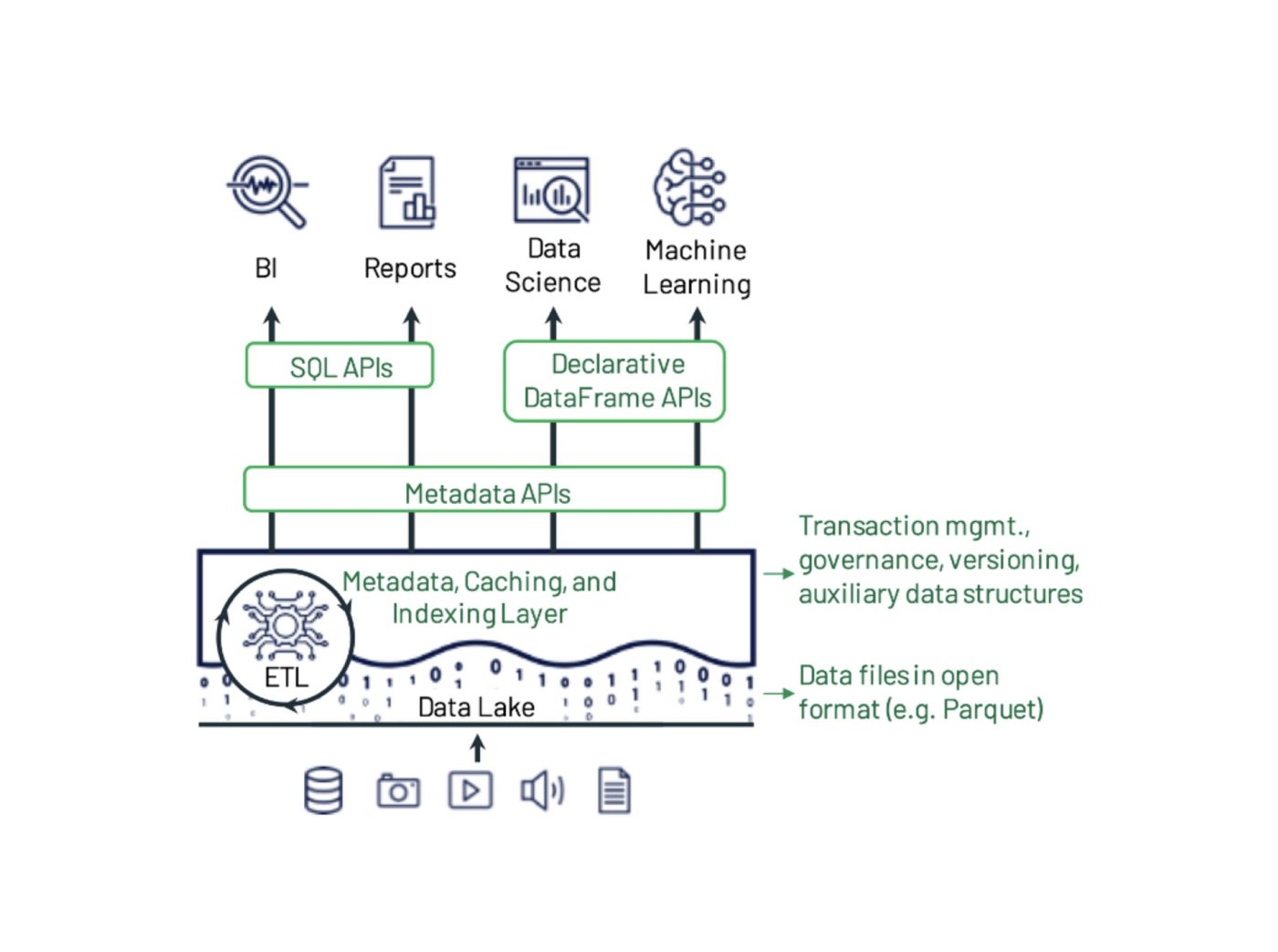
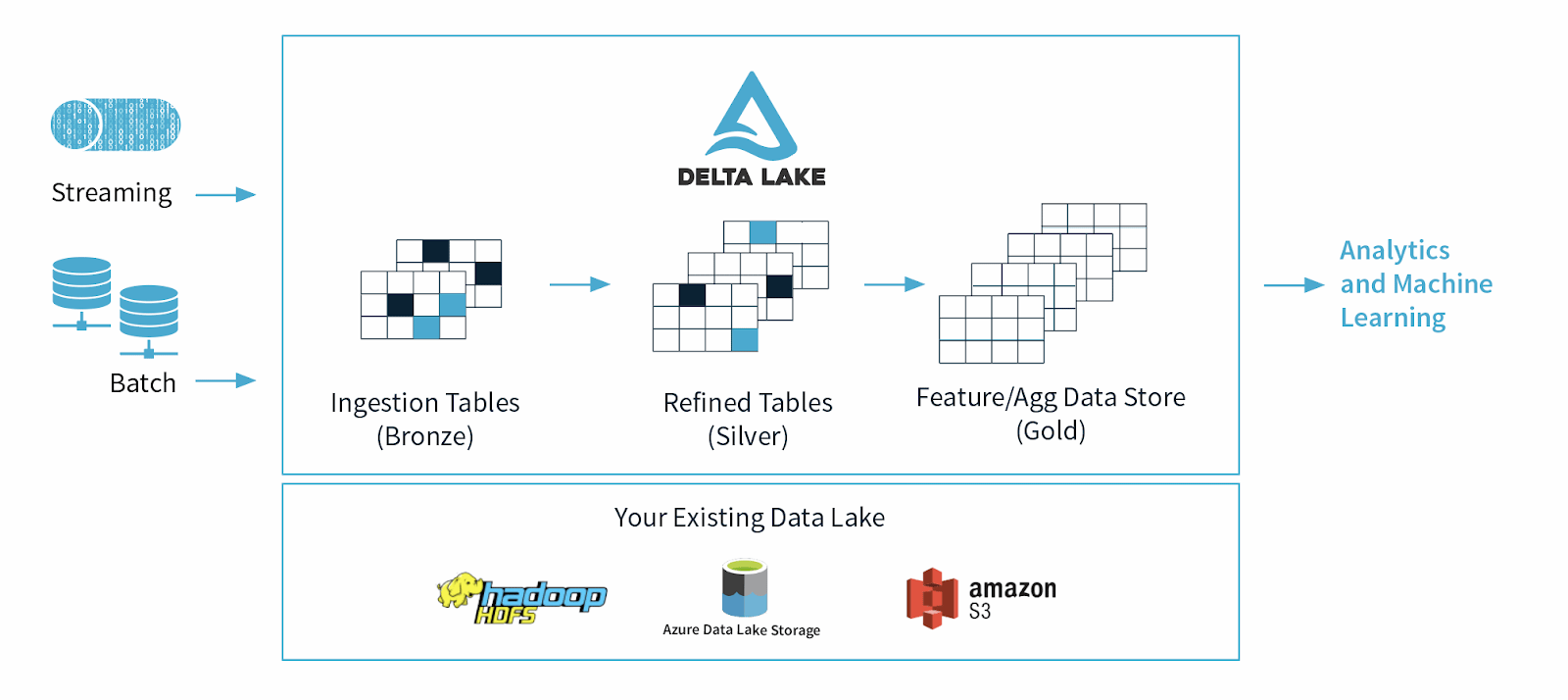
Delta Lake のメリット
Delta Lake は、金融、ヘルスケア、小売などの堅牢なビッグデータ・ソリューションに依存するあらゆる企業にメリットをもたらします。
Delta Lake の主なメリット:
- データの信頼性の向上:Delta Lake は、トランザクションの保証とスナップショットの分離を提供し、データの信頼性を向上させます。さらに、失敗したトランザクションをロールバックしても、他のトランザクションに影響はありません。Delta Lake は、バージョン管理メカニズムを使用して、既存のデータに影響を与えることなく、データレイクに新しいデータを追加します。
- スキーマの進化をサポート:Delta Lake は、データセットにおけるスキーマの進化をサポートできます。データスキーマのバージョン履歴を保存することでスキーマの変更を処理し、データを書き込む前にスキーマを更新できます。また、データを書き込む前に、データ・スキーマの検証もチェックします。
- 互換性:Delta Lake は、Apache Spark、Hadoop、Amazon EMR など、さまざまなビッグデータ処理エンジンと互換性があります。Delta Lake は SQL のようなクエリとも統合されており、データセットの操作やインサイトの抽出を可能にします。
これらのメリットは、Delta Lake を重要なデータ・ストレージ・ソリューションにするのに役立ちます。
Delta Lake の欠点
Delta Lake には多くのメリットがありますが、次のような欠点もあります。
- 非構造化データには適していない:大量の非構造化データを扱う場合や、データ・ストレージの必要性が少ない場合は、Delta Lake が最適なソリューションとは言えません。従来のデータ・ストレージ・ソリューションの方が、実装が容易でコスト効率に優れています。
- 学習が容易ではない:Delta Lake はビッグデータのワークロードに最適なソリューションですが、追加の開発リソースと実装時間が必要になる場合があります。さらに、プラットフォームに慣れていないユーザーのための急激な学習曲線があります。
Delta Lake の導入方法
Delta Lake は、GitHub の Apache Spark リポジトリ、Delta Lake の Web サイト、Databricks のようなサードパーティ・アプリケーションなど、さまざまなソースから入手できます。Delta Lake は、Apache Spark、Hadoop、Amazon EMR などの既存のビッグデータ・クラスタに処理エンジンとして追加することで実装されます。
まとめ
Delta Lake は、ビッグデータのワークロードに最適なソリューションです。非構造化データセットを確実に管理できます。ACID トランザクション、スキーマ検証、API 統合などの機能を提供します。Delta Lake にはオーバーヘッド・ストレージの要件がありますが、データ駆動型ビジネスのスケーリングを効果的に処理できます。Delta Lake は、データの品質と信頼性を向上させる堅牢なフレームワークを提供し、ビッグデータ・プラットフォームに有用な追加要素です。
Delta Lake をサポートするのに十分に高速なオブジェクト・ストレージを備えたストレージ・インフラをお探しですか? Delta Lake と FlashBlade でオープンデータ・レイクハウスを構築する方法について詳しくは、こちらをご覧ください。