Une passerelle edge connecte la périphérie à un cloud ou à un datacenter d’entreprise, assure la traduction entre différents protocoles de réseau et gère le flux de données pour garantir l’envoi de données optimisées uniquement.
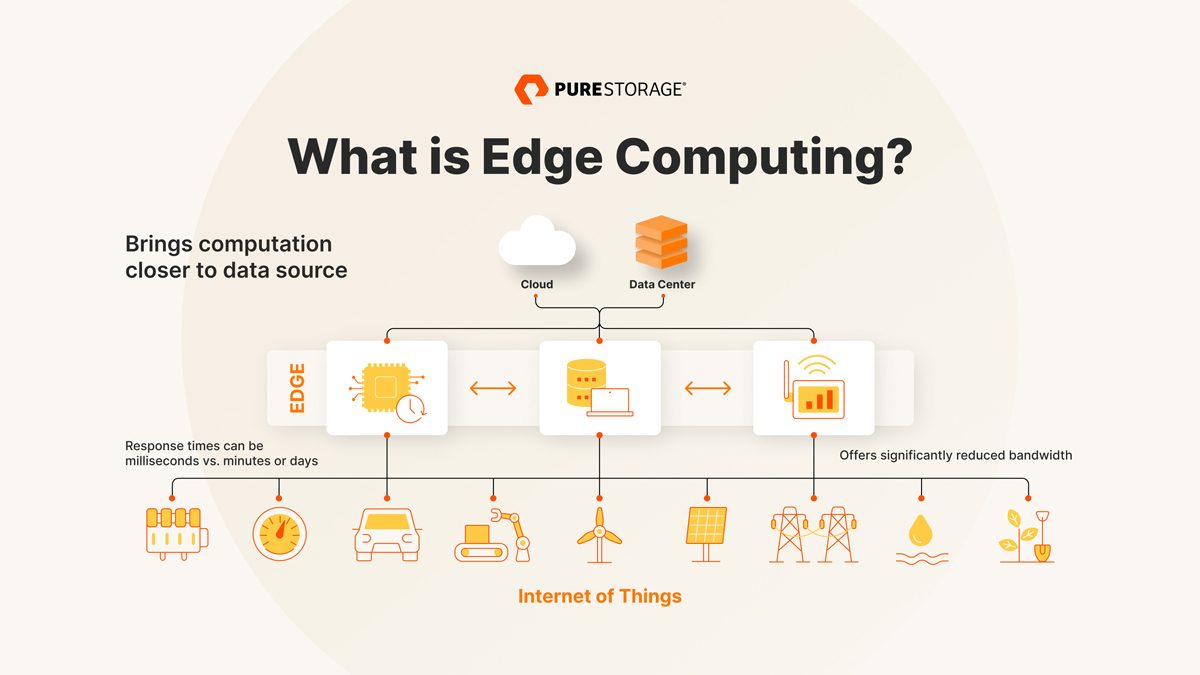
L’infrastructure de périphérie peut inclure des serveurs, un stockage et des passerelles de périphérie, des appareils IoT, des capteurs, des postes de travail, des ordinateurs portables, des appareils intelligents et du matériel pour assurer la collecte et le traitement des données en temps réel.
Stockage de périphérie
Elle peut également inclure des datacenters secondaires plus petits, situés dans des villes ou des zones rurales proches, ou des conteneurs cloud pouvant être déplacés d’un environnement et d’un système cloud à l’autre. Si nécessaire, l’infrastructure est déployée dans des boîtiers destinés à la protéger contre les températures extrêmes et d’autres conditions environnementales.
Les types d’informatique de périphérie
Voici trois types spécifiques d’edge computing :
Périphérie de capteurs
Les capteurs de périphérie servent de déclencheurs pour la collecte de données ou la surveillance et l’envoi d’événements. Ces capteurs sont optimisés pour un usage spécifique, avec une fonctionnalité de base intégrée. Ils ont généralement peu ou pas de capacité de traitement et ne peuvent communiquer qu’avec le réseau de périphérie, le cloud ou le datacenter. Les horloges, les caméras de surveillance, les contrôleurs industriels et les bases de données de séries chronologiques en sont des exemples.
Périphérie d’appareils
Les appareils de périphérie se trouvent en bout de réseau et leur puissance, leurs capacités de calcul et leurs fonctionnalités de stockage sont généralement limitées. Ils dépendent d’une passerelle pour collecter et traiter les données et se trouvent généralement à proximité des ressources informatiques afin de réduire la latence, les besoins en bande passante et les problèmes de communication. La périphérie d’appareils est souvent utilisée dans des endroits éloignés où un datacenter n’est pas envisageable (dans les éoliennes, sur les plateformes pétrolières et dans les lieux soumis à des conditions météorologiques extrêmes, par exemple).
Périphérie mobile
Les services mobiles sont distribués sur des réseaux positionnés à proximité du client pour un fonctionnement optimal. L’informatique de périphérie mobile (MEC), ou informatique de périphérie multi-accès, est un réseau hautement distribué qui se situe à l’extrémité du réseau et qui permet d’intégrer des ressources de calcul, de stockage et de mise en réseau dans les stations de base afin de déployer des applications et des services plus près des utilisateurs mobiles.
Les fournisseurs de services peuvent ainsi déplacer les charges de travail du cloud vers les serveurs locaux pour offrir une meilleure expérience aux utilisateurs et réduire la latence et la congestion du réseau.
Les avantages de l’informatique de périphérie
L’informatique de périphérie offre divers avantages aux entreprises qui dépendent d’applications soumises à des contraintes de temps ou qui doivent déplacer de grandes quantités de données. Voici les principaux :
Une meilleure résilience : une plateforme de périphérie permet d’assurer des services plus rapides, cohérents et fiables. La puissance de calcul étant locale, les sites en périphérie peuvent continuer à fonctionner de manière indépendante si le datacenter central tombe en panne.
Une latence réduite : la mise à disposition des données en temps réel est essentielle pour des technologies telles que les appareils médicaux IoT et les véhicules autonomes, où le moindre retard peut coûter des vies. La surcharge du réseau et les pannes peuvent ralentir la transmission des données, réduisant ainsi la capacité d’un système à réagir en temps réel, ce qui retarde l’analytique et la prise de décision. Grâce à l’informatique de périphérie, les données critiques peuvent être traitées plus près de l’appareil, pour une réponse plus rapide.
Une utilisation réduite de la bande passante : les réseaux disposent d’une bande passante limitée, qui détermine le volume de données pouvant être transféré et le nombre d’appareils pouvant communiquer sur le réseau. L’augmentation de la bande passante pour accueillir davantage d’appareils et de données entraîne des coûts nettement plus élevés. Au lieu de diffuser des données en continu et de consommer de grandes quantités de bande passante, l’edge computing traite et transmet uniquement les données les plus importantes au datacenter.
Une sécurité et une souveraineté accrues : lors du transfert de données au-delà des frontières internationales et régionales, la sécurité, la protection de la vie privée et d’autres considérations légales doivent être prises en compte. Le traitement des données à la périphérie permet de mettre en œuvre des mesures visant à sécuriser et à masquer les données avant de les envoyer vers le cloud ou le datacenter, qui peuvent être régis par différentes lois sur la sécurité des données.
Des coûts réduits : le coût de mise en œuvre des solutions de périphérie est souvent inférieur à celui des datacenter centralisés, que ce soit dans le cloud ou sur site. L’informatique de périphérie permet également de réduire les coûts de connectivité en déplaçant de plus petites quantités de données entre la périphérie et les datacenters.
Cas d’utilisation de l’informatique de périphérie
L’edge computing est de plus en plus utilisé dans plusieurs secteurs, notamment les télécommunications, la fabrication, les transports et les services publics. Voici les principaux cas d’utilisation :
Fabrication : grâce à la surveillance conditionnelle, les fabricants peuvent effectuer des travaux de maintenance en fonction de l’état réel des machines, tandis que la maintenance prédictive permet de détecter les défaillances de manière proactive et d’effectuer l’entretien avant une panne éventuelle.
La surveillance et le contrôle précis permettent aux fabricants d’utiliser des données provenant de plusieurs systèmes, processus et machines afin de surveiller les erreurs de production et de fournir des informations stratégiques en temps réel pour améliorer les processus de fabrication et la qualité.
Agriculture : les agriculteurs s’appuient sur la technologie edge pour suivre l’utilisation de l’eau, distribuer les bonnes quantités d’engrais, étudier la qualité du sol et surveiller l’évolution des cultures dans les champs isolés. Ils peuvent également collecter et analyser les données provenant d’un large éventail d’appareils connectés, notamment des capteurs et des tracteurs, afin d’observer les effets sur l’environnement et d’améliorer les pratiques agricoles.
Santé : le secteur de la santé collecte d’énormes quantités de données sur les patients à partir des moniteurs, capteurs et autres dispositifs médicaux. L’informatique de périphérie IoT permet de recueillir et d’analyser les données critiques des patients, ainsi que d’appliquer l’automatisation et l’apprentissage automatique pour identifier les anomalies. Les professionnels de santé ont ainsi accès à des analyses en temps réel, ce qui leur permet de prendre des mesures immédiates pour le diagnostic et le traitement.
Transports : les véhicules autonomes doivent analyser les données en temps réel pour fonctionner de manière sûre et efficace, l’envoi des données à un datacenter distant n’est donc pas envisageable. Les véhicules doivent agréger et traiter d’énormes quantités de données provenant de sources multiples pour prendre des décisions en temps réel concernant la navigation et communiquer avec d’autres véhicules, tout en étant en mouvement.
La technologie de périphérie embarquée permet aux véhicules autonomes d’analyser en temps réel la localisation, la vitesse et d’autres données relatives au véhicule afin de déterminer les meilleurs itinéraires et d’éviter les embouteillages.
Réalité augmentée (RA) : les applications de réalité augmentée pour le commerce, l’éducation et le divertissement impliquent des opérations de rendu intenses qui nécessitent des réponses en temps réel et une faible latence pour fonctionner efficacement. Les expériences de RA fournies via des services informatiques centralisés peuvent entraîner des coûts élevés de bande passante et être soumises à une forte latence, ce qui nuit à l’expérience utilisateur.
L’informatique de périphérie 5G, qui combine l’informatique de périphérie et la connectivité 5G, peut offrir une connectivité plus rapide et plus fiable pour les applications de RA. Elle peut également répartir le traitement de la charge de travail entre l’appareil de RA et le réseau de périphérie afin d’assurer une expérience utilisateur optimale.
Avec Pure, relevez les défis de l’informatique de périphérie
La mise en œuvre d’une solution de périphérie peut présenter plusieurs défis. Les solutions de périphérie étant conçues pour répondre à un objectif spécifique, elles utilisent des ressources et des capacités limitées.
Pour que votre solution de périphérie soit efficace, son périmètre et ses objectifs doivent être clairement définis. Vous devez également déterminer le niveau minimal de connectivité nécessaire, définir les cycles de vie des données et mettre en œuvre un plan de sécurité global.
Pour vous aider à relever les défis relatifs à l’informatique de périphérie, Pure Storage® vous propose plusieurs solutions, notamment :
En raison de leur haute densité, de leur faible consommation d’énergie et de leur gestion facile à distance, FlashBlade et FlashArray conviennent parfaitement aux déploiements en périphérie.
Portworx® : fournit une couche de stockage pour l’exécution de charges de travail cloud native en périphérie. La plateforme offre une solution complète pour les charges de travail conteneurisées, avec sauvegarde et reprise après sinistre. Portworx s’intègre à FlashBlade et FlashArray pour une performance et une fiabilité élevées.