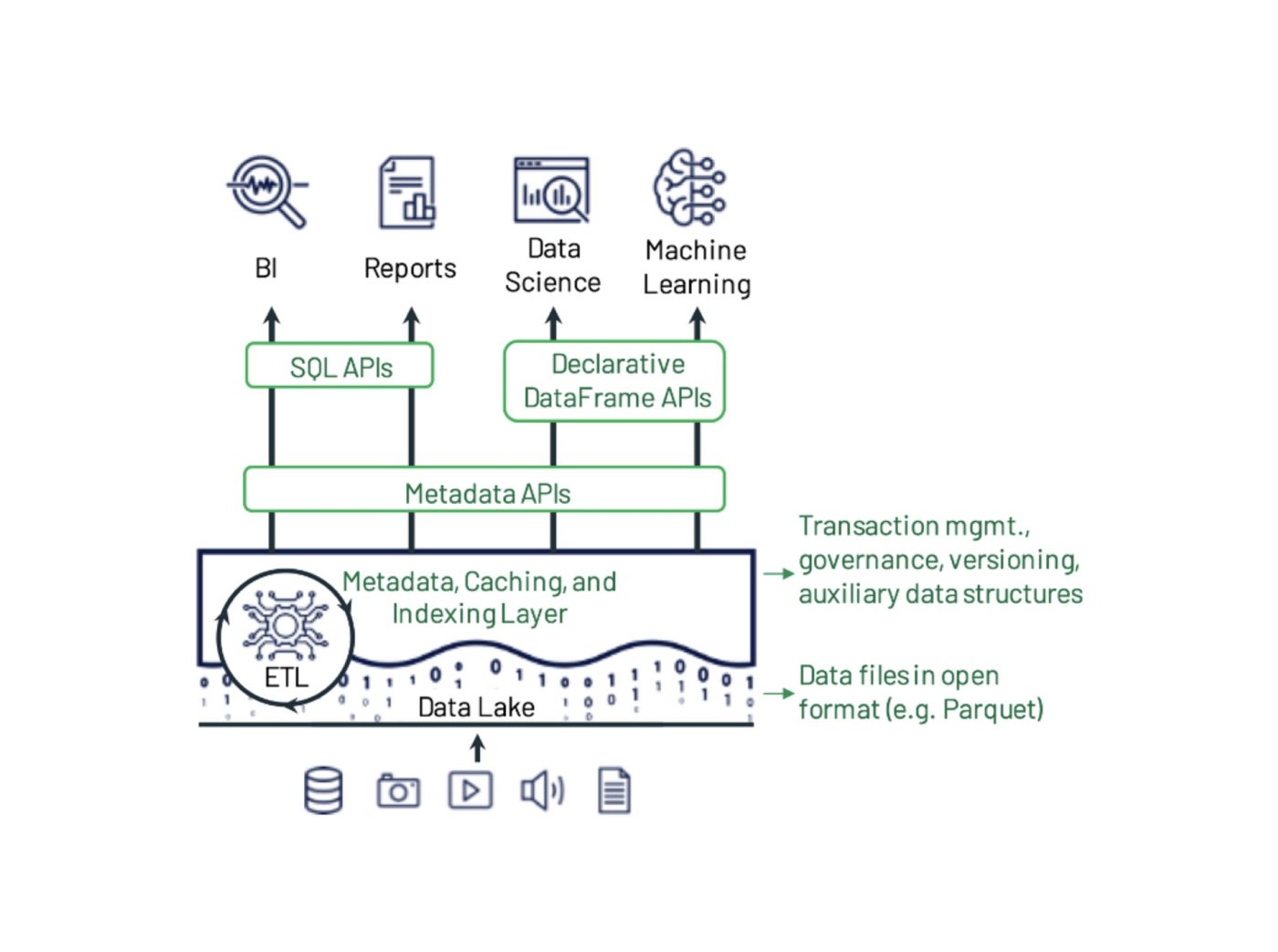
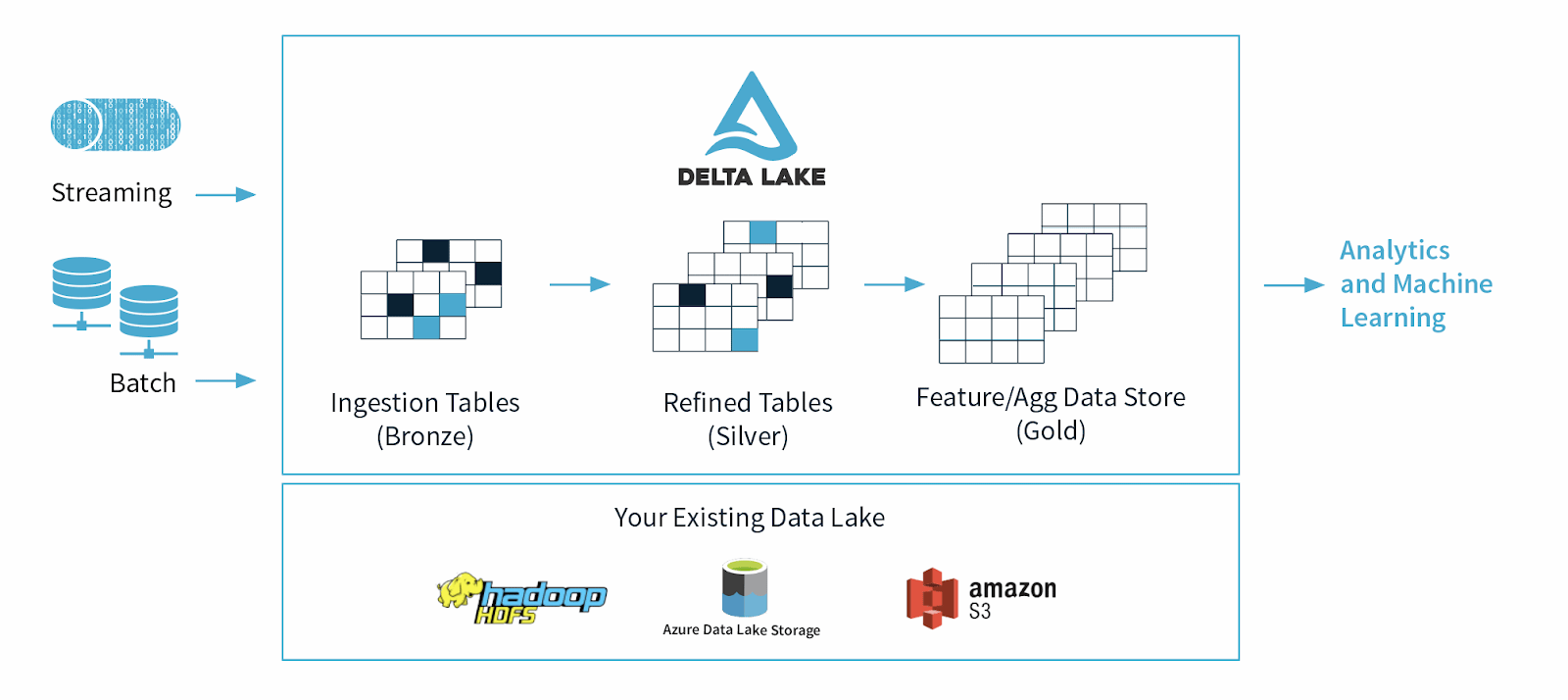
델타 레이크의 혜택
델타 레이크는 금융, 헬스케어 및 소매 업계를 포함한 강력한 빅데이터 솔루션에 의존하는 모든 기업에 혜택을 줄 수 있습니다.
델타 레이크의 주요 혜택은 다음과 같습니다.
- 데이터 안정성 향상: 델타 레이크는 트랜잭션 보장 및 스냅샷 분리를 제공하여 데이터 신뢰성을 향상시킵니다. 또한, 사용자는 다른 성공적인 트랜잭션에 영향을 주지 않고 실패한 트랜잭션을 롤백할 수 있습니다. 델타 레이크는 버전 관리 메커니즘을 사용하여 기존 데이터에 영향을 주지 않고 데이터 레이크에 새로운 데이터를 추가합니다.
- 스키마 진화 지원: 델타 레이크는 데이터 세트의 스키마 진화를 지원할 수 있습니다. 데이터 스키마의 버전 이력을 저장하여 스키마 변경을 처리하고 사용자가 데이터를 쓰기 전에 스키마를 업데이트할 수 있습니다. 또한, 델타 레이크는 데이터를 작성하기 전에 데이터 스키마 검증을 확인합니다.
- 호환성: 델타 레이크는 Apache Spark, Hadoop, Amazon EMR 등 다양한 빅데이터 처리 엔진과 호환됩니다. 또한 Delta Lake는 SQL과 유사한 쿼리와 통합되어 사용자가 데이터 세트에서 인사이트를 조작하고 추출할 수 있도록 지원합니다.
이러한 모든 혜택은 델타 레이크를 중요한 데이터 스토리지 솔루션으로 만드는 데 도움이 됩니다.
델타 레이크의 단점
델타 레이크에는 다음과 같은 여러 가지 장점이 있습니다.
- 비정형 데이터에 적합하지 않음: 많은 양의 비정형 데이터를 처리하지 않거나 작은 데이터 스토리지가 필요한 경우, 델타 레이크가 최적의 솔루션이 아닐 수 있습니다. 기존의 데이터 스토리지 솔루션 구현이 더 간단하고 비용 효율적일 수 있습니다.
- 배우기 쉽지 않음: 델타 레이크는 빅데이터 워크로드를 위한 탁월한 솔루션이지만, 추가 개발 리소스와 구현 시간이 필요할 수 있습니다. 또한, 플랫폼에 처음 접속한 사용자를 위한 가파른 학습 곡선이 있습니다.
델타 레이크 다운로드 및 구현 방법
GitHub 의 Apache Spark 저장소, Delta Lake 웹사이트, Databricks와 같은 인기 있는 제3자 애플리케이션 등 여러 출처에서 Delta Lake를 얻을 수 있습니다. 델타 레이크는 Apache Spark, Hadoop 또는 Amazon EMR과 같은 기존 빅데이터 클러스터에 처리 엔진으로 추가함으로써 구현됩니다.
결론
델타 레이크는 빅데이터 워크로드를 위한 탁월한 솔루션으로, 사용자가 비정형 데이터 세트를 안정적으로 관리할 수 있도록 지원합니다. ACID 트랜잭션, 스키마 검증 및 API 통합과 같은 기능을 제공합니다. 델타 레이크에는 오버헤드 스토리지 요구사항이 있지만, 데이터 기반 비즈니스의 확장을 효과적으로 처리할 수 있습니다. 델타 레이크는 데이터 품질과 안정성을 향상시키는 강력한 프레임워크를 제공하며, 빅데이터 플랫폼에도 유용합니다.
델타 레이크를 지원할 만큼 빠른 오브젝트 스토리지를 갖춘 스토리지 인프라를 찾고 계신가요? 델타 레이크와 플래시블레이드(FlashBlade)®를 통해 오픈 데이터 레이크하우스를 구축하는 방법을 알아보세요.