Dismiss
Innovazione
Una piattaforma creata per l'AI
Unificata, automatizzata e pronta a trasformare i dati in intelligence.
Dismiss
16-18 giugno, Las Vegas
Pure//Accelerate® 2026
Scopri come trarre il massimo dai tuoi dati.
Che cos'è Delta Lake? una panoramica

Delta Lake è un framework di data storage open source progettato per ottimizzare l'affidabilità e le performance dei data lake. Risolve alcuni dei problemi più comuni dei data lake, come la coerenza dei dati, la qualità dei dati e la mancanza di transazionalità. Il suo obiettivo è fornire una soluzione di data storage in grado di gestire workload di Big Data scalabili in un'azienda basata sui dati.
Origini dei laghi Delta
Delta Lake è stata lanciata da Databricks, un'azienda Apache Spark, nel 2019 come un formato di tabella cloud basato su standard aperti e parzialmente open source per supportare le funzionalità richieste dalle piattaforme dati moderne, come garanzie ACID, ricritture simultanee, mutabilità dei dati e altro ancora.
Qual è lo scopo o l'uso principale di Delta Lake?
Delta Lake è stato creato per supportare e migliorare l'uso dei data lake, che contengono enormi quantità di dati strutturati e non strutturati.
I data scientist e gli analisti utilizzano i data lake per manipolare ed estrarre preziose informazioni approfondite da questi enormi dataset. Anche se i data lake hanno rivoluzionato il modo in cui gestiamo i dati, presentano anche alcune limitazioni, tra cui la qualità dei dati, la coerenza dei dati e, soprattutto, la mancanza di schemi applicati, che rendono difficile eseguire il machine learning e complesse operazioni di analytics sui dati raw.
Nel 2021, i data scientist del mondo accademico e della tecnologia hanno sostenuto che, a causa di questi limiti, i data lake sarebbero stati presto sostituiti da "lakehouse", che sono piattaforme aperte che unificano il data warehousing e gli analytics avanzati.
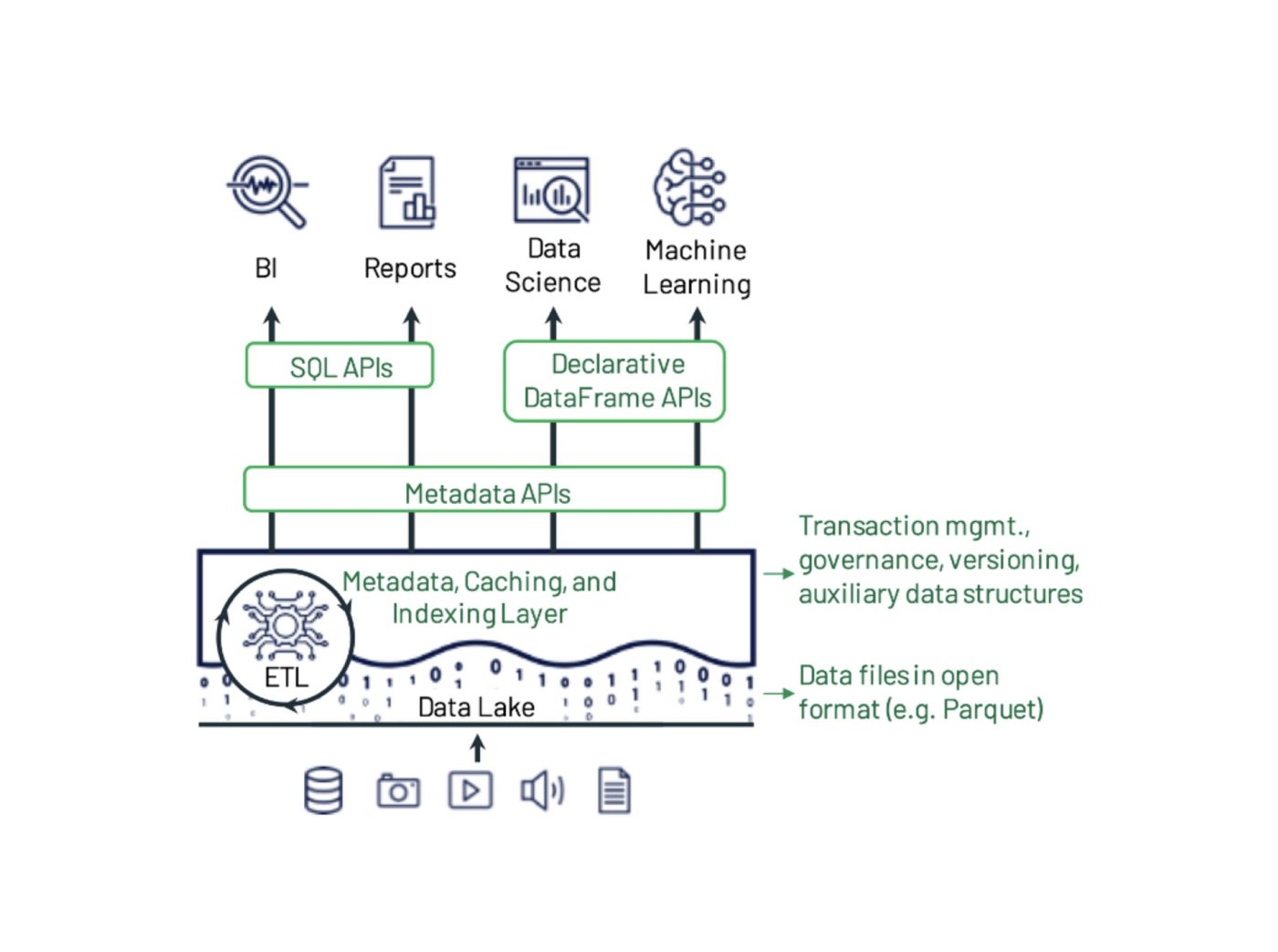
Figura 1: Esempio di progettazione dei sistemi di data lakehouse dal documento di Michael Armbrust, Ali Ghodsi, Reynold Xin e Matei Zaharia. Delta Lake aggiunge transazioni, versioning e strutture dati ausiliarie su file in un formato aperto e può essere sottoposto a query con API e motori diversi.
Delta Lake è una parte importante di qualsiasi infrastruttura lakehouse, poiché fornisce un livello di data storage chiave.
Delta Lake è definito da:
- Apertura: Si tratta di un ecosistema di integrazione in rapida espansione basato sulla community.
- Semplicità: Fornisce un unico formato per unificare ETL, data warehouse e machine learning nel tuo lakehouse.
- Pronto per la produzione: È stato testato in oltre 10.000 ambienti di produzione.
- Agnostico alla piattaforma: Puoi usarlo con qualsiasi motore di query su qualsiasi cloud, on-premise o localmente.
Confronto tra Delta Lake e Data Lake e Data Warehouse e Data Lakehouse
Un Delta Lake è meglio compreso nel contesto più ampio del data center, in particolare come si inserisce insieme a data lake, data warehouse e data lake house. Diamo un'occhiata più da vicino:
Lago Delta
Delta Lake è un livello di storage open source che preserva l'integrità dei dati originali senza sacrificare le performance e l'agilità necessarie per le applicazioni di analytics in tempo reale, intelligenza artificiale (AI) e machine learning (ML).
Data lake
Un data lake è un repository di dati raw in più formati. Il volume e la varietà delle informazioni in un data lake possono rendere difficile l'analisi e compromettere la qualità e l'affidabilità dei dati.
Data warehouse
Un data warehouse raccoglie informazioni da più origini, quindi le riformatta e le organizza in un grande volume consolidato di dati strutturati ottimizzati per l'analisi e il reporting. Un software proprietario e l'impossibilità di memorizzare dati non strutturati possono limitarne l'utilità.
Lakehouse dei dati
Un data lakehouse è una data platform moderna che combina la flessibilità e la scalabilità di un data lake con la struttura e le funzionalità di gestione di un data warehouse in una piattaforma semplice e aperta.

Prova FlashBlade attraverso il nostro Test Drive
Prova l'esperienza di un'istanza self-service di Pure1® per gestire Pure FlashBlade™, la soluzione più avanzata del settore che offre file e l'object storage scale-out nativi.
Come funziona Delta Lake?
Delta Lake opera creando un ulteriore livello di astrazione tra i dati raw e i motori di elaborazione. Si trova sopra un data lake e utilizza il suo sistema di storage. Divide i dati in batch, quindi aggiunge le transazioni ACID ai batch. Delta Lake consente inoltre l'applicazione degli schemi per la convalida dei dati prima che vengano aggiunti al lake.
Delta Lake memorizza i dati in formato Parquet e utilizza Hadoop Distributed File System (HDFS) o Amazon S3 come livello di storage. Il livello di storage memorizza i dati in file Parquet immutabili, che vengono sottoposti a una versione per consentire l'evoluzione dello schema.
In che modo Delta Lake migliora le performance dei dati tramite l'indicizzazione?
Delta Lake migliora le performance dei dati creando indici in aggiunta ai dati a cui si accede di frequente. Questi indici accelerano i tempi di recupero dei dati e ottimizzano le performance. Mentre ogni database utilizza l'indicizzazione, Delta Lake è unico nel suo genere perché utilizza una combinazione di analisi automatica dei metadati e layout fisico dei dati per ridurre il numero di file scansionati per soddisfare qualsiasi richiesta.
Architettura di Delta Lake
Delta Lake è un ulteriore livello di dati e rappresenta un'evoluzione dell'architettura lambda, in cui lo streaming e l'elaborazione in batch avvengono in parallelo e i risultati si uniscono per fornire una risposta alle query. Questo metodo aggiunge complessità e difficoltà alla manutenzione e al funzionamento dei processi di streaming e batch.
Delta Lake utilizza un'architettura dati continua che combina workflow di streaming e batch in un file store condiviso tramite una pipeline connessa. Il file di dati memorizzato ha tre livelli, indicati come "architettura multihop", e i dati vengono perfezionati man mano che si spostano a valle nel flusso di dati:
- Le tabelle Bronze contengono i dati raw acquisiti da più origini, come i sistemi IoT (Internet of Things), il CRM, RDBMS e i file JSON.
- Le tabelle in argento contengono una vista più dettagliata dei nostri dati dopo aver subito una trasformazione e aver sviluppato processi di progettazione delle funzionalità.
- Le tabelle Gold sono destinate agli utenti finali per i processi di reporting, analisi o machine learning di BI.
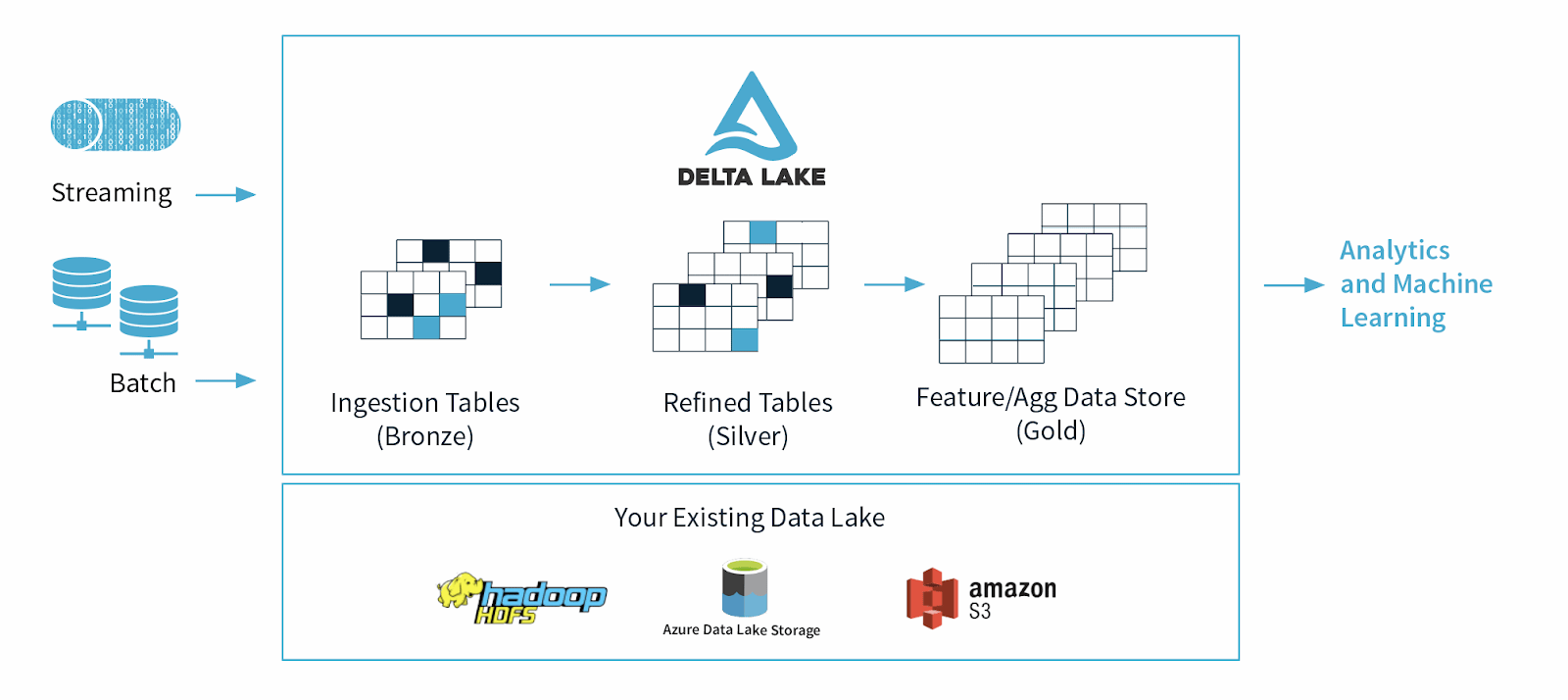
Figura 2: Architettura di Delta Lake.
Vantaggi di Delta Lake
Delta Lake può essere vantaggioso per qualsiasi azienda che si affida a solide soluzioni di Big Data, incluse quelle nel settore finanziario, sanitario e retail.
I vantaggi principali di Delta Lake includono:
- Migliore affidabilità dei dati: Delta Lake fornisce garanzie transazionali e isolamento delle snapshot, migliorando l'affidabilità dei dati. Inoltre, gli utenti possono annullare le transazioni non riuscite senza influire sulle altre transazioni riuscite. Delta Lake utilizza meccanismi di controllo delle versioni per aggiungere nuovi dati nel data lake senza influire sui dati esistenti.
- Supporto dell'evoluzione degli schemi: Delta Lake può supportare l'evoluzione degli schemi nei dataset. Gestisce le modifiche dello schema salvando una cronologia delle versioni dello schema dati e consente agli utenti di aggiornare lo schema prima di scrivere i dati. Delta Lake verifica inoltre la convalida dello schema dei dati prima di scriverli.
- Compatibilità: Delta Lake è compatibile con vari motori di elaborazione dei Big Data, tra cui Apache Spark, Hadoop e Amazon EMR. Delta Lake è inoltre integrato con query di tipo SQL, consentendo agli utenti di manipolare ed estrarre informazioni approfondite dai dataset.
Tutti questi vantaggi contribuiscono a rendere Delta Lake una soluzione di data storage importante.
Svantaggi di Delta Lake
Anche se Delta Lake offre molti vantaggi, presenta anche alcuni svantaggi, tra cui:
- Non ideale per i dati non strutturati: Se non hai a che fare con grandi quantità di dati non strutturati o hai un'esigenza di data storage di piccole dimensioni, Delta Lake potrebbe non essere la soluzione migliore per te. Le soluzioni di data storage tradizionali possono essere più semplici da implementare e più convenienti.
- Non facile da apprendere: Sebbene Delta Lake sia una soluzione eccellente per i workload di Big Data, potrebbe richiedere ulteriori risorse di sviluppo e tempo per l'implementazione. Inoltre, c'è una curva di apprendimento ripida per gli utenti che non conoscono la piattaforma.
Come ottenere e implementare Delta Lake
Puoi ottenere Delta Lake da diverse fonti possibili, tra cui i repository Apache Spark da GitHub, il sito web di Delta Lake e le applicazioni di terze parti più diffuse come Databricks. Delta Lake viene implementato aggiungendolo come motore di elaborazione a un cluster di Big Data esistente, come Apache Spark, Hadoop o Amazon EMR.
Conclusione
Delta Lake è una soluzione eccellente per i workload di Big Data che consente agli utenti di gestire in modo affidabile i dataset non strutturati. Fornisce funzionalità come transazioni ACID, convalida degli schemi e integrazione API. Anche se Delta Lake ha alcuni requisiti di overhead storage, può gestire efficacemente la scalabilità di un'azienda basata sui dati. Delta Lake fornisce un framework solido per migliorare la qualità e l'affidabilità dei dati ed è un'utile aggiunta a qualsiasi piattaforma di Big Data.
Cerchi un'infrastruttura di storage con object storage abbastanza veloce da supportare il tuo Delta Lake? Continua a leggere per scoprire come creare un lakehouse di dati aperti con Delta Lake e FlashBlade ®.
Potrebbe interessarti anche...
Esplora risorse ed eventi principali

TRADESHOW
Pure//Accelerate® 2026
June 16-18, 2026 | Resorts World Las Vegas
Preparati all'evento più importante a cui parteciperai quest'anno.

DEMO DI PURE360
Esplora, scopri e prova Pure Storage.
Accedi a video e demo on demand per scoprire i vantaggi che Pure Storage ti offre.

VIDEO
Guarda: Il valore di un Enterprise Data Cloud (EDC).
Charlie Giancarlo spiega perché il futuro è nella gestione dei dati, non dello storage. Scopri in che modo un approccio unificato trasforma le operazioni IT aziendali.

RISORSA
Lo storage legacy non può alimentare il futuro.
I workload moderni richiedono velocità, sicurezza e scalabilità AI-ready. Il tuo stack è pronto?
Personalize for Me