Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
38:43 Webinar
Bridging the Gap: Empowering Infrastructure Technologists for Cloud Success
Learn how to bridge skills from on-premises to cloud. Build a roadmap to help infrastructure pros succeed in cloud operations.
This webinar first aired on June 18, 2025
The first 5 minute(s) of our recorded Webinars are open; however, if you are enjoying them, we’ll ask for a little information to finish watching.
Click to View Transcript
Welcome. First of all, thank you for being here. How many of you saw the keynote yesterday? Show of hands. Oh, look at that. Everybody was there. OK, fantastic. I'm not gonna ask you if you stayed the whole time. But if you were there yesterday, you actually
heard Charlie talk about the Enterprise data cloud, and what we're going to show you here today is what that looks like in real life. Now, first of all, you'll see a picture of an engine here on the screen and you're probably like, well, what does that have to do with cloud? Um, I, you know, I'm from Detroit, so I, uh, my mind always goes to automotive whenever I think
of an analogy, but there's actually a lot of commonalities between the automotive industry and IT. First off, there's automation. Think about the assembly lines becoming more and more automated or scripting in IT. Then there's AI, of course it's not a tech conference if we don't say AI, but you know we can digital assistants in the cars and you could use an AI co-pilot to help
you code. Uh, there are all sorts of things like becoming more software defined, that is becoming a thing, making things simple, making things efficient, and also these are all properties of cloud. So why does this matter? It matters because cloud operations really isn't just a,
you know, the the tech, it really is people and process, and your skills are really invaluable when it comes to this journey. So we're going to take you through what a cloud operations framework looks like and how to get there. So we're going to start with some introductions. My name is Valerie Harrison. I'm a principal technologist here at Pure
Storage. I spent about 4 years prior at Google Cloud. In fact, my, my 1 year anniversary at Pure was a couple of days ago, so if anyone wants to get a confetti cannon out, you know, that'd be awesome. Uh, but I did Google Cloud and before that I was at Dell and EMC working on their storage platforms.
Ken. Hi everyone. My name is Ken Hoy, and I am a principal field solutions architect here at Pure. I specialize in unstructured data, which means file an object. So we're helping customers with their file and object needs. Uh, prior to joining Pure, I spent 5 years at AWS as a solutions architect.
Uh, and overall I've been in the IT industry for 30 years doing various things including clean cleaning people's, uh, dirty laptops, so many years ago. Hi, I'm Roger Money. I'm uh the storage service director. I, I prefer to use the term storage service owner, but our organization wants to have that hierarchy. Um, I've been at Ford Motor Company or working
at Ford Motor Company probably about 30 years now. Um, I've been an employee for about 15 and in the storage area in about 10. Uh, my role is a global responsibility, responsible for file block, object storage, as well as data protection, the, the backup and restore aspect. doesn't include mainframe or HPC, not just yet anyway, so never know.
Awesome, thanks. So first off, I'd like to start with coming to a common definition of cloud. When I was at Google, I swear every single day I would say something like cloud is not a zip code, it's not a destination, it's an operating model. And so this operating model actually has some definitions.
This is the NT definition. First off, it is an on-demand self-service model, which means that end users, lines of business, developers can get what they want when they want it without having to go through a ticketing system. Next is broad network access, so the ability to get your apps and data to where the users are.
Then resource pooling, think multi-tenancy. VMware I was an early adopter of VMware, so that's the idea of taking discrete resources and putting multiple workloads on them so that you can become more efficient. Rapid elasticity, scaling up fast when the business demands or the workload demands, scaling back down when it's not needed anymore.
And then of course, a measured service. So having the observability to get metrics out of it, performance capacity, what have you. So you have the opportunity to do things like chargeback or show back, or my personal favorite, shame back.
Bad VMware admin. All right, so we're gonna turn it over to Roger and he's gonna talk about why Ford created their storage cloud. OK. Anyone in the room not experienced this at some point in their career? I've been on both the receiving end as well as the giving end or or not giving and as as uh
some of my customers might think. Um, yes, I mean, this is something that we've all observed, it's all experienced, and it's just something that isn't conducive to business. Um, it's something that we were worried about, um, 10 years ago, 8 years ago, and when we started this journey 8 years ago,
we really had to think differently. Um, I think there are two catalysts for us. One, a customer came to us asking for about 500 terabytes. I said that was about 8 years ago. And we're like, wow, I don't have that capacity on on the floor. Give me a minute, let me check to see what we can do and then in about 7 or 8 months later
they got their storage, uh, and that was quick, um, and so for, for us, um, but no, the reality was the customer took another 2.5 years to actually use that, um, they themselves didn't know, uh, what they were doing in terms of forecasting. Um, and so it was just a lot of waste that we injected into the system and from our, from our customer perspective.
Second one that um was even more alarming is we were looking at uh creating or establishing enterprise data centers, EDCs, not the enterprise standard cloud, but we're, we're getting there. Um, and those were ground up buildings designed to be data centers versus buildings that became data centers. Um, and so with that at the time,
we had probably about 180 racks worth of storage hardware, including fiber channel networks, so all the different gear that we had, and that was spread across two buildings, so about 90 racks each. Um, when we were doing the, the sizing and the forecasting, I think we had about 25 petabytes on, on the floor at the time.
Um, we did all the sizing, put forward our forecasting. And then one of the final meetings, the, the, uh, the, the designer for the data center said, got some great news we've given, we've managed to secure 88 racks for you. I think, well, 2 less than what I've got now, that isn't too bad.
And then no 88 racks in total, and it doesn't fit. So I'll cover how we managed to tackle that challenge, uh, later. Awesome Valerie, thank you. All right, so we're gonna continue this automotive analogy because I, I can't help it. Uh, this is an internal combustion engine,
or as we call it ice. Uh, we have been building cars like this for over 100 years, but what's different now is that we're moving away from manual linkages into everything being controlled by electronics, and I feel like this is a great analogy to the on-premise data center. We've been doing that for years, but we're
moving into more automation orchestration. And more less manual tasks. I've been an EV owner for about probably over 10 years now. I actually have 3 of them in my driveway because I have teens that are driving, you know, that's terrifying, and you can take a like a,
you know, electric motor and put it in an old timey car, but you probably won't have very good outcomes. It'll look cool, but it won't work the way you expect. So with EVs you had to redesign the entire car to take advantage of the electric motor, and I feel like cloud is the same way. It's a new way of doing things that are built
for new workloads. And then of course hybrid. I started out with a hybrid car that's really the best of both worlds where you start to have the opportunity to put things where it makes the most sense and get the most value. Now why does this matter?
Because all of these, no matter where you're running or how you're running, should have a common operating model automation, orchestration, observability and governance across them no matter where you are. So which cloud is best? All of them, they're all best depending on your need.
So private cloud, uh, you know, there's a lot of companies I work with that have very great security concerns. They don't really want to go to the public cloud. They may have foundational apps. I, I'm trying to make this word happen like make fetch happen. Uh, like, I don't like the word legacy because it sounds old,
uh, but your foundational apps like your ERP that keep your business running may be very latency sensitive. Those workloads don't tend to work very well on the cloud and the public cloud. For public cloud, you get that rapid scalability, elasticity, great for Greenfield modern apps, maybe, um, startups who don't want to have a capital
outlay, and then have that global reach like content delivery networks that get that data to where the customers are. Then your hybrid cloud, which is the best of both worlds, putting the apps and data where they make the most sense. There are definitely downsides to each of these, you know,
capital outlay is a big one, making sure that you have space for a public private data center, public cloud. I hear a lot of concerns around vendor lock in that, you know, people don't want to, you know, get in and then not be able to get out and then customers, you know, with hybrid cloud, it sounds great, but there's a lot of complexity to manage that across all those environments.
So Roger, tell us how Ford created what they did. Thanks. So we didn't double the heights of the racks to get 88 racks worth of 180 racks of hardware into 88 racks. Um, but we had some hard conversations around what value we got from the hardware that we had. So first one, simplify. Try and consolidate.
We looked at our portfolio. We're very much uh the the poster child of a standard NAS uh stack, a separate sand stack, a separate object storage stack, and a separate backup stack, very much called out by Charlie yesterday in the keynote. Um, so we looked at that and, and came to the epiphany to a certain degree that storage is
storage and protocols are protocols, and with that, um, we had the hard conversations where we get maximizing our investments with dedicated sand, where we're using all the feature functionality, giving, uh, NAS was our largest footprint, that was the the footprint that we settled on to do a unified storage model. So we did heavy consolidation.
Second part, standardized. Uh, we did a lot of uh thoughts around how we could get a common language. We were just starting, I think, in Azure at the time and so there was no NAS, there was no SAN, it was all file block object, um, and so we introduced terms such as availability zones and regions, uh, geo resilience, local resilience,
and tried to describe our services. In a consistent way that you would see in the cloud that way it made it easier for our customers. We were very over complex and I often joke that it's sort of the tax return, um experience. Everyone had to fill in tons of paperwork that really didn't provide value,
overcompensating and copying and pasting between different spreadsheets, putting in tickets, very complex. When we looked at the automation side, uh, we had to understand, you know, where to start, um, you know, the, the utopias automate everything, but obviously that's a very big elephant to eat.
So we have to be very focused and you have to start that first step. And then measure, um, not only measuring what you're delivering, uh, in terms of service level objectives, service level indicators to know that you're delivering to your customer what you said, but also understand where the, The, the gravity is in terms of the most value, um, where,
what tickets are you receiving, what type of requests are coming into the system. So try to boil it down to three areas, uh, culture, very tough conversations, very hard conversations, sometimes very passionate conversations around how we change. Um, change is difficult, change has a lot of friction, um, but it's it's real really necessitated, um, with this journey.
And then being very upfront and honest understanding the value, but also uh deciding when to pivot and persevere. Often if you stay too long on something, there's a lot of experimentation, a lot of discovery, but if you pivot too early or you pivot too late, that can have introduced risk and and cause uh a lot of cost.
We start looking at clarity as I mentioned a common language we would describe our services as file block and object, we would have SLIs in terms of service level indicators that described latency, throughput, how you can actually measure what you're delivering, um, and those, uh, were clearly articulated to our customer. We provided a catalog very reminiscent of what you would see in the cloud.
And then when, where do you start? Uh, create was where we started. It doesn't exist. You don't have to worry about who has access to what. And so that was where we were able to, to get a lot of traction. And then taking a step back, we looked at, you know, where could we get most value first,
um, and in our organization, one of our main customers was our ESX team asking for data stores. And they would be subject to the same um uh cadence of putting in a ticket, fill in these artifacts, have you reviewed it with the architect, and so forth, and it was probably, it was a little bit quicker because we were friends, so they probably got their uh hardware or their storage in about 5 or 6 weeks.
So we started with that, uh, give, uh created our own API. Gave them some teach the fish sessions. They were able to execute it and from 5 to 6 weeks down to seconds. We were out of the system, we were not the constraint anymore. And that allowed them to accelerate and deliver VMs.
Um, and then based on that, uh, we looked at establishing a portal, um, we created the API we created was fronted by a portal for our customers. Um, and we thought, great, we've already got file services available, and we'll, we'll start with that. Uh, yeah, not everyone has route access to be able to mount up an NFS export,
so had still had the need to support the tickets when we first launched, but we're still able to take us out of the equation. Um, and actually where we found most value was going to object storage. Object storage doesn't require anything pre or post. So once you have your URL and your secrets, you're off to the races.
So that's really where we uh made a lot of good headway to take work out of the system, take waste, and take us out of the equation as well. Yeah Thanks Roger. OK, so at this point you should be thinking to yourself, how do I go about this journey? How can I be like Ford, uh, uh, uh, quote unquote accelerate.
I had to use that word at some point, uh, your journey to the cloud. So then, uh. Different approaches there is no one right approach, but one that is used frequently and championed by uh when I was at AWS working with customers is the idea of a cloud center of excellence. So what that is is essentially a group of people that you've created in your organization
whose sole focus is how do I get my company, my organization into the cloud whether it's public, private, or hybrid. So what this call center excellence, so what again, whatever you wanna call it, it's gonna be a team that is uh made up of folks across all your disciplines. So what you don't want is a call center of excellence made up of only developers because then they don't care about the money.
You also don't want it to be a group of people from finance only because then you just, well, you never get anything done. So uh at least uh anything done that doesn't, uh, that requires some investment. So what you wanna do is you want to create a team that has people from say networking, storage, uh, compute, developers, procurement, everyone, every stakeholder,
everyone who knows the full stack. Uh, from business through the technical, who have some kind of institutional knowledge that they can bring the bear, and then their job is to apply the best practices of the cloud along with those institutional knowledge to help your company decide how to move forward. And the reason this is so important is really because of communication.
So I asked you all earlier, what's the best restaurant you've been to this week? So I'm actually from originally from New York City, and in New York, the New York Times actually uh rates restaurants, and in New York, I think today there are only 5 restaurants out of the many thousands that have a 4 star rating. Right, and obviously the food is great at all those 4 star restaurants,
but that is not actually what makes them a 4 star restaurant alone. It is actually the service that it delivers and if you go to one of those restaurants, one of the things you notice is from the moment you go in to the time you leave. Every single person in that restaurant, every employee from the host to the waiters to the uh bussing staff to uh cooks, they're all in constant communication,
right, always figuring out how to give the best experience possible to their patrons. So in the same way, to in order to have a cloud that is working in your company, you need to get all the silos to start working together and communicating so that they can do things like apply best practices, take governance rules that you may have and be uh be able to apply them across through the entire stack.
And then what ultimately what the power of excellence team will do is they will create the best practices that your company should implement. They will they will figure out what, how to measure for success, so you know you're actually achieving the goals that you're trying to accomplish. And the deliverables that this call center of excellence needs to create,
really is not just technical as I mentioned, it's also business, right? It is, of course, things like what is the reference architecture, right? What is the um The best practice, uh, you know, deployment guy, it is support for the actual stack, but it also has to be aligned to the business.
It has the business goals and business outcomes. It has to have measures that says, hey, because of what we deploy, we are able to move the business forward. I used to work at a bank in the IT department and we used to say everything we do in IT does one of two things. We either run the bank or we change the bank.
Right, and the goal was always was right now we're spending 80% of all our time and resources just running the bank. What we wanna do is flip it eventually and spend 80% of our time changing the bank and making it better and uh something like a cloud, if you do it right, it can help uh drive that process forward, so avoid using the word accelerate.
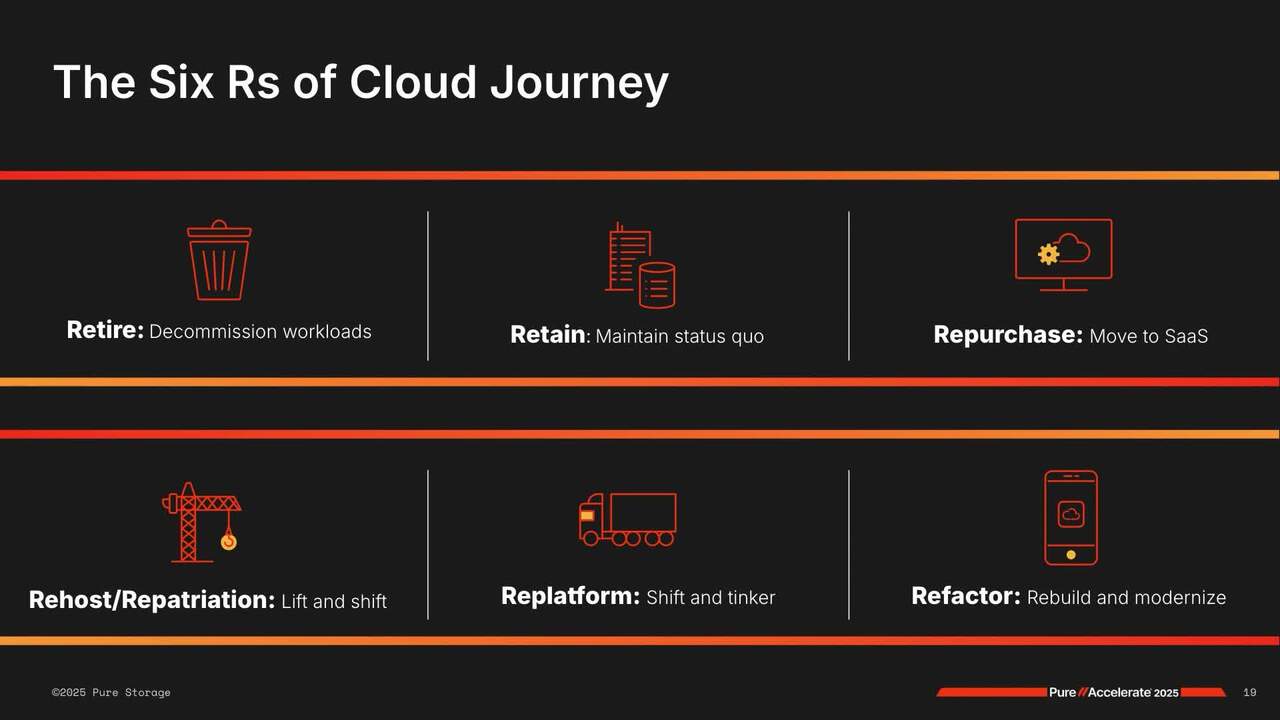
All right, so one of the first things that this cloud Center of Excellence needs to do is think about what actually belongs in the cloud and how do I actually run and run it. So once a, a, a framework that helps you think about this is what we call the 6 hours of the cloud journey. This is something you wanna apply to the workloads you have because not every workload belongs in every single category,
right? The whole idea is take this framework, apply to your workloads and say where do they belong. So quickly, with tie is pretty simple, right? These are workloads that you actually think maybe in 3 years they'll be gone. And it's, and then you have to ask yourself, is it even worth the time and effort to move them
to a cloud model? Maybe just leave them as this. And eventually they just gonna die off anyway. Uh, second one is retained it's just the idea of for various reasons whether it's financial security, or maybe you have heavy dependencies on your, uh, on-prem, uh, infrastructure, it doesn't actually make sense,
for example, to move it to the public cloud. You wanna keep them where they are because, uh, they, it would not serve the business well to actually move them. And then, uh, the, uh, third one is repurchase, which is really the idea of, so let me ask you, how many of you have how many of your companies run their own exchange
server, email servers in on-house? Not very many, right? It's just a couple. So the reality is a lot of bus most businesses have moved to using something like IM 365 or Google Workspace. So that's the idea we purchased.
If I don't have to worry about it at all, let's not worry about it if at all possible, right? But in the last, the bottom three are the ones I wanted to spend a little more time on, uh, which is what we call, uh, re-hosting or in some cases repatriation. So rehosting is this idea of I'm gonna move to, let's say to the public cloud.
What I'm gonna do is I'm gonna take my workload, my application as is, and move it to the cloud, not change anything. So if I'm running VMware and Prem, I'm just gonna run VMware in the cloud, right? If I'm using, uh, you know, certain types of storage, I'm gonna wanna use that exact same storage, nothing changes.
And that's good for to get started, but the downside is sometimes you don't get you don't really get all the benefits of the cloud, right? Because you haven't changed anything. What we're also seeing today though is for particularly for cost and performance reasons, some cus some customers say, let's let's bring it all back. Uh, which works because you haven't changed anything when you bought when you moved it,
so you don't have to change anything to bring it back. And, uh, one such example are application, uh, backups and restores. So one of the things that a cloud providers don't tell you is they, they will, uh, they are not well suited to mass restores if you actually actually had a DR ransomware attack, because guess what, you're one of 100,000 customers.
Sorry, you're not gonna get all the networking you need to restore all your workload. Um, if you try to do mass restores, they're gonna throttle you to make sure that you can't use up the resources. So for those applications, it makes sense to bring them back. And then replatforming is this idea of I'm running on-prem in my private cloud or hyper
cloud, but maybe I can change things underneath to make it better. Maybe I can change out the storage, for example, or change out the hypervisor or something that will improve what I'm doing today. Uh, and then finally, uh, refactoring is what you hear about this idea of how do I change the whole application, maybe use things like, um, microservices and,
and containers using Kubernetes and port works, and, uh, those actually take the longest to do, but, uh, can bring real benefits if you're able to do that well. And just how to get started at the center of excellence. So three main things to think about is you're not gonna hire a whole new team, right? Uh, you more likely you will not be able to do
that. So what you want to do is you want to start with the people you have, uh, train them in cloud practices, and hire to fill the gap as needed. Second is you need a you need a business sponsor. Right, because these, these are big uh tectonic changes you're not gonna do that by uh by kind
of announcing it from the IT standpoint. You need an executive sponsor who can stand behind you and push these changes across and then the third thing is you need to have good measurements of what you're doing. Um, move it, we're gonna move to the cloud. It's not a goal, it's not a mission, it's a slogan, right?
You need to be able to say this, we're gonna move to the cloud in this way, and these are the outcomes I expect to get and then be able to set milestones that you can reach along the way and so you can measure whether you're being successful or not. So that I'm gonna turn things back over to Roger. He's gonna talk about exactly what Ford built uh in their uh cloud.
Thanks again. So anyone familiar with lean manufacturing at all? Yeah, you may notice some of those terms and ironically we developed close alignment to lean manufacturing principles without even knowing it. Um, so when I talk about tack time, that's really looking at the time that we can manage
our capacity and deliver things. Um, we are very much an original, uh, consumer of leasing, and so what's, oh, what do I need in 3 years' time and I'll buy everything because I don't want to get into coachendless leasing. Um, and that provided a lot of waste. So what we developed was a unit of consumption
that we called it, which was a standard building material, and we would buy in set increments. All of that was pre-designed. It took work off the vendor, took work off us, and when we needed to just incrementally add capacity, uh, that's what we were able to do through the purchasing process and really take waste out of the system a lot of effort, um, and so when we would get a request for 5,
500 terabytes or even 5 petabytes, sure, go ahead and use it. The reality is you're not gonna be able to use it as quickly as I can actually supplement the capacity on the back end. So that talks about the scalability and running lean. Um, the catalog, it was really uh uh uh an adjustment for customers.
They were always asking things, uh, for in the terms of the media. I want quick storage. I want flash. I want, you know, cheap storage. Uh, that is not measurable. So having a catalog that clearly articulated the latency expectations that the throughput, the IOPs per terabyte really allowed us to not
only articulate to the customers and for them to understand what they were receiving, but also measure. So when you start looking at your site reliability engineering journey, SRE, uh, that is something that will set you on that way. And it also helps when you're trying to troubleshoot.
You know what you're delivering, you know where you're committing to the customer and the customer also can see transparency in terms of what you're delivering. From a flow perspective, how do you take constraints out of the system? Well, first of all, you need to know where those constraints are. We knew that we were constraints and so we went after uh low hanging fruits,
as I mentioned, our um ESX team was very appreciative of not having to work with us anymore by using the RAPI and then we built on top of that, uh, looking at how quickly we can deliver and get out of a customer mentality of hoarding. Customers don't want to do their tax return every month. I mean that's reality, uh, regardless of what Mike said,
uh, in the keynote, um, and so we took that out of the system that is work that is just needless, but when someone looks at, I don't wanna go through that process, each and every time I need more storage, they hoard, they ask for more than you need and that really sort of uh skews your forecasting. So we made it simple and we started, you know, on the journey of crude,
create, read up, update and delete with create as I mentioned, that was the easiest one for us and we started building on top of that, um, but with us changing the language, we have, um, you know, communication is key, we also had to educate our customers. We did a series of of short whiteboard videos a couple of minutes in length to educate our
customers and say this is, this is what file is, this is what block is because it was a language they hadn't seen before. We talked about local resilience and geo resilience RPOs and RTOs and so that service catalog defined what they were getting, uh, very sim similar to what was explained about fusion yesterday in terms of policy driven actions.
Um, we provided code examples for our customers that were new to object storage. Many people didn't even know how to spell S3, let alone use it. And so we gave code examples again, video and training so they could start developing and looking at how they could move to cloud, uh, you know, as an external uh cloud, but as part of their modernization journey.
And then Kaizen continuous improvement. We looked at what we were delivering and so measurement is really key. We were able to articulate how frequently our APIs were used and the value they were driving. Um, we attached, uh, you know, uh lead time in terms of how many hours a customer would generally wait, how many, how many hours it would generally take to consume and and process
these to be able to articulate upwards the value we were providing. The other measurement is around looking at tickets and seeing how those tickets can be reduced and what influence you have over over those. Where we went a little bit astray, and that's where I talk about pivot or persevere, um, we thought we knew what the customer wanted.
And so we decided, hey, we're gonna engineer this automation, customers will love it. No one used it, didn't provide value at all. Um, and so what we actually pivoted is, uh, in our portal is something called Wizard of Oz, where they would go into the portal, but behind the scenes it could be fully API driven or it
could just reanerate a ticket, taking complexity out of the system, you know, we would get a ticket saying, can you resize my F drive? like what's that? And you go back to the customer and the ping pong to get clarity as to what they actually need. In the portal they could see all their storage assets.
They could click on it and just say this is the action I need. So we could then scrape our tickets and understand, OK, if I get a 100 requests to do a certain action versus 5, I might have an automation opportunity to take work out of the system. So it's like continuous improvement. You don't have to automate everything,
but you're at least improving the customer experience by giving them all assets, all the uh content in one place. So what did we achieve? If I had a mic, I'd drop it, but then I'd probably have to pay for it. I broke it. Um, so we actually never got close to consuming
88 racks total, and we're probably coming up to about 50% now, but we're significantly higher in capacity. Um, just great reductions overall and again taking work out of the system, a 40% reduction in technology, uh, portfolio. What does that mean? Less complexity, less prone for uh mistakes
when you're doing change control, focusing on core skill sets. Uh, so there's a lot of value add behind the scenes that aren't just measurable in financial, uh, in terms of your budget, but also. your up time, and that's why when you start on your SRE journey and getting in the measurements you heard, you know, about up time, but what is the customer experiencing as well?
How do you measure? A lot of our clusters today stay permanently on because it's a rolling code upgrade. Well, how do you measure availability? You can't look up time of a controller because it went down when you gave a maintenance. Um, so we use the SLIs, the service level indicators to measure, you know, our error budgets and look at how we're providing a quality service and where to
go after in terms of improvements. Um, so this is what we were able to, to deliver as part of this journey. It was worth it. We're continuing to evolve, uh, and there's more opportunities for us. Uh, in terms of inspiration, uh, these are some, uh, recommended reading.
Uh, the lean startup is a very good one. I've, I've, uh, read and listened to that multiple times. The lean turnaround is a little bit aged, uh, it refers to BlackBerries and then in the early 2000s. Basic principles about identifying waste and looking at opportunities to improve is really
good. And then the last two Phoenix projects is really an IT view and a customer view in terms of the unicorn project. Um those are all fictional, um, but you know, we'll probably come uh resonate very quickly to a lot of individuals. Thanks, Audrey. All right, so obviously if you do the cloud
journey, you wanna make sure the cloud you run on is actually the cloud you need, right? The way you achieve that, uh, three things to keep in mind. One is the concept of working backwards. So when I was at Amazon at AWS, um, what we would use this term all the time. So one of the things that any time we want to roll out a new service.
One of the first things that a product manager had to do was write a press release announcing the product or what the product would be like with an FAQ to answer customer questions even before the development of the product started. And the idea is you this way everyone in the product team and the engineering team knew exactly what they were building and why they were building it and what the capabilities
should be so I use this now even in my personal life and it annoys my family, right, because any time they need to do something, guess what I asked them, tell them to do work backwards from the from the end goal. So I'm helping right now I'm helping my daughter think about financial management. So the way I do that is I go, OK, let's look, 30 years from now,
how much money do you think you need to have in your retirement? Right, we set a goal and then we go based on uh historical rate of return, how much money would you have to put in now every single year and every single month so that you could get to that goal right? so we work backwards from that and now she has a, uh, she has an IRA and she puts in a set amount of money every single month with a plan
to increase it year over year as she earns more money. Right, so that's the working backwards. So the idea here is you should not just go I'm going to the cloud, but you need to go, what is the end state that my company is working towards? What are the things that I'm looking to achieve, right? And then say is the best way to do that public
cloud, private cloud, hybrid, and what what are the services and applications I wanna be able to build and run in that cloud. The other key thing is having what we call key performance indicators. So again, it's not good enough to say, we moved a bunch of workloads into the cloud, right? You need to be able to say, measure how much
money did we actually saved. How many new, how much, uh, new opportunities and new revenue are we trying to get right? um, all kinds of metrics that you can try, you know, how much power savings do we have by going to maybe a different platform or going to a cloud model? All these things you need to have and not just.
Something you measure 52 years from now, but break that down again using that working backwards model and say every single every quarter I can measure and say if I hit these key performance indicators then I know I'm on my way to achieving that end goal in 2 years or 3 years. And then lastly you want to think about you and Roger mentioned this, you have to iterate over time, right?
The cloud you're planning to build now won't exactly be the cloud that you actually have. Because technology changes and business goals change, acquisitions happen, right? So you need to be able to be flexible to say I know what my outcome needs to be, but I mean I need to be flexible in the way that I achieve that. So how do I learn from my mistakes and also
learn from my successes, right? We we start small and then build over time. Uh, it's kind of like a, it's like kind of like being in a marriage, right? The person you marry today won't be the person that you're married to 30 years from now. Uh, I remember I talked to, uh, read an author who said,
I've been married I've been married to 5 different men, and they all the same person. Right? Because everyone changes over time, just like your infrastructure is gonna change over time, so learn to iterate and be ready to make the changes needed to get better.
So it's fine I'm gonna turn things over to valley. Oh, and last thing, uh, measure, measure, measure, right? If you can't measure it, then it didn't happen, right? Uh, any time I we set, uh, I set goals or my I have my team set goals always go, you can't, if you can't measure it with concrete metrics,
then that's not you didn't set a goal you just you set a wish. So let me think now I'll turn things over the valley to wrap this up. Awesome, thank you. All right, so how do you get started? How do you eat an elephant? One bite at a time.
As Ken said, you need to align your stakeholders from the people who pay for it all the way to the people who are doing the work. Identify a problem that a cloud operating model will solve. Is it time to value, human toil, error, and then pick your targets. You're not always going to have an opportunity to have a brand new data center.
I mean, maybe that'd be cool. But you may have to start with something smaller, a net new application, an internal POC where you can get started and do that learning. Now how can Pure help you on your cloud journey? Well, we have a number of ways. So how many of you here use Pure one?
I use it every day. I love Pure One. that actually is an observability platform where we take metrics from our global fleet and surface that information to you around resiliency, around data protection, security, virtualization, and you can actually get metrics out of Pier One into your external observability platforms.
Automation, whether it's Python scripts or terraform. Anyone, uh, caught the pure fusion, uh, sessions, if not, go back and rewatch them. That's really, really critical to this, being able to standardize and have policy-based, uh, provisioning and then our APIs, the API is not sexy, but customers really like how full functioning they are and how easy to
use. Non-disruptive upgrades. The reason I say that is the goal of being cloud-like is transparency to the end users. What's more transparent than be able to increase capacity, increase performance with no downtime. We have our pure storage cloud platforms. We actually operate purity in the public cloud
in AWS and Azure, giving you that data plane across both environments and allowing you to do some cost optimization. On demand scaling with Evergreen one giving you a true SLA, much like the cloud where we'll come to an agreement on performance, capacity, even the power and cooling that it has on your floor and that SLA is backed by
money. We'll write you a check if we miss it. And fun fact, you can actually measure those SLAs in ier one. And then of course, Portworks, as you start your container journey, you have data services for pretty much any Kubernetti's platform. All right, so hopefully we can help you drive your cloud journey.
Uh, we do have just a couple of minutes for questions, uh, while you're thinking about it or getting your nerve up, whatever, uh, we do have a couple of QR codes here. Number one is join our pure community. It's brand new. I'm on there, Ken's on there.
Let's have a conversation. And then, uh, if you want a pair of snazzy socks, go on there and, uh, put in your, uh, input into Gartner Pure Insights.


We Also Recommend...
Personalize for Me