Dismiss
Inovação
Uma plataforma criada para IA
Unificado, automatizado e pronto para transformar dados em inteligência.
Dismiss
16-18 juni, Las Vegas
Pure//Accelerate® 2026
Ontdek hoe u de ware waarde van uw gegevens kunt ontsluiten.
O que é o Delta Lake? Visão geral

O Delta Lake é uma estrutura de armazenamento de dados de código aberto desenvolvida para otimizar a confiabilidade e o desempenho do data lake. Ele aborda alguns dos problemas comuns enfrentados por data lakes, como consistência de dados, qualidade dos dados e falta de transacionalidade. Seu objetivo é fornecer uma solução de armazenamento de dados que possa lidar com cargas de trabalho escaláveis de Big Data em uma empresa orientada por dados.
Origens do Delta Lake
O Delta Lake foi lançado pela Databricks, uma empresa Apache Spark, em 2019 como um formato de tabela em nuvem desenvolvido em padrões abertos e código parcialmente aberto para dar suporte a recursos frequentemente solicitados de plataformas de dados modernas, como garantias ACID, reescritores simultâneos, mutabilidade de dados e muito mais.
Qual é a finalidade ou o uso principal do Delta Lake?
O Delta Lake foi desenvolvido para dar suporte e melhorar o uso de data lakes, que contêm grandes quantidades de dados estruturados e não estruturados.
Cientistas e analistas de dados usam data lakes para manipular e extrair insights valiosos desses conjuntos de dados enormes. Embora os data lakes tenham revolucionado a forma como gerenciamos os dados, eles também apresentam algumas limitações, incluindo qualidade dos dados, consistência dos dados e, o principal, falta de esquemas aplicados, o que dificulta a execução de aprendizado de máquina e operações de análise complexas em dados brutos.
Em 2021, cientistas de dados da academia e da tecnologia argumentaram que, devido a essas limitações, os data lakes logo seriam substituídos por “lakehouses”, que são plataformas abertas que unificam o armazenamento de dados e a análise avançada.
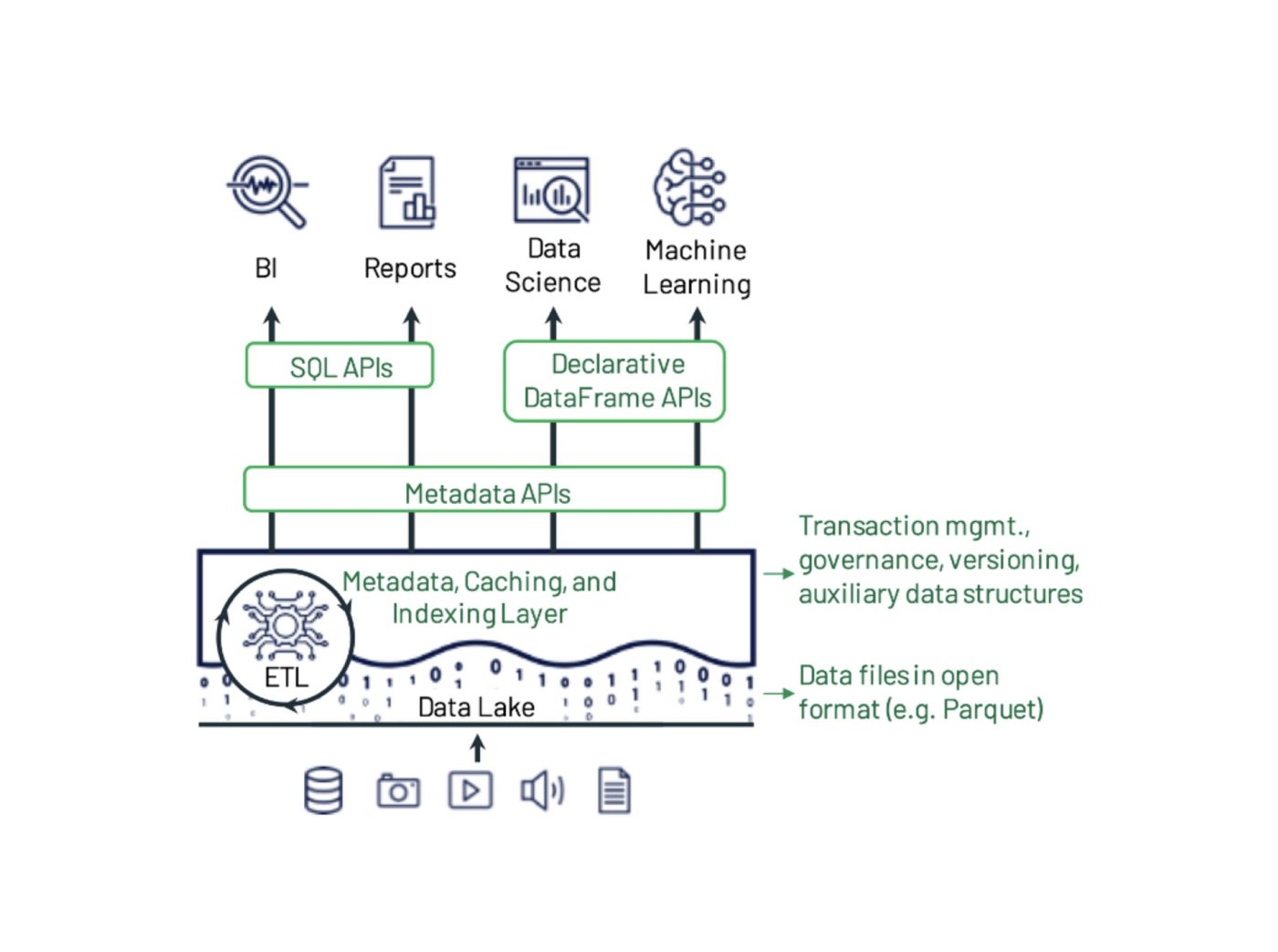
Figura 1: Exemplo de design de sistema de data lakehouse do artigo de Michael Armbrust, Ali Ghodsi, Reynold Xin e Matei Zaharia. O Delta Lake adiciona transações, versões e estruturas de dados auxiliares em arquivos em formato aberto e pode ser consultado com APIs e mecanismos diversos.
O Delta Lake é uma parte importante de qualquer infraestrutura de data lakehouse ao fornecer uma camada de armazenamento de dados chave.
O Delta Lake é definido por:
- Abertura: É um ecossistema de integração que se expande rapidamente e é voltado para a comunidade.
- Simplicidade: Ele fornece um único formato para unificar seu ETL, data warehouse e aprendizado de máquina em seu lago.
- Pronto para produção: Ele foi testada em mais de 10.000 ambientes de produção.
- Independente de plataforma: Você pode usá-lo com qualquer mecanismo de consulta em qualquer nuvem, local ou local.
Delta Lake vs. Data Lake vs. Data Warehouse vs. Data Lakehouse
Um Delta Lake é melhor compreendido no contexto mais amplo do datacenter, especialmente como ele se encaixa em data lakes, data warehouses e data lakehouses. Vamos dar uma olhada:
Delta Lake
O Delta Lake é uma camada de armazenamento de código aberto que preserva a integridade dos seus dados originais sem sacrificar o desempenho e a agilidade necessários para aplicativos de análise em tempo real, inteligência artificial (AI e aprendizado de máquina (ML).
Data Lake
Um data lake é um repositório de dados brutos em vários formatos. O volume e a variedade de informações em um data lake podem dificultar a análise e comprometer a qualidade e a confiabilidade dos dados.
Data Warehouse
Um data warehouse coleta informações de várias fontes, depois as reformata e organiza em um grande volume consolidado de dados estruturados que é otimizado para análise e geração de relatórios. O software proprietário e a incapacidade de armazenar dados não estruturados podem limitar sua utilidade.
Data Lakehouse
Um data lakehouse é uma plataforma de dados moderna que combina a flexibilidade e a escalabilidade de um data lake com a estrutura e os recursos de gerenciamento de um data warehouse em uma plataforma simples e aberta.

Faça um test drive do FlashBlade
Experimente uma instância de autoatendimento do Pure1® para gerenciar o FlashBlade™ da Pure, a solução mais avançada do setor que oferece expansão horizontal de armazenamento de arquivos e objetos nativo.
Como funciona o Delta Lake?
O Delta Lake funciona criando uma camada adicional de abstração entre os dados brutos e os mecanismos de processamento. Ele fica no topo de um data lake e usa seu sistema de armazenamento. Ele divide os dados em lotes e adiciona transações ACID sobre os lotes. O Delta Lake também permite a aplicação de esquemas para validação de dados antes de serem adicionados ao lago de dados.
O Delta Lake armazena dados no formato Parquet e usa o Hadoop Distributed File System (HDFS) ou Amazon S3 como camada de armazenamento. A camada de armazenamento armazena dados em arquivos Parquet imutáveis, com versões que permitem a evolução do esquema.
Como o Delta Lake melhora o desempenho dos dados por meio da indexação?
O Delta Lake melhora o desempenho dos dados criando índices sobre os dados acessados com frequência. Esses índices permitem um tempo de recuperação de dados mais rápido e ajudam a otimizar o desempenho. Embora cada banco de dados use indexação, o Delta Lake é único porque usa uma combinação de análise automática de metadados e layout de dados físicos para reduzir o número de arquivos verificados para atender a qualquer consulta.
Arquitetura do Delta Lake
O Delta Lake é uma camada de dados adicionada e representa uma evolução da arquitetura lambda, na qual o streaming e o processamento em lote ocorrem em paralelo e os resultados se fundem para fornecer uma resposta à consulta. Esse método adiciona complexidade e dificuldade para manter e operar os processos de streaming e lote.
O Delta Lake usa uma arquitetura de dados contínua que combina fluxos de trabalho em lote e streaming em um armazenamento de arquivos compartilhado por meio de um fluxo conectado. O arquivo de dados armazenado tem três camadas, chamadas de “arquitetura de vários saltos”, e os dados ficam mais refinados à medida que se movem a jusante no fluxo de dados:
- As tabelas Bronze contêm os dados brutos ingeridos de várias fontes, como sistemas de Internet das Coisas (IoT), CRM, RDBMS e arquivos JSON.
- As tabelas prata contêm uma visão mais refinada de nossos dados após passarem por processos de transformação e engenharia de recursos.
- As tabelas douradas são para usuários finais de relatórios de BI, análise ou processos de aprendizado de máquina.
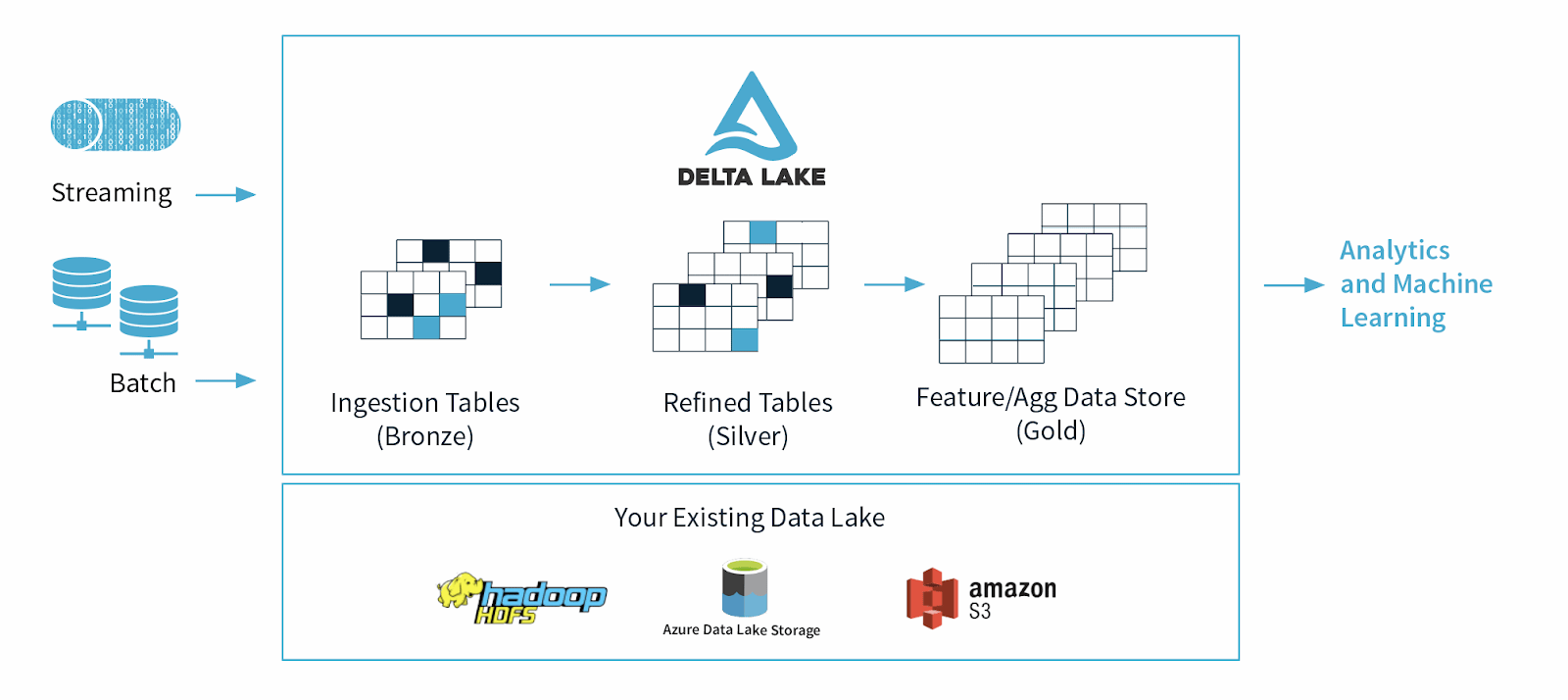
Figura 2: Arquitetura Delta Lake.
Benefícios do Delta Lake
O Delta Lake pode beneficiar qualquer empresa que dependa de soluções robustas de Big Data, incluindo as de finanças, saúde e varejo.
Os principais benefícios do Delta Lake incluem:
- Melhor confiabilidade de dados: O Delta Lake oferece garantias transacionais e isolamento de snapshots, aumentando a confiabilidade dos dados. Além disso, os usuários podem reverter transações com falha sem afetar outras transações bem-sucedidas. O Delta Lake usa mecanismos de controle de versão para adicionar novos dados ao data lake sem afetar os dados existentes.
- Suporte à evolução do esquema: O Delta Lake pode dar suporte à evolução do esquema em conjuntos de dados. Ele lida com alterações de esquema salvando um histórico de versão do esquema de dados e permite que os usuários atualizem o esquema antes de gravar os dados. O Delta Lake também verifica a validação do esquema de dados antes de gravar os dados.
- Compatibilidade: O Delta Lake é compatível com vários mecanismos de processamento de Big Data, incluindo Apache Spark, Hadoop e Amazon EMR. O Delta Lake também vem integrado a consultas semelhantes a SQL, permitindo que os usuários manipulem e extraiam insights dos conjuntos de dados.
Todos esses benefícios ajudam a tornar o Delta Lake uma importante solução de armazenamento de dados.
Desvantagens do Delta Lake
Embora o Delta Lake tenha muitos benefícios, ele também tem algumas desvantagens, incluindo:
- Não é ideal para dados não estruturados: Se você não lida com grandes quantidades de dados não estruturados ou tem uma pequena necessidade de armazenamento de dados, o Delta Lake pode não ser a melhor solução para você. As soluções de armazenamento de dados podem ser mais simples de implementar e mais econômicas.
- Não é fácil aprender: Embora o Delta Lake seja uma excelente solução para cargas de trabalho de Big Data, ele pode exigir recursos de desenvolvimento adicionais e tempo para implementação. Além disso, há uma curva de aprendizado acentuada para usuários novos na plataforma.
Como obter e implementar o Delta Lake
Você pode obter o Delta Lake de várias fontes possíveis, incluindo repositórios Apache Spark do GitHub , do site do Delta Lake e de aplicativos populares de terceiros, como o Databricks. O Delta Lake é implementado adicionando-o como mecanismo de processamento a um cluster de Big Data existente, como Apache Spark, Hadoop ou Amazon EMR.
Conclusão
O Delta Lake é uma excelente solução para cargas de trabalho de Big Data que permitem aos usuários gerenciar conjuntos de dados não estruturados de maneira confiável. Ele fornece recursos como transações ACID, validação de esquema e integração de API. Embora o Delta Lake tenha alguns requisitos de armazenamento indireto, ele pode lidar com a expansão de uma empresa orientada por dados de maneira eficaz. O Delta Lake oferece uma estrutura robusta para melhorar a qualidade e a confiabilidade dos dados e é uma adição útil a qualquer plataforma de Big Data.
Procurando infraestrutura de armazenamento com armazenamento de objetos rápido o suficiente para dar suporte ao seu Delta Lake? Continue lendo para saber como criar um data lakehouse aberto com o Delta Lake e o FlashBlade ®.
Também recomendamos…
Confira os principais recursos e eventos

FEIRA DE NEGÓCIOS
Pure//Accelerate® 2.026
June 16-18, 2026 | Resorts World Las Vegas
Prepare-se para o evento mais valioso do ano.

DEMONSTRAÇÕES SOBRE O PURE360
Explore, conheça e teste a Everpure.
Acesse vídeos e demonstrações sob demanda para ver do que a Everpure é capaz.

VÍDEO
Assista: O valor de um Enterprise Data Cloud.
Charlie Giancarlo sobre o por que de gerenciar dados — e não o armazenamento — é o futuro. Descubra como uma abordagem unificada transforma as operações de TI corporativas.

RECURSO
O armazenamento legado não pode potencializar o futuro.
Cargas de trabalho avançadas exigem velocidade, segurança e escala compatíveis com a IA. Sua pilha está pronta?
Personalize for Me