical server. Right, That was a Windows 2016 with a C drive entity drive. But traditionally to you needed some agent based solution with the granularity of virtual volumes.
What we have the ability to do is create an empty VM that is equal sized disks of those other VMS and then what we'll do is we will overwrite those volumes with either the latest copy of data on those volumes or the array snapshots and overwrite those disks. Once it's powered on that VM has now been essentially instantly virtualized. When we think about this, this is really what we're going to talk about.
When we think about offloading of those snapshots and refreshing of the environments. We have the ability to either go from a physical to a virtual, from a production to the test but we also have the ability to do from a physical or from a virtual to physical environment. And so it truly provides you the flexibility. And I'm also gonna talk about how we can also do this from a hybrid standpoint.
Maybe you have your test environment in the cloud and we'll provide you some options of what we can do there. The next one thing is insights, well we have to be realized content packs. One is gonna be for re realized log insight and one is gonna be for be realized operations manager. Both of them will provide you a lot of great
insights into what's happening, whether it's from a modern standpoint or whether it's from a log standpoint. One of the best things that's gonna help everybody, whether it's a storage admin officer, admin or the database. Admin is a tool called VM analytics. It really provides end to end visibility from a virtual to physical topology map. And so if we think about the traditional ask
well my VM running slow, everybody starts pointing their fingers not really knowing who's at fault. But with this tool we have granularity from the virtual disk to the VM to the host to the data store, to the volume to the array. And so if someone says your VM is slow. Well we can look at the latency path. Where is the latency? Is it at the disc?
Is that the host? Is it at the data store for the VM? Well if the erase sitting at sub millisecond latency like it normally is the data store. Is there the host is maybe five milliseconds but the VM is 20 milliseconds. We can see here that there's something happening at the VM or the host level becoming a bottleneck and it really provides almost the instant mean time to resolution.
The other great thing about this is just granularity from a capacity metric point of view. We have the ability to see percent used percent provision or total provisions as well as a really great metric culture but that provides us the ability to see the amount of data changing up or down in a particular environment. So you have some unexpected growth and you don't know where it came from.
Well this tool will really provides you that insight to see where that actually is. And then along that we also have a bunch of other great tools available through pier one. The first one might be our our metal workload simulation. It provides us the ability to kind of have insights into what's happening at your way. So you did have that workload and now you need to start cloning that for test of U- 80 staging
can be array supported from both the capacity and the performance. Well if the bomb is already there, what you're gonna do is say I'm now cloning this workload two or three times and it's gonna tell you what is the performance before and after that operation. What is the capacity before and after that operation? Obviously with there snapshots capacity is
probably not going to change but if there's a performance system there might be some performance overhead to that. So that's a really great store to get some insights to what that's going to happen. And then as we wrap up, let's talk about some some cloud based scalable environments for dev test and analytics. The really great part about this is our child
block store solution really enhances the cloud capabilities that are included with flattery and so traditionally when you think about cloud based storage, it's almost just dumb storage, right? You have very basic features. And so when you think about purity, we have the ability to have both your on premises and your cloud based arrays running the exact same operating system.
When we do our snapshots and clones and our replication, they're gonna be very efficient as we replicate our data up. We're only replicating unique blocks when we think about changes. Well we can instantly take those snapshots and convert them to a volumes and we can use our asynchronous replication and have it replicated as well as five minutes.
Think about one of our customers, they are originally doing this with a small data set, They're cloning it over 100 times. And so it used to take them days to weeks to be able to get this environment up and they paid for a whole bunch of storage. But now with cloud block store, they're able to get over 100 to 1 data reduction and get these environments running in minutes. So not only are they saving a whole bunch of an
infrastructure point of view, there really is a lot of time saved with these workflows and if we kind of look at it, what does it look like And this is gonna be what we're going to kind of dive into. What's gonna happen, whether we're doing this strictly on premises or whether we're doing this to the cloud, we have our flattery on premises and we're replicating Um are snapshots to a top block
store or another flash, right? Or in this case we might even be taking those snapshots locally. Well what happens? We develop our solution and another environment, we take those snapshots of those cloned data sets. We did and instantly present those volumes to our machines and so that gives us the ability whether it's a test of U- 80 stating right,
we're gonna globally duplicate that. So obviously the more clones of it the better. And so this is a really beneficial information. Alright, everyone. Now let's talk a little bit about why sequel server on pure, it's specifically we're gonna be talking about flash array. So the great thing about flash array, especially from a performance perspective is
that it brings you superior capabilities including sub millisecond latency and phenomenal throughput. One of the key differentiators though with flash array is our data reduction capabilities. All of your data on flash array is compressed and de duplicated and we see an average about 3.5 to 1 from a data reduction ratio. So imagine having that 10 terabyte database, wouldn't it be nice to be reduced down from a
capacity perspective 3.5 times. Right, That's pretty nice. Right? Variable block size is actually very, very advantageous for sequel server because sequel server behind the scenes does its i O in a number of different sizes. Right. And unlike other uh arrays that are out there, there are no storage tiers,
there's no faster than slower storage inside the array. Flash array is all flash and all fast all the time. But flattery is more than just a place to dump your data frankly, especially in my database developer days, I didn't think all about storage all that much storage was just that black box where everything kind of lived.
But the thing about flash array is that because we started as an all flash solution, we took a slightly different approach to how to do things, how to build a robust and performant storage system for you. And because of some of the early disk design decisions that we made, because we weren't tied to old paradigm, the paradigms that spinning disk were bound to,
we are able to take a different approach and do things differently to our benefit and to your benefit as well. Let's take a quick look behind the scenes. So most of us are used to having servers with a bunch of volumes on them. Right. So those volumes are presented from, you know, old school sands and our physical subsections of the sand,
you know, a certain number of disks or whatever the case may be. However, on flash array volumes are a little bit different volumes are logically defined constructs that exist in a small little corner of the flash array and it's really just a whole bunch of different pointers to the underlying data that is compressed and de duped and resides all across the entire. Flash array.
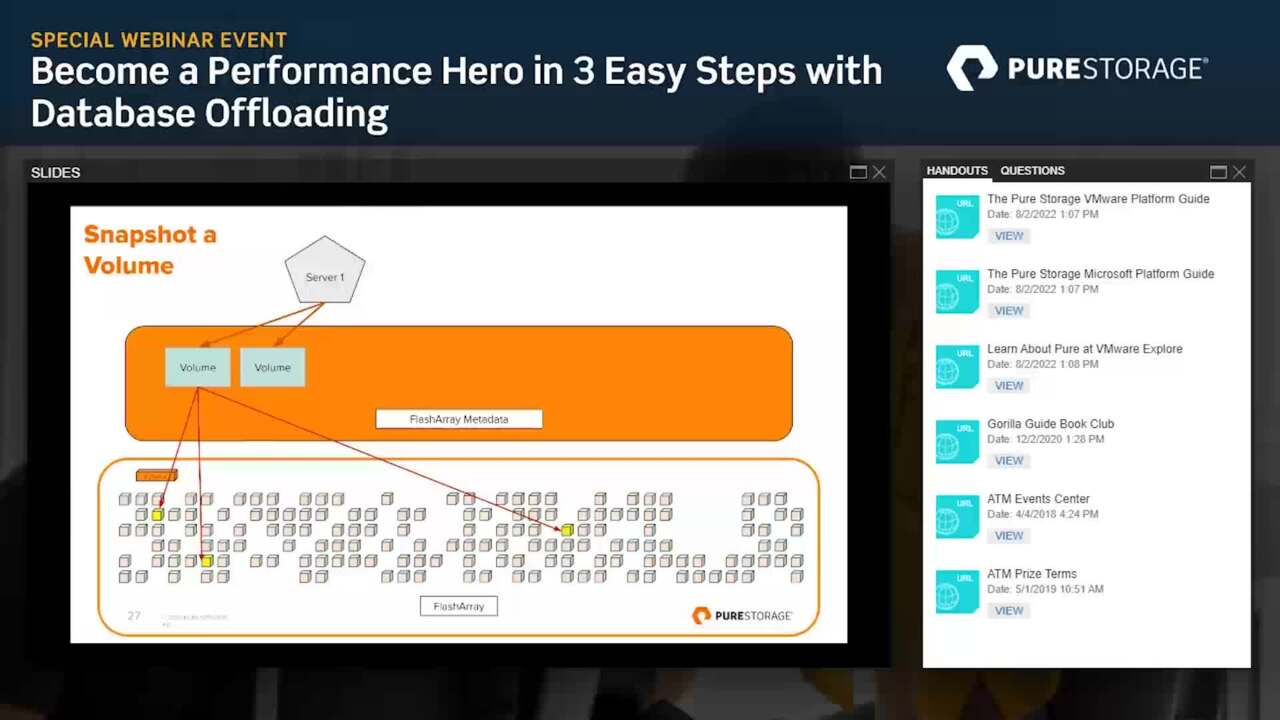
Volume is not a specific portion or corner of the flash array, it's just a whole bunch of different pointers as you can see from this diagram here. So because these volumes are logical, the benefit that it brings to us is how we do snapshots of our different volumes. So let's take a look at this visual representation here,
I have this volume and it's just pointed to three different data blocks here as simplified and generalized kind of example. Right. If I take a snapshot of that within the flash array, it's really just making a copy of those same pointers inside of metadata. I'm not copying data around on the array itself. So this is something that can be done ridiculously fast because these pointers are pretty tiny from a data size perspective.
Right. So we can do this practically instantaneously and what's even better when this is done near instantaneously, it is practically transparent to the underlying servers that the volumes are connected to. So just to refresh some key characteristics, you know, these snapshots are just a collection of pointers after all.
Now I do want to stress that there are two different types of snapshots. This is something that sometimes gets lost in the conversation. So the first type of snapshot is a crash consistent snapshot and this is the type of snapshot that I'm primarily referring to when it comes to flash rate, this is a storage level operation that is executed against the volume level or that is
the minimum kind of unit of snapshot. On the other hand, there are application consistent snapshots as well and actually these are the types of snapshots that most people are familiar with. One of the key differences between these two different types of snapshots. Is that an application consistent snapshot will stun the sequel server or whatever servers
happen to be connected to the particular volume that is being snap shotted and frankly this is one reason why a lot of folks myself included have never been big fans of snapshots. We run highly transactional systems such that a five second snapshot and a five second stun of our application systems is actual Unacceptable during their work day. Right, so we're limited to only being able to do these types of snapshots maybe in the middle
of the night, but we may even be running 24 x seven systems where we cannot even accept any kind of stunt to our servers at any point in time. On the other hand, the advantage of a crash consistent snapshot because it's just that metadata operation as you saw a moment ago. This is something that can be done instantaneously and transparent to the application servers.
You do not need to stun those servers, no stunts whatsoever. Now, the flip side however, is this from a sequel server perspective, your crash consistent snapshots are kind of like what happens when sequel server gets just arbitrarily taken offline. The databases come back any come back online and they must go through crash recovery. So transactions that are currently in flight
will get rolled back. On the other hand, with an application consistent snaps, you can bring that volume back in the subsequent database files back in a restoring mode such that you can apply transaction logs to them to give you point in time recovery capabilities. That is the one key distinct advantage of application, consistent snapshots but if your use case does not require specific
point in time recovery crash, consistent snapshots are perfectly acceptable and frankly in my opinion give you far greater flexibility. The other key detail and characteristic about these flash array snapshots is that these are independent, immutable entities. What do I mean by this? There is no lineage involved, no relationship involved between these different snapshots.
So if I have a particular volume and I take snapshots say three days in a row and I decided to delete that middle snapshot, there is no merging or reconciliation that must occur between the first and the third snapshot behind the scenes because each snapshot is a completely independent entity. So, and this is something that helps us from a performance perspective and a management perspective.
Now many of you may be wondering what happens after a snapshot is taken and we continue on with our work, why don't we continue on to modify data because that's another different um penalty or reason that many of us never care for snapshots. A lot of older systems used a copy on write methodology when taking a snapshot such that um any kind of time data gets updated than the underlying data that was being pointed to
before it gets copied elsewhere and that was a big performance hit. Flash array takes a different approach. This is called the redirect on write approach. So in this simplistic example we're gonna write some data to this volume, we're going to make some changes. So notice that what we're gonna do here is we're actually gonna remove two of the pointers to those two pieces of data that we are making
changes to. And instead we're now gonna lay down new data blocks elsewhere on the array. Hence the redirect that snapshot, on the other hand, that still has pointers to that original data. Therefore that data remains intact and will continue to remain intact as long as something is pointing to it, whether it be this snapshot or something else.
Okay, so this redirect on right approach, you know, is something that was done from a performance perspective but it brings us some additional benefits elsewhere as we'll see in a minute. So what do we do with these snapshots? Well, the obvious answer is to clone these snapshots and make copies of them and you know, present them elsewhere. So in this case I'm going to clone the snapshot
and present it as a new volume and mount it up to server two. Right, that is the most simple approach to this. Now. One other thing I want to be very clear about is that you're not constrained to working with just a single flash array, but you can take one of these snapshots at a synchronously replicated elsewhere,
say to another flash array or as David talked about earlier, the cloud using cloud block store. And then of course, once it's over on that other array, uh then you can clone that snapshot and then present that volume up to that other server. Now keep in mind one of the powerful things about our snapshots when you're doing the
asynchronous replication is that as you take subsequent snapshots and a synchronously replicate them across the wire, you're not taking full copies of the data. We're only sending across the wire. The compressed the duplicated deltas of data across the wire. Of course, the very first time you take a snapshot of a volume and then send it across the wire,
we're going to have to take a copy of everything. Right? But then again, all subsequent snapshots thereafter, even though they're independent immutable entities, we're gonna be able to do the calculations of what is true. The deltas of those snapshots and then only send those Deltas across the wire.
So you're only sending a small subset of data. And that's something that can be very, very useful um and help the performance perspective of making use of these snapshots on a frequent basis rather than just doing it like once a day or once a week. Right. Imagine doing this once every 15 minutes or five minutes or whatever the case may be. Right.
Okay. So knowing that these snapshots are portable and can be moved around and can be shared on other servers that that are fed by the same flash array or between other flash arrays and or the cloud using cloud block store. Let's pivot and think about what are the use cases with our databases where we've had to do something similar with backup files, you've had to take a copy of a backup file moved to
another server and restore. For whatever reason, this is something a lot of us db they have to spend a lot of time doing and unfortunately it's kind of that mundane time. It's wasteful time just waiting for these files to be copied around because oftentimes we do have to refresh non prod environments with copies of production.
Many of us are in the devops world. Right. So we have continuous integration pipelines that we have that we often have to work with and many of us have automated similar steps of taking a backup and putting it and restoring it to say, an integration server or something like that. But wouldn't it be really cool to do this even faster using snapshots and that's the whole point of something like this.
This is a particularly useful one. Have you ever had something blow up in production and you really need to get into it and really see what happens. What if that processes say like your nightly et elle where you're transforming a bunch of data. Well I don't want to potentially do that and, you know, try and replay that E T L process manually in production, therefore modifying data and
potentially screwing stuff up even more or something like that. Right? Wouldn't it be really awesome to take a snapshot of production immediately presented to another server and then I can iterate through my investigation, my forensics or even playing around with different hot fixed scenarios without worrying about testing these out in actual production.
Because of course we don't test in production. Right. Right. Anyway think about how you can make use of these snapshots too and to work with your data and and replace those scenarios where you traditionally had to grab a backup and restore it somewhere. So let me show you a quick visualization of how this is commonly used by many of our customers.
You can very easily take that snapshot right here of that production volume and then say overlay to QA and then overlay it to death. I wanted to show you this visualization to remind you of the fact that you're not truly making a copy of that volume, you're only copying the pointers. So you're not paying an additional capacity penalty on the flash.
Right? Because it's pointing to the same underlying data until of course you start making some modifications but typically in QA and dev another non prod environments, The the volume of delta is gonna be trivial compared to what's going on in production and of course production there's going to be a fair amount of change as well but oftentimes a lot of our data will remain static or we just append to it like an
orders table for example. Right? As opposed to maybe even you have a customer's table. Well the majority of your customers will remain static. Of course you'll append to the customers table. Right. Um So think of it from that perspective not a whole heck of a lot will change.
Typically speaking now let's take a different type of scenario, leverage snapshot portability. Many of us often times have data warehouses that are fed by from many many different servers and we use different technologies to move that data around on a say nightly basis. Things like S. S. I. S. Right?
And oftentimes those S. S. I. S. Packages will take many, many hours to run because not only is it moving data but it's also transforming it and making modifications and stuff like that. But if all of these different servers resided on one or more flash arrays or cloud block store, then think about how you can take those volumes.
Those source volumes take snapshots of those and then present those straight up to the data warehouse, you can cut out that data movement step and do it nearly instantaneously leveraging snapshots. This is something that you know, if many of us have those E. T. L. Processes that takes six hours overnight to run,
wouldn't it be kind of cool to shave off three hours of that because that three hours is just the data movement going over the wire. I now no longer have to saturate my network, moving this data around sub sets of the data. I can just present a clone of the volume straight into the data warehouse server and then the data warehouse server can just extract out what it needs and then you can drop that volume once you're done or overlay it and
replace it with a fresh clone later, you know, the next day or whatever your workflow happens to be. Here's one final interesting use case specifically for the sequel server. D B A and offloading. Wouldn't it be awesome to offload our D B C. Check DB processes because check DB is one of those things where you have to do it right? We want,
we need to be checking for corruption issues within our databases. But many of us don't have unlimited maintenance windows and the luxury of being able to run check DB whatever the heck we want, right? We oftentimes either have to do it only over um only overnight, only over the weekend. Some of us don't even have that luxury to run it on the weekend. And as their databases get larger,
check D. B takes a whole heck of a lot more time and burns down even more resources because check DB is horrifically I O intensive. Right. Well, wouldn't it be awesome to have a secondary, maybe deprecate ID throw away, you know, junk server and run? Check to be over there using a snapshot because think back a snapshot is just
pointers to the same underlying data. So wouldn't it be kind of cool to take a snapshot of your production volumes presented to that secondary junk server and run check DB from there. Now most of the time check, D B is going to be successful. So cool. You just drop that volume and then continue
moving on and just continue cycling through now on those rare occasions that check DB does fail. Yes, you absolutely still need to go back to the original production server and rerun check DB there. But hopefully that should be a very, very, very rare occurrence for you. But here's the other advantage of running check to beyond that secondary server,
I now have a copy of that corrupt data. I can use that secondary server to iterate through uh corruption mitigation solutions because some of them are data are destructive. Right? So wouldn't it be kind of cool to try out a few of those on that secondary server and if the end result is not satisfactory, if I lose data that I don't want to lose, right then I can overlay and reset using that prior
snapshot and then try again. So think of that secondary server as that sandbox to help you try and recover and correct the database corruption that happened to be found in check. DB. So that's another really awesome use case for leveraging our snapshots. So I've been talking about all these snapshots, but how fast are one of these snapshots?
Well why don't I just show you with a demo? So first of all, I happen to have two sequel servers here, sequel 1901 and sequel 1902 on 01. Right now, I'm going to run this database size check query here and we're gonna be working with this FT demo database. This is a 2.35 terabyte database.
So definitely not a teeny tiny database. Right? It's not gigantic because I've definitely seen databases that are many, many, many terabytes in size, but this is good enough for demo purposes. So for this inside FT demo, I happen to have a simplistic table called my stuff. It's just time stamps in here and then just my data, March are in here and I'm just going to
insert some fresh data just so you can see that, hey, you know, I'm doing something brand new in here and then I'm gonna run a simple query against the my stuff table. Uh and this way we'll be able to see the number of records and this is the server that we're on and here's our fresh time stamp. Okay, Now let me jump over to uh sequel 1902 and then
rerun that same query over there. You know, I have the server name in here just to show you that I'm on the other server, making sure that you see I have no tricks up my sleeve and here's the number of records that happened to be there. And the time sample we see that this is from earlier today. So you know, nothing has been synchronized or anything like that.
So let's show you exactly how to do all of this and for this, I'm gonna be using power show which many of us D B A is like these days to help us automate this process. And there's many other options because essentially it's all just calling out to arrest a P. I. So there's a number of different other options
that you happen to have if you want to manipulate uh these different snapshots. So the first handful of lines I'm running here are just to connect up to the target server which is sequel 1902 or this I. P address, I gotta pass in my credentials of course and then I'm going to import our our power shell module and start a power shell session here. So scrolling down a little bit, I do have to
offline the database and offline the underlying volume on the target server. We don't have to affect the source server at all. But on the target because this is a volume level operation, the database must be set offline and the underlying volume. So that's what's gonna be happening here with these couple of lines so that takes,
you know, just a few seconds at most. And then on line 32 we're now going to connect into the flash array itself. Just gonna pass in a password here interactively. But of course you can set this up to be programmatic passing credentials and that sort of thing. Now, line 37 here that I'm about to highlight
is where the magic happens. This specific command is going to target sequel 1902 and this specific volume two X drive in this case. Um and then we're going to use as a source sequel 1901, the X drive over here. Now this particular volume by by the way happens to have both the data and the transaction log files residing on the same
volume. I've just simplified that for demo purposes but of course is variations where you can, you know, cause many of us dbs will have our data volumes. Yeah, our data files on separate volumes versus our log files on separate volumes. Right. So you can absolutely do that. And this overwrite flag back here. What's gonna happen behind the scenes with this?
Overwrite, is that flash is going to take a fresh snapshot immediately and then overlay the volume the the sequel 1902 volume using the source. So everything in this specific example is just gonna happen right in this one command and we're done now, all I have to do is re online the volume and then re online the database and we are finished. And had I not talked through all of that,
that would have probably taken what five, maybe 10 seconds at most. And a lot of that is just a power shell set up and such. So let's go back to sequel 19 0 to rerun our diagnostic command here and we see that the data that we had inserted a few minutes ago is now present here. So 11 77 30. Jump back to sequel.
Uh oh 1 11 77 30. So again, you see, no tricks up my sleeve. I've now overlaid and essentially quote unquote, copied that 2.35 terabytes worth of data. And I use copy very, very loosely in here because again, you remember from the diagrams earlier, we didn't actually copy any data. We just uh took a crash,
consistent snapshot and just copied a bunch of pointers behind the scenes. Hence near instantaneous. But this is how fast you can make those data movement uh you know, copies of your data, can I have to use the word copy? I can't think of a better synonym, but you know, you get what I'm saying here right, I'm able to do this near instantaneously and I'm not making a true copy of the data.
So I'm not paying the capacity penalty of another couple of terabytes behind the scenes. All right. So with that let's jump back to the slides and let's wrap this up, David thanks Andy so a really great way to keep up to date is checking out our platform guides. We have a bunch of them, but the two that we're going to point you to today are VM ware platform guide and our
Microsoft platform died. Both of them will always keep you up to date with what's happening as well as details. Walk throughs, videos and KB articles on how all of these solutions were. Also don't forget to join peer storage at PM we're explorers, we're working together to kind of um complicate data services and so on,
august 29th to september 1st will be there in SAN Francisco. So take a look at this QR code and scan it to learn more about what Pierre is doing at the em world. Thank you very much for joining the southern are and have a great day. Okay, thanks David Nandi, really nice presentation, appreciate those diagrams on,
on volumes and snapshots in flash arrays. Those were really clarifying. Um, it was an impressive demo to now. We've we've got a poll question up for everybody. This is what additional information would you like about the pure storage solution, you can see all kinds of options there, including data sheets, white papers, case studies, um and more.
So I'll just leave that up here for a couple of minutes as, as we wrap up and and you can hopefully leave everybody enough time to fill that out um and while I leave that pole up there, uh, to give you time to answer, I just want to offer one more reminder about the links that David and Andy showed you the platform guides for VM ware and for Microsoft as well as details about purist plans for VM
ware explorer, um you know, in case you, you missed those links or you know, if you wanted uh the VM VM ware explore link and maybe didn't get your phone out in time for for the, the code there, you can grab those links from your handout section, so be sure and do that before we wrap up,
okay, And now, um we do have one more piece of business, it's the $300 amazon gift card, prize drawing and the winner of that gift card is Vidya Ranga swami from Georgia. So congratulations to Vidya, will be in touch to get you your card and with that on behalf of the actual tech media team, I want to thank peer storage for making this
event possible and thanks as always for attending and for your great questions that concludes today's event, have a great rest of your day

David Stamen
Technical Strategy Director, Cloud, Everpure

Andy Yun
Consulting Field Solutions Architect, Everpure
In this session we will cover how moving non-critical tasks to a secondary server can streamline your production databases. By moving tasks such as periodic reporting, test & development, and more, production workloads are given the resources they require.
We will show you how to use FlashArray's native replication, coupled with automation, and even VMware Virtual Volumes (vVols) to relocate less critical tasks. Some use cases include reducing report generation times by optimizing ETL workflows, providing one or more point in time copies of data for reporting or quality assurance, and even the ability to perform database health checks without impacting production workloads.
Attend this session to learn the 3 things you need to know to become a performance hero!

Test Drive FlashArray
Experience how Everpure dramatically simplifies block and file in a self service environment.
We Also Recommend...
Personalize for Me