Dismiss
Innovación
Una plataforma diseñada para la IA
Unificada, automatizada y preparada para convertir los datos en inteligencia.
Dismiss
16-18 de junio, Las Vegas
Pure//Accelerate® 2026
Descubra cómo extraer el verdadero valor de sus datos.
¿Qué es Delta Lake? Una descripción general

Delta Lake es un marco de almacenamiento de datos de código abierto diseñado para optimizar la fiabilidad y el rendimiento de los lagos de datos. Aborda algunos de los problemas comunes a los que se enfrentan los lagos de datos, como la coherencia de los datos, la calidad de los datos y la falta de transaccionalidad. Su objetivo es proporcionar una solución de almacenamiento de datos que pueda manejar cargas de trabajo de macrodatos escalables en una empresa basada en datos.
Orígenes del lago Delta
Delta Lake fue lanzado por Databricks, una empresa de Apache Spark, en 2019 como un formato de tabla en la nube basado en estándares abiertos y parcialmente en código abierto para soportar las características a menudo solicitadas de las plataformas de datos modernas, como las garantías ACID, los reescritores simultáneos, la mutabilidad de datos y más.
¿Cuál es el propósito o el uso principal de Delta Lake?
Delta Lake se creó para soportar y mejorar el uso de los lagos de datos, que contienen grandes cantidades de datos estructurados y no estructurados.
Los científicos y analistas de datos utilizan lagos de datos para manipular y extraer información valiosa de estos conjuntos de datos masivos. Los lagos de datos han revolucionado el modo en que gestionamos los datos, pero también tienen algunas limitaciones, como la calidad de los datos, la coherencia de los datos y, la principal, la falta de esquemas forzados, lo que dificulta la realización de operaciones de aprendizaje automático y analíticas complejas en los datos brutos.
En 2021, los científicos de datos del ámbito académico y tecnológico argumentaron que, debido a estas limitaciones, los lagos de datos pronto serían sustituidos por “lagos”, que son plataformas abiertas que unifican el almacenamiento de datos y los análisis avanzados.
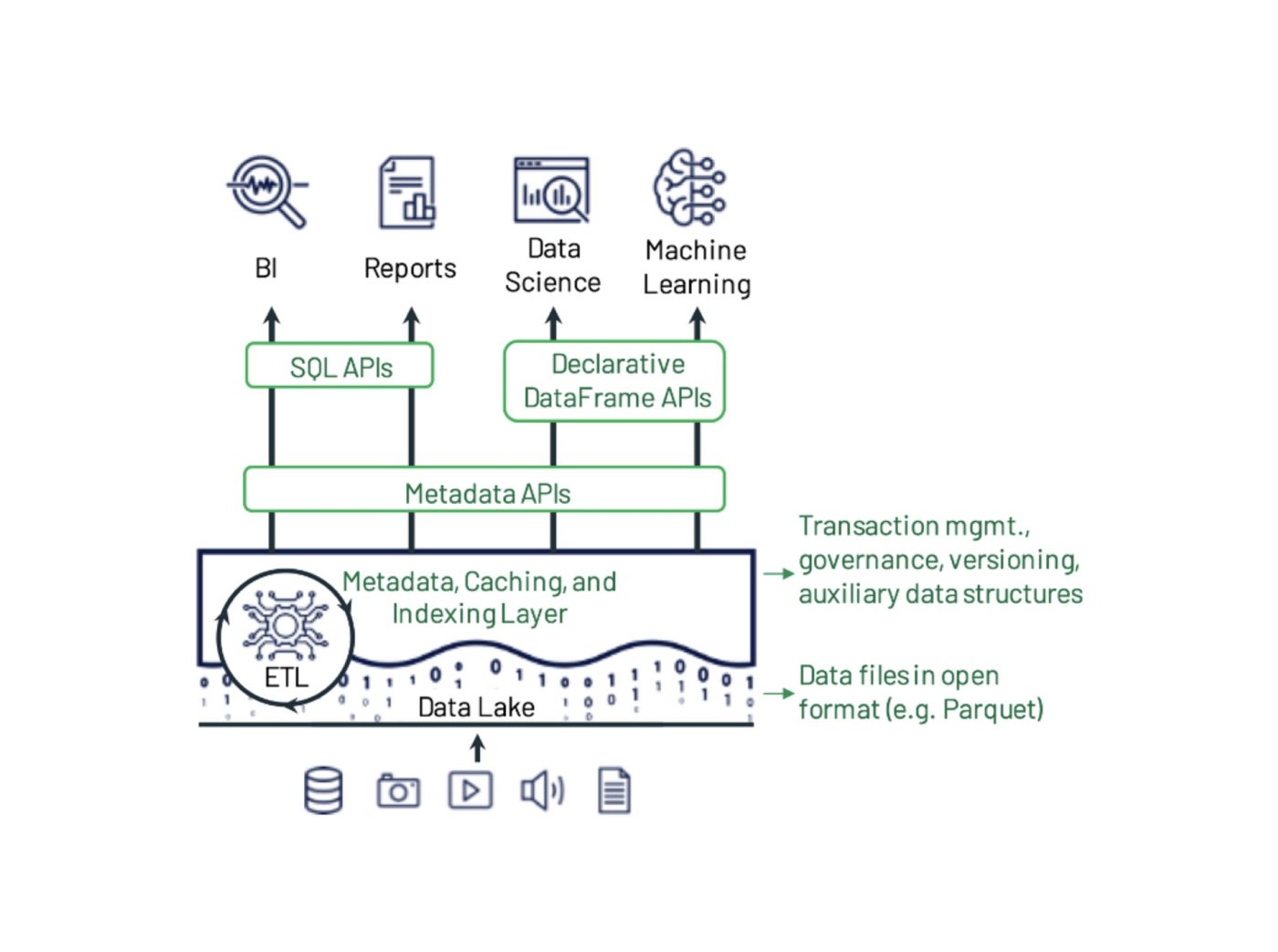
Figura 1: Ejemplo de diseño de sistema de data lakehouse del artículo de Michael Armbrust, Ali Ghodsi, Reynold Xin y Matei Zaharia. Delta Lake añade transacciones, control de versiones y estructuras de datos auxiliares sobre archivos en un formato abierto y puede consultarse con diversas API y motores.
Delta Lake es una parte importante de cualquier infraestructura de lakehouse al proporcionar una capa de almacenamiento de datos clave.
Delta Lake se define por:
- La franqueza: Se trata de un ecosistema de integración en rápida expansión, impulsado por la comunidad.
- Simplicidad: Proporciona un formato único para unificar su ETL, el almacén de datos y el aprendizaje automático en su lago.
- Preparado para la producción: Se ha probado en batalla en más de 10 000 entornos de producción.
- Independiente de la plataforma: Puede usarlo con cualquier motor de consultas en cualquier nube, local o local.
Delta Lake vs Data Lake vs Data Warehouse vs Data Lakehouse
Es mejor entender un lago Delta en el contexto más amplio del centro de datos, sobre todo cómo encaja junto con los lagos de datos, los almacenes de datos y las casas de los lagos de datos. Echemos un vistazo más de cerca:
Delta Lake
Delta Lake es una capa de almacenamiento de código abierto que conserva la integridad de sus datos originales sin sacrificar el rendimiento y la agilidad necesarios para las aplicaciones de análisis en tiempo real, inteligencia artificial (IA) y aprendizaje automático (ML).
Lago de datos
Un lago de datos es un repositorio de datos brutos en múltiples formatos. El volumen y la variedad de información de un lago de datos pueden dificultar el análisis y comprometer la calidad y la fiabilidad de los datos.
Almacén de Datos
Un almacén de datos recoge información de múltiples fuentes y luego la reformatea y la organiza en un gran volumen consolidado de datos estructurados, optimizado para el análisis y la elaboración de informes. El software patentado y la incapacidad para almacenar datos no estructurados pueden limitar su utilidad.
Data Lakehouse
Un data lakehouse es una plataforma de datos moderna que combina la flexibilidad y la escalabilidad de un lago de datos con las características de estructura y gestión de un almacén de datos en una plataforma sencilla y abierta.

Pruebe FlashBlade
Experimente una instancia de autoservicio de Pure1® para gestionar FlashBlade™ de Pure, la solución más avanzada del sector que proporciona almacenamiento nativo y escalable horizontalmente de archivos y objetos.
¿Cómo funciona Delta Lake?
Delta Lake funciona creando una capa adicional de abstracción entre los datos brutos y los motores de procesamiento. Se encuentra sobre un lago de datos y utiliza su sistema de almacenamiento. Divide los datos en lotes y luego agrega las transacciones ACID encima de los lotes. Delta Lake también permite la aplicación del esquema para la validación de los datos antes de añadirlos al lago.
Delta Lake almacena los datos en formato Parquet y utiliza el Hadoop Distributed File System (HDFS) o Amazon S3 como capa de almacenamiento. La capa de almacenamiento almacena los datos en archivos Parquet inmutables, que se versionan para permitir la evolución del esquema.
¿Cómo mejora Delta Lake el rendimiento de los datos mediante la indexación?
Delta Lake mejora el rendimiento de los datos al crear índices sobre los datos a los que se accede con frecuencia. Estos índices permiten un tiempo de recuperación de datos más rápido y ayudan a optimizar el rendimiento. Si bien cada base de datos utiliza indexación, Delta Lake es única, ya que utiliza una combinación de análisis automático de metadatos y diseño de datos físicos para reducir el número de archivos escaneados para satisfacer cualquier consulta.
Arquitectura de Delta Lake
Delta Lake es una capa de datos añadida y representa una evolución de la arquitectura lambda, en la que el streaming y el procesamiento por lotes se producen en paralelo y los resultados se fusionan para proporcionar una respuesta a la consulta. Este método añade complejidad y dificultad para mantener y operar los procesos de transmisión y por lotes.
Delta Lake utiliza una arquitectura de datos continua que combina flujos de trabajo de transmisión y lotes en un almacén de archivos compartido a través de una canalización conectada. El archivo de datos almacenado tiene tres capas, llamadas “arquitectura multihop”, y los datos se refinan a medida que se mueven aguas abajo en el flujo de datos:
- Las tablas de bronce contienen los datos brutos ingeridos de múltiples fuentes, como los sistemas de Internet de las cosas (IoT CRM, RDBMS y archivos JSON.
- Las tablas Silver contienen una vista más refinada de nuestros datos después de realizar transformaciones y de presentar procesos de ingeniería.
- Las tablas Gold son para los usuarios finales de informes, análisis o procesos de aprendizaje automático de BI.
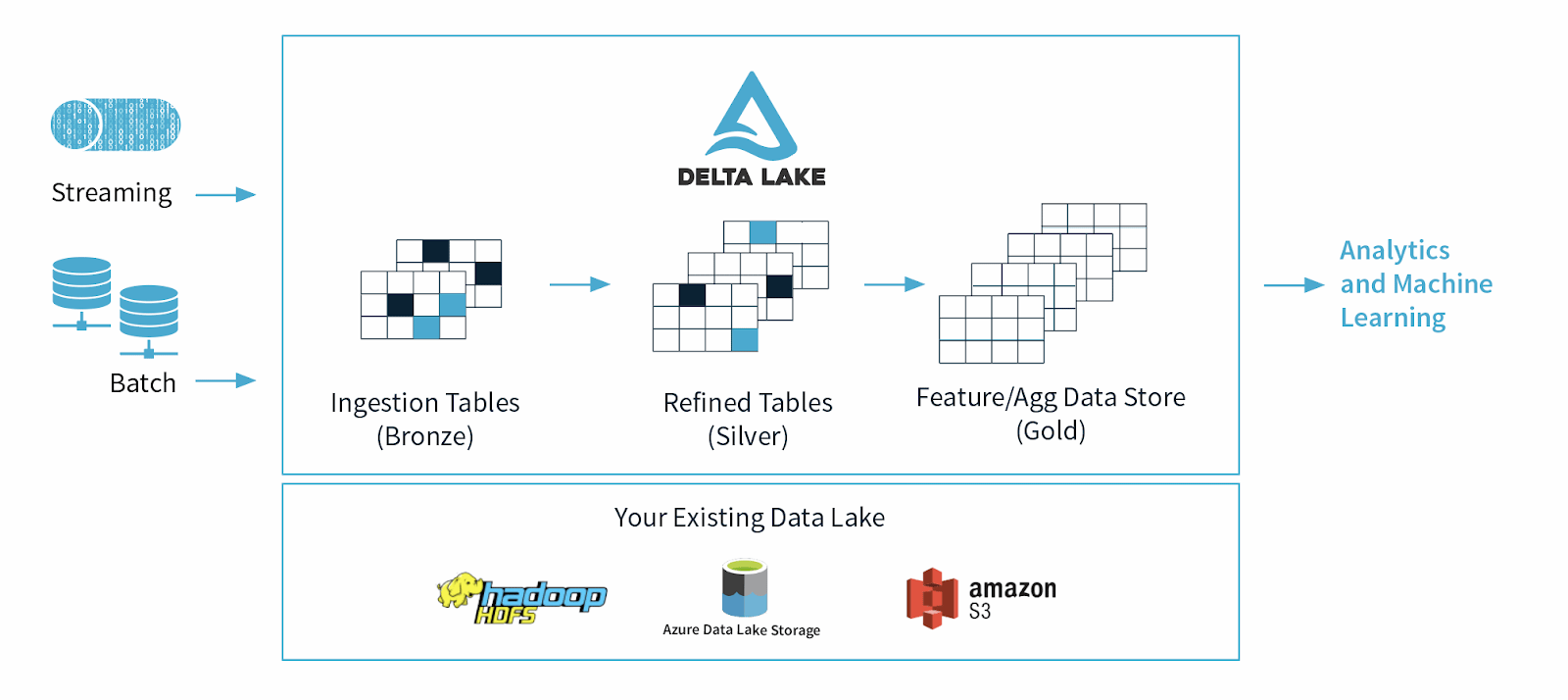
Figura 2: Arquitectura de Delta Lake.
Ventajas de Delta Lake
Delta Lake puede beneficiar a cualquier empresa que dependa de soluciones de macrodatos sólidas, incluidas las de finanzas, atención sanitaria y comercio minorista.
Los beneficios principales de Delta Lake incluyen:
- Mejor fiabilidad de los datos: Delta Lake proporciona garantías transaccionales y aislamiento de copias instantáneas, lo que mejora la fiabilidad de los datos. Además, los usuarios pueden revertir las transacciones fallidas sin afectar a otras transacciones exitosas. Delta Lake utiliza mecanismos de control de versiones para añadir nuevos datos al lago de datos sin afectar a los datos existentes.
- Soporte de la evolución del esquema: Delta Lake puede soportar la evolución del esquema en los conjuntos de datos. Gestiona los cambios de esquema guardando un historial de versiones del esquema de datos y permite que los usuarios actualicen el esquema antes de escribir los datos. Delta Lake también comprueba la validación del esquema de datos antes de escribir los datos.
- Compatibilidad: Delta Lake es compatible con varios motores de procesamiento de macrodatos, incluidos Apache Spark, Hadoop y Amazon EMR. Delta Lake también viene integrado con consultas tipo SQL, lo que permite que los usuarios manipulen y extraigan información de los conjuntos de datos.
Todos estos beneficios ayudan a hacer de Delta Lake una solución de almacenamiento de datos importante.
Desventajas de Delta Lake
Si bien Delta Lake tiene muchos beneficios, también tiene algunos inconvenientes, incluidos:
- No es ideal para los datos no estructurados: Si no se enfrenta a grandes cantidades de datos no estructurados o tiene una pequeña necesidad de almacenamiento de datos, Delta Lake puede no ser la mejor solución para usted. Las soluciones de almacenamiento de datos tradicionales pueden ser más sencillas de implementar y más rentables.
- No es fácil de aprender: Si bien Delta Lake es una solución excelente para las cargas de trabajo de macrodatos, puede requerir recursos de desarrollo adicionales y tiempo para implementarla. Además, hay una curva de aprendizaje pronunciada para los usuarios que son nuevos en la plataforma.
Cómo conseguir e implementar Delta Lake
Puede obtener Delta Lake de varias fuentes posibles, incluidos los repositorios Apache Spark de GitHub , el sitio web de Delta Lake y las aplicaciones populares de terceros, como Databricks. Delta Lake se implementa al añadirlo como motor de procesamiento a un clúster de macrodatos existente, como Apache Spark, Hadoop o Amazon EMR .
Conclusión
Delta Lake es una solución excelente para las cargas de trabajo de macrodatos que permite que los usuarios gestionen conjuntos de datos no estructurados de manera fiable. Proporciona características como transacciones ACID, validación de esquema e integración API. Si bien Delta Lake tiene algunos requisitos de almacenamiento general, puede manejar el escalamiento de una empresa basada en datos de manera efectiva. Delta Lake proporciona un marco sólido para mejorar la calidad y la fiabilidad de los datos y es una incorporación útil a cualquier plataforma de macrodatos.
¿Busca una infraestructura de almacenamiento con un almacenamiento de objetos lo suficientemente rápido como para soportar su Delta Lake? Siga leyendo para descubrir cómo construir un data lakehouse abierto con Delta Lake y FlashBlade ®.
Te recomendamos...
Explore los recursos y eventos clave

FERIA COMERCIAL
Pure//Accelerate® 2026
June 16-18, 2026 | Resorts World Las Vegas
Prepárese para el evento más valioso al que asistirá este año.

DEMOS DE PURE360
Explore, aprenda y experimente Everpure.
Acceda a vídeos y demostraciones bajo demanda para ver lo que Everpure puede hacer.

VÍDEO
Ver: El valor de Enterprise Data Cloud.
Charlie Giancarlo explica por qué la gestión de los datos —y no del almacenamiento— es el futuro. Descubra cómo un enfoque unificado transforma las operaciones de TI de la empresa.

RECURSO
El almacenamiento tradicional no puede impulsar el futuro.
Las cargas de trabajo modernas exigen velocidad, seguridad y escala preparadas para la IA. ¿Su stack está listo?
Personalize for Me