Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
The Beginners Guide to Big Data
Structured Data vs. Unstructured Data
Over the last decade, our definition and understanding of what data is has changed dramatically—driven in part by the growing availability of new tools to read, store, and analyse unstructured data.
In the past, unstructured data often went underutilized, given the difficulty associated with interpreting it. These new technologies have made it easier to not only understand unstructured data but also mine valuable insights from this treasure trove of information.
According to IDC, the total volume of data created, captured, copied, and consumed worldwide by 2024 will cross 149 zettabytes every year—and much of it will be unstructured. Every organisation will benefit from building unstructured data analysis capabilities. The first step on this path is simply understanding what is structured data vs. unstructured data.
Here’s a quick summary of the difference between the two, with more in-depth explanations to follow:
|
Characteristic |
Structured Data |
Unstructured Data |
|
Nature of data |
Usually quantitative |
Usually qualitative |
|
Data model |
Pre-defined; once it is defined and some data stored, it is difficult to change the model |
No particular schema is involved in unstructured data; the data model is very flexible |
|
Data format |
A limited number of data formats are available |
A huge variety of data formats are available for unstructured data |
|
Database |
SQL-based relational databases are used |
NoSQL databases with no specific schema are used |
|
Search |
Very easy to search and find data within the database or data set |
Very difficult to search for particular data due to its unstructured nature |
|
Analysis |
Very easy to analyse, given the quantitative nature of data |
Very difficult to analyse, even with existing software tools |
|
Storage method |
Data warehouses are used for structured data |
Data lakes are used to store unstructured data |
What Is Structured Data?
Structured data has a well-defined schema for the information it holds. To give an extremely simple definition, any data that can be presented in a spreadsheet program like Google Sheets or Microsoft Excel is structured data.
In this example, data can be represented as rows and columns. Each column represents a different attribute, while each row will have the data associated with the attribute for a single instance. Rows and columns form a table that can be referenced easily.
Different tables can be connected—that is, they can be said to be related by the common column present in both tables.
If multiple tables are related in succession and combination, this creates a relational database. For instance, the customer, sales, and inventory data of a department store can be considered structured data stored as a relational database.
- Each customer will have a customer ID, as well as fields for their name, contact number, credit card information, address, etc.
- The database of customers can be connected to the database of sales, with attributes including the time of purchase, item codes purchased, total amount spent, customer ID, etc. Both the tables will be connected with the common attribute of customer ID.
- Finally, the sales database can be connected to the database of inventory using the common attribute of item code, effectively interconnecting all three tables into a relational database.
Structured data like this is generally stored in relational database management systems (RDBMSes). Databases can be written, read, and manipulated using Structured Query Language (SQL), a language that was developed by IBM in the 1970s to support its mainframe databases (though it was initially known as Sequence English Query Language or SEQUEL). It was so named since it reads pretty much like the English language. SQL in its current form was popularized by Relational Software, Inc. (now called Oracle).
What Is Unstructured Data?
Every piece of data that is not structured data can be classified as unstructured data. It’s estimated that by 2025, 80% of the data we encounter will be unstructured data in the form of text, audio, image, or video1.
In short, unstructured data is modern data. It’s often:
- Born digital and unpredictable
- Always being created and on the move
- Blended, multimodal, and interoperable
- Geo-distributed for better protection
Unstructured data can have some associated metadata that can, in turn, have a structure. For example, a video can have metadata of video resolution, bit rate, frames per second (FPS), owner of the video, etc. But the video itself is unstructured. When there’s some structured metadata associated with unstructured data, it’s occasionally referred to as semi-structured data.
Looking more closely at the example of a YouTube video, some metadata is present, such as the time of upload, date of upload, number of views (partial or full), number of likes and dislikes, etc. But the content inside the video title, the video description, and the video itself is unstructured. It has a qualitative aspect that cannot be captured purely by numbers.
The most commonly used database for unstructured data is NoSQL. NoSQL stands for “not only SQL,” indicating that the database can handle a wider range of data beyond the capabilities of SQL databases. There’s no schema or tabular structure for NoSQL databases; it’s just a collection of data grouped together.
Unstructured Data Storage with UFFO
That said, although unstructured data may be able to provide significant insight with huge transformative potential, there are challenges with wrangling it. Pure’s advanced UFFO storage solution, Everpure FlashBlade®, offers the speed associated with flash storage technology, as well as the ability to scale any architecture in an agile fashion. Want to take a closer look? Pure offers a free trial for Pure FlashBlade so that you can test drive the solution with no commitment.
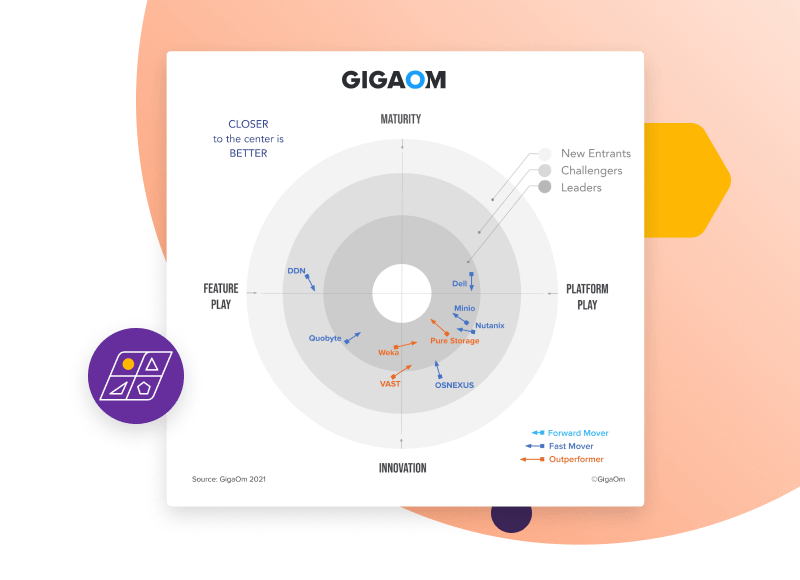
GigaOm Radar for High-Performance Object Storage
Everpure Is Positioned as a Leader in the GigaOm Radar for High-Performance Object Storage.
Related Products and Solutions
1https://www.cio.com/article/3406806/ai-unleashes-the-power-of-unstructured-data.html
We Also Recommend...
Browse key resources and events

TRADESHOW
Pure Accelerate 2026
June 16-18, 2026 | Resorts World Las Vegas
Get ready for the most valuable event you’ll attend this year.

PURE360 DEMOS
Explore, learn, and experience Everpure.
Access on-demand videos and demos to see what Everpure can do.

VIDEO
Watch: The value of an Enterprise Data Cloud
Charlie Giancarlo on why managing data—not storage—is the future. Discover how a unified approach transforms enterprise IT operations.

BLOG
What’s in a Net Promoter Score?
For nine consecutive years, Everpure has maintained a Net Promoter Score of over 80. Find out how we did it and what it means for our customers.
Personalize for Me