現代化智慧時代的全新儲存架構
給儲存產業的一封信
以數據分析和人工智慧為基礎而建立的現代化智慧時代,為儲存產業帶來了獨特的新契機。資料是全新的貨幣,而我們的契機就是成為該貨幣的守護者。過去,我們一直阻礙著企業在資料應用上的進步。一些老舊的架構,例如:資料穀倉(data silo)與資料湖泊(data lake),其設計目的都是為了將資料鎖在某個地方,因此無法做到能讓資料完整發揮價值的一項重要工作,也就是:分享。
資料湖泊已日薄西山,它建立在一個過氣的假設之上,也就是所有非結構化資料都必須保存。在這「後資料湖泊時代」,我們需要一套新的儲存標準。現代化智慧需要一套不單只為儲存資料而設計的架構,還要能夠分享和傳送資料。我們稱此全新架構為資料中樞(Data Hub)。
資料應該發揮作用的重要性不難理解。根據百度(Baidu)最近所做的一份研究顯示,其資料集(dataset)必須成長1,000萬倍才能將其語言模型的錯誤率從4.5% 下降至3.4%[1]。換句話說,要1,000萬倍以上的資料才能產生1% 的進步。美國史丹福大學一位人工智慧領域的傑出專家Andrew Ng教授指出:「資料(而非軟體)是許多企業能夠防守的邊界(競爭優勢)」[2],但企業必須「整合其資料倉儲」[3]。
這項針對資料整合的重大呼籲點出問題的核心。資料全都卡在各種錯綜複雜的穀倉當中,而儲存產業要負大部分的責任。當一個產業全心全意都在開發「儲存」的技術時,自然而然地造就了許多資料穀倉,形成了資料孤島。然而在今日資料優先的世界裡,資料穀倉反而會降低生產力,因為那些可分析洞見並推動創新的現代化應用程式無法取得所需的資料。
因此,該是重新思考儲存架構的時候了。資料中樞的基本設計原則就是不僅要能儲存資料,還要能夠整合並傳送資料。整合資料意味著同樣的資料可以讓多個應用程式在同一時間存取,而且不失資料一致性。傳送資料意味著每個應用程式在存取資料時都能獲得它所需的完整效能,以跟上今日企業的腳步。資料中樞打破了傳統基礎架構的資料孤島,所有應用程式不再擁有自己的資料穀倉,也不再需要複製資料集。
資料中樞是一種資料導向的儲存架構,是數據分析與人工智慧的基礎。其架構建立在四項基本特性之上:
● 高速的檔案及物件儲存吞吐量。
● 原生向外擴充的設計。
● 滿足多重需求的效能。
● 大規模平行架構。
現代數據分析領域當中有四大資料穀倉:資料倉儲、資料湖泊、串流分析與人工智慧叢集。資料倉儲需要龐大的吞吐量。資料湖泊需要能夠向外擴充的儲存架構。串流分析已超越了資料湖泊的批次作業,儲存必須提供滿足多重需求的效能,不論資料的規模大小與I/O類型(隨機或循序存取)。至於由數以萬計的GPU核心所構成的人工智慧叢集所需要的儲存,不僅要提供大規模的平行作業來服務數以千計的用戶端與數十億個物件,而且不能出現資料瓶頸。
最後還有雲端,應用程式正逐漸朝雲端原生邁進,並且建立在基礎架構分散且儲存無限的假設之上。雲端儲存的基本標準是物件。
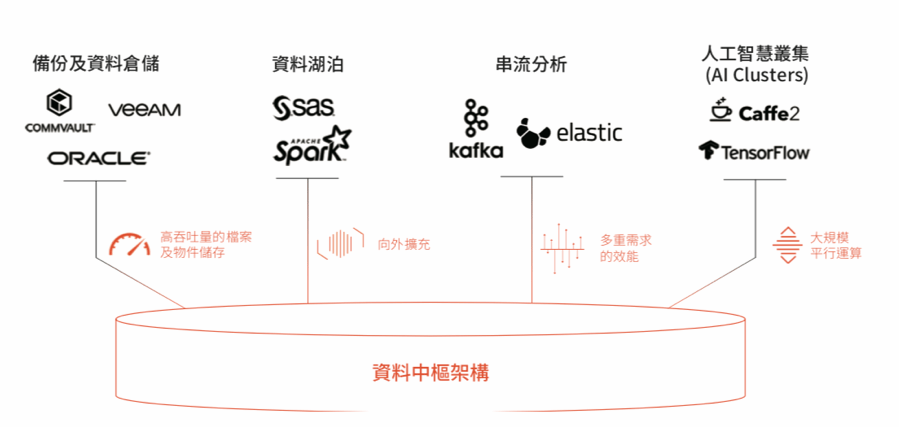
所以,資料中樞必須上述四項特性兼備,因為所有特性都是資料整合所必需。資料中樞或許還具備其他特性,例如快照和複製,但如果前述四項特性有任何一項缺乏,那這個儲存平台就不是為今日的挑戰與明日的發展性而打造。例如,如果某個儲存系統能夠提供高吞吐量的檔案存取,且原生具備向外擴充能力,但卻需要另一套系統來提供S3物件支援以滿足雲端原生工作負載的需求,那麼資料整合就會破功,資料的速度也會緩慢,這就無法擔任資料中樞。
1 Deep Learning Scaling is Predictable, Empirically(深度學習規模擴充在實務經驗上是可預期的): https://arxiv.org/pdf/1712.00409.pdf
2 https://hbr.org/2016/11/what-artificial-intelligence-can-and-cant-do-right-now
3 Nuts and Bolts of Applying Deep Learning, https://www.youtube.com/watch?reload=9&v=5PrvLq6_xm8