Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
What Is Delta Lake? An Overview

Delta Lake is an open source data storage framework designed to optimise data lake reliability and performance. It addresses some of the common issues faced by data lakes, such as data consistency, data quality, and lack of transactionality. Its aim is to provide a data storage solution that can handle scalable, big data workloads in a data-driven business.
Delta Lake Origins
Delta Lake was launched by Databricks, an Apache Spark company, in 2019 as a cloud table format built on open standards and partially open source to support oft-requested features of modern data platforms, such as ACID guarantees, concurrent rewriters, data mutability, and more.
What’s the Purpose or Main Use of Delta Lake?
Delta Lake was built to support and enhance the use of data lakes, which hold huge amounts of both structured and unstructured data.
Data scientists and data analysts use data lakes to manipulate and extract valuable insights from these massive data sets. While data lakes have revolutionized how we manage data, they also come with some limitations, including data quality, data consistency, and, the primary one, a lack of enforced schemas, which makes it difficult to perform machine learning and complex analytics operations on raw data.
In 2021, data scientists from both academia and tech argued that, because of these limitations, data lakes would soon be replaced by “lakehouses,” which are open platforms that unify data warehousing and advanced analytics.
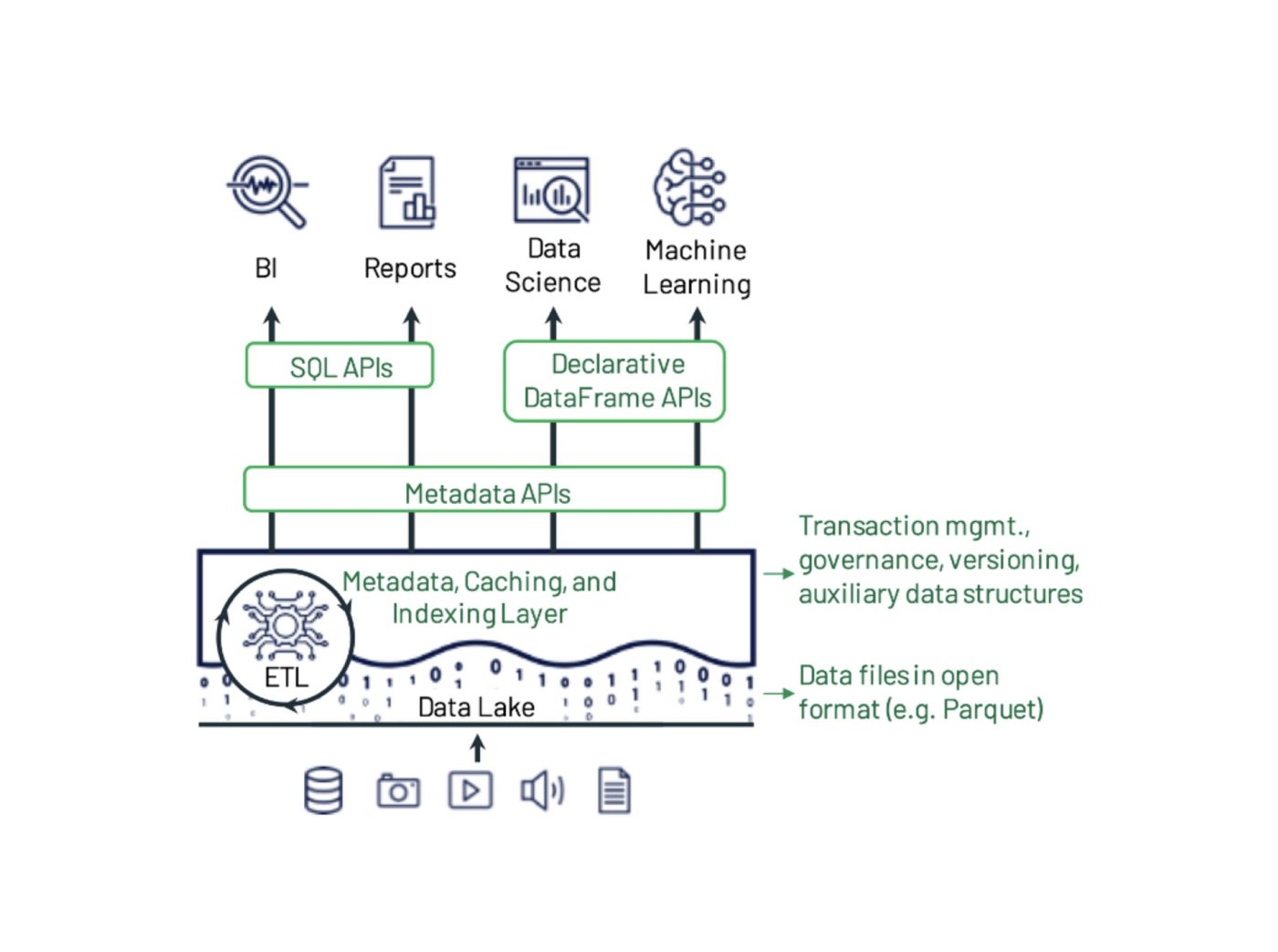
Figure 1: Example data lakehouse system design from the paper by Michael Armbrust, Ali Ghodsi, Reynold Xin, and Matei Zaharia. Delta Lake adds transactions, versioning, and auxiliary data structures over files in an open format and can be queried with diverse APIs and engines.
Delta Lake is an important part of any lakehouse infrastructure by providing a key data storage layer.
Delta Lake is defined by:
- Openness: It’s a rapidly expanding integration ecosystem that is community-driven.
- Simplicity: It provides a single format to unify your ETL, data warehouse, and machine learning in your lakehouse.
- Production-ready: It’s been battle-tested in more than 10,000 production environments.
- Platform-agnostic: You can use it with any query engine on any cloud, on-prem, or locally.
Delta Lake vs. Data Lake vs. Data Warehouse vs. Data Lakehouse
A Delta Lake is best understood within the broader context of the data centre, particularly how it fits in alongside data lakes, data warehouses, and data lake houses. Let’s take a closer look:
Delta Lake
Delta Lake is an open source storage layer that preserves the integrity of your original data without sacrificing the performance and agility required for real-time analytics, artificial intelligence (AI), and machine learning (ML) applications.
Data Lake
A data lake is a repository of raw data in multiple formats. The volume and variety of information in a data lake can make analysis difficult and compromise data quality and reliability.
Data Warehouse
A data warehouse gathers information from multiple sources, then reformats and organizes it into a large, consolidated volume of structured data that’s optimised for analysis and reporting. Proprietary software and an inability to store unstructured data can limit its usefulness.
Data Lakehouse
A data lakehouse is a modern data platform that combines the flexibility and scalability of a data lake with the structure and management features of a data warehouse in a simple, open platform.

Test Drive FlashBlade
Experience a self-service instance of Pure1® to manage Pure FlashBlade™, the industry's most advanced solution delivering native scale-out file and object storage.
How Does Delta Lake Work?
Delta Lake works by creating an additional layer of abstraction between the raw data and the processing engines. It sits on top of a data lake and uses its storage system. It divides data into batches, then adds ACID transactions on top of the batches. Delta Lake also enables schema enforcement for data validation before it is added to the lake.
Delta Lake stores data in Parquet format and uses the Hadoop Distributed File System (HDFS) or Amazon S3 as the storage layer. The storage layer stores data in immutable Parquet files, which are versioned to allow for schema evolution.
How Does Delta Lake Improve Data Performance through Indexing?
Delta Lake improves data performance by creating indexes on top of frequently accessed data. These indexes enable faster data retrieval time and help optimise performance. While every database uses indexing, Delta Lake is unique in that it uses a combination of automatic metadata parsing and physical data layout to reduce the number of files scanned to fulfill any query.
Delta Lake Architecture
Delta Lake is an added data layer and represents an evolution of the lambda architecture, in which streaming and batch processing occur in parallel and the results merge to provide a query response. This method adds complexity and difficulty to maintaining and operating the streaming and batch processes.
Delta Lake uses a continuous data architecture that combines streaming and batch workflows in a shared file store through a connected pipeline. The stored data file has three layers, referred to as a “multi-hop architecture,” and the data gets more refined as it moves downstream in the dataflow:
- Bronze tables contain the raw data ingested from multiple sources like the internet of things (IoT) systems, CRM, RDBMS, and JSON files.
- Silver tables contain a more refined view of our data after undergoing transformation and feature engineering processes.
- Gold tables are for end users for BI reporting, analysis, or machine learning processes.
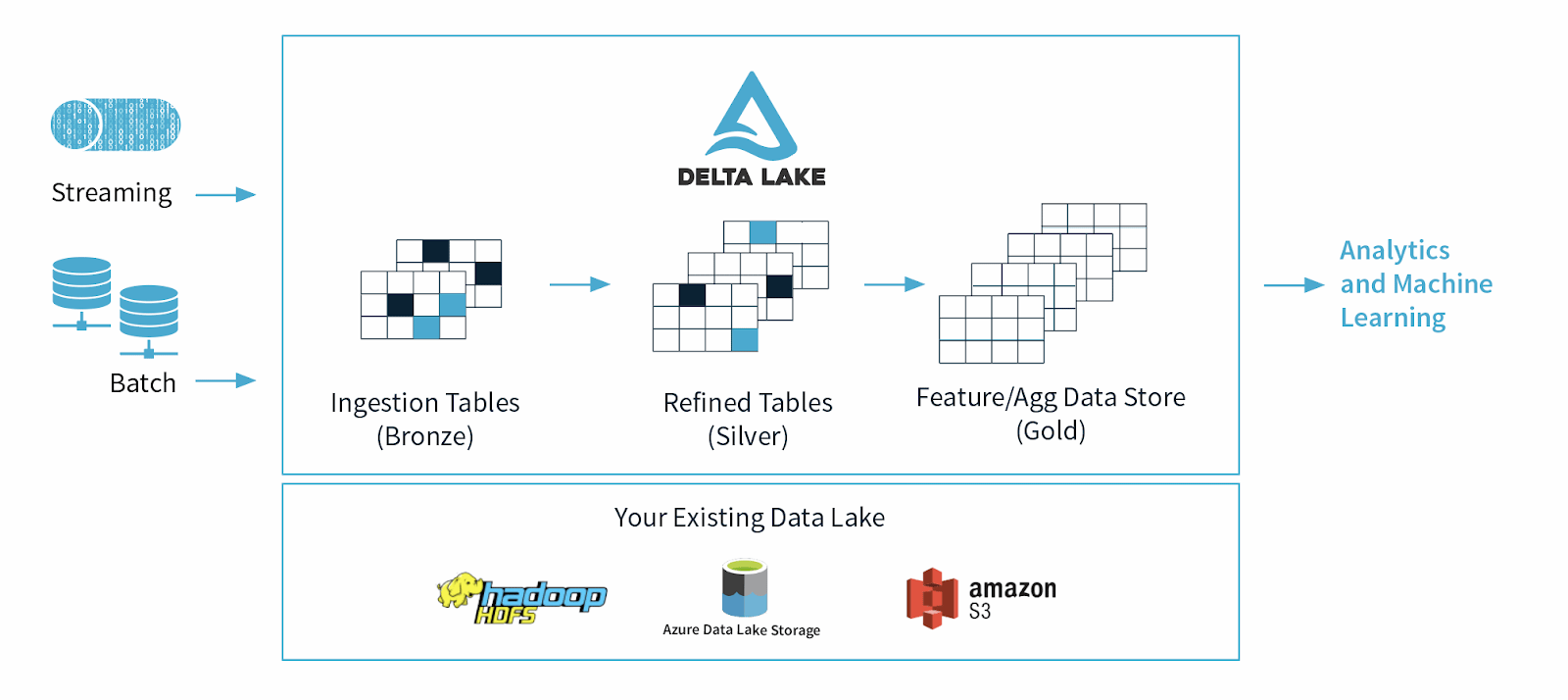
Figure 2: Delta Lake architecture.
Benefits of Delta Lake
Delta Lake can benefit any company that relies on robust big data solutions, including those in finance, healthcare, and retail.
Delta Lake’s primary benefits include:
- Better data reliability: Delta Lake provides transactional guarantees and snapshot isolation, enhancing data reliability. Additionally, users can roll back failed transactions without affecting other successful transactions. Delta Lake uses version control mechanisms to add new data into the data lake without affecting existing data.
- Support of schema evolution: Delta Lake can support schema evolution in data sets. It handles schema changes by saving a version history of the data schema and enables users to update the schema before writing the data. Delta Lake also checks for data schema validation before writing the data.
- Compatibility: Delta Lake is compatible with various big data processing engines, including Apache Spark, Hadoop, and Amazon EMR. Delta Lake also comes integrated with SQL-like queries, enabling users to manipulate and extract insights from the data sets.
All of these benefits help to make Delta Lake an important data storage solution.
Disadvantages of Delta Lake
While Delta Lake has many benefits, it also has some drawbacks, including:
- Not ideal for unstructured data: If you do not deal with large amounts of unstructured data or have a small data storage need, Delta Lake may not be the best solution for you. Traditional data storage solutions may be simpler to implement and more cost-effective.
- Not easy to learn: While Delta Lake is an excellent solution for big data workloads, it may require additional development resources and time to implement. Additionally, there is a steep learning curve for users who are new to the platform.
How to Get and Implement Delta Lake
You can obtain Delta Lake from several possible sources, including Apache Spark repositories from GitHub, the Delta Lake website, and popular third-party applications such as Databricks. Delta Lake is implemented by adding it as a processing engine to an existing big data cluster, such as Apache Spark, Hadoop, or Amazon EMR.
Conclusion
Delta Lake is an excellent solution for big data workloads that enable users to manage unstructured data sets reliably. It provides features such as ACID transactions, schema validation, and API integration. While Delta Lake has some overhead storage requirements, it can handle the scaling of a data-driven business effectively. Delta Lake provides a robust framework to enhance data quality and reliability and is a useful addition to any big data platform.
Looking for storage infrastructure with object storage fast enough to support your Delta Lake? Read on to learn how to build an open data lakehouse with Delta Lake and FlashBlade®.
We Also Recommend...
Browse key resources and events

TRADESHOW
Pure Accelerate 2026
June 16-18, 2026 | Resorts World Las Vegas
Get ready for the most valuable event you’ll attend this year.

PURE360 DEMOS
Explore, learn, and experience Everpure.
Access on-demand videos and demos to see what Everpure can do.

VIDEO
Watch: The value of an Enterprise Data Cloud
Charlie Giancarlo on why managing data—not storage—is the future. Discover how a unified approach transforms enterprise IT operations.

BLOG
What’s in a Net Promoter Score?
For nine consecutive years, Everpure has maintained a Net Promoter Score of over 80. Find out how we did it and what it means for our customers.
Personalize for Me