Dismiss
Innovatie
Een platform, gebouwd voor AI
Unified, geautomatiseerd en klaar om data om te zetten in informatie.
Dismiss
16-18 juni, Las Vegas
Pure//Accelerate® 2026
Ontdek hoe u de ware waarde van uw gegevens kunt ontsluiten.
Wat is Delta Lake? Een overzicht

Delta Lake is een open source dataopslagframework dat is ontworpen om de betrouwbaarheid en prestaties van datalakes te optimaliseren. Het pakt enkele van de veelvoorkomende problemen aan waarmee datalakes worden geconfronteerd, zoals dataconsistentie, datakwaliteit en gebrek aan transactionaliteit. Het doel is om een oplossing voor dataopslag te bieden die schaalbare, big data-workloads kan verwerken in een datagedreven bedrijf.
Delta Lake Origins
Delta Lake werd in 2019 gelanceerd door Databricks, een Apache Spark-bedrijf, als een cloud table-formaat gebouwd op open standaarden en gedeeltelijk open source ter ondersteuning van de gevraagde functies van moderne dataplatforms, zoals ACID-garanties, gelijktijdige herschrijvers, datamutabiliteit en meer.
Wat is het doel of het belangrijkste gebruik van Delta Lake?
Delta Lake is gebouwd om het gebruik van datalakes te ondersteunen en te verbeteren, die enorme hoeveelheden zowel gestructureerde als ongestructureerde data bevatten.
Datawetenschappers en dataanalisten gebruiken datalakes om waardevolle inzichten uit deze enorme datasets te manipuleren en te extraheren. Hoewel datalakes een revolutie teweeg hebben gebracht in de manier waarop we data beheren, hebben ze ook een aantal beperkingen, waaronder datakwaliteit, dataconsistentie en, de primaire, een gebrek aan afgedwongen schema's, waardoor het moeilijk is om machine learning en complexe analytische activiteiten uit te voeren op ruwe data.
In 2021 voerden datawetenschappers uit zowel de academische wereld als de technologie aan dat, vanwege deze beperkingen, datalakes binnenkort zouden worden vervangen door "lakehouses", open platforms die datawarehousing en geavanceerde analyses verenigen.
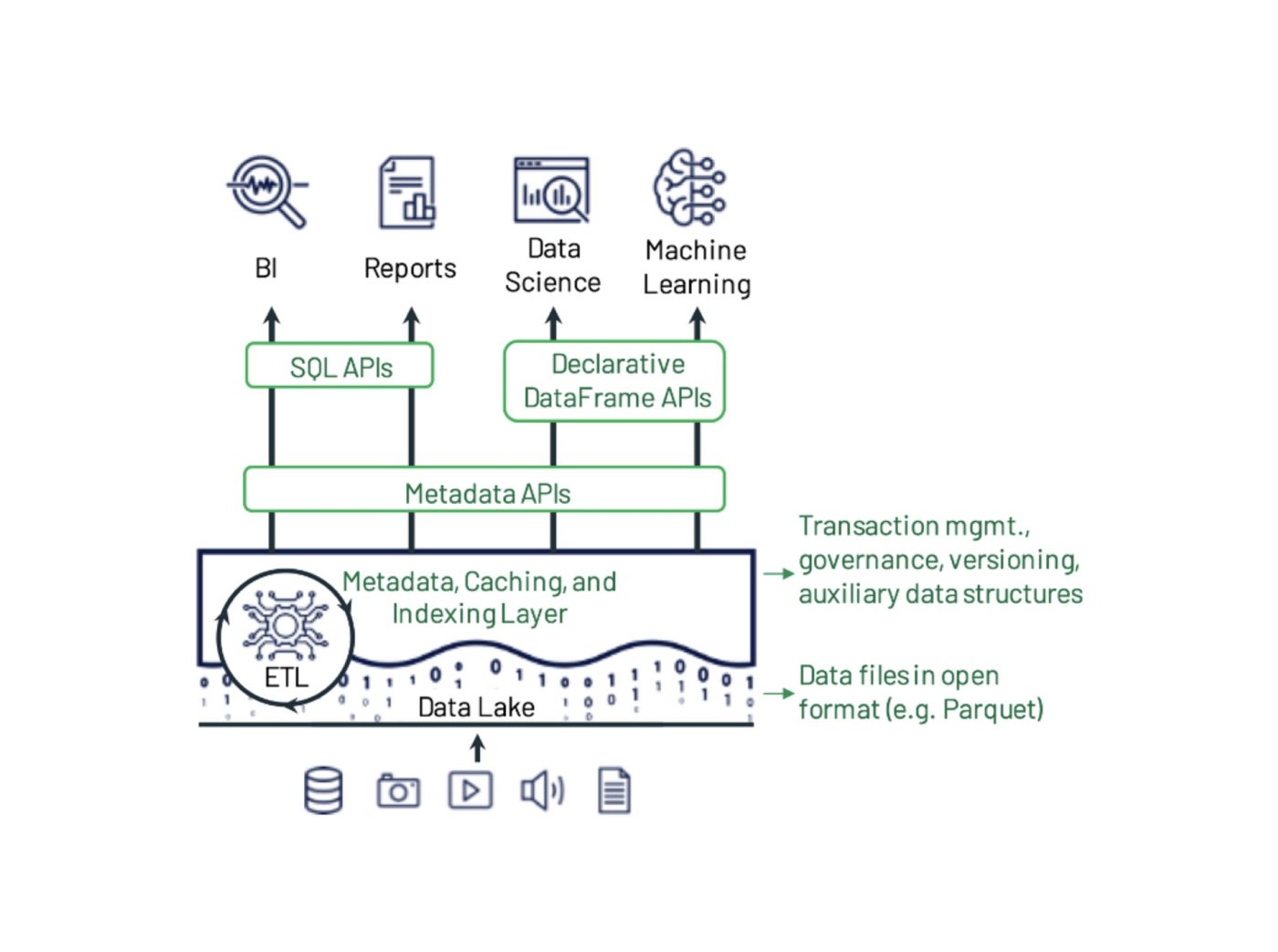
Afbeelding 1: Voorbeeld van het ontwerp van data lakehousesystemen op basis van de paper van Michael Armbrust, Ali Ghodsi, Reynold Xin en Matei Zaharia. Delta Lake voegt transacties, versiebeheer en aanvullende datastructuren toe aan bestanden in een open formaat en kan worden opgevraagd met diverse API's en engines.
Delta Lake is een belangrijk onderdeel van elke meerhuisinfrastructuur door een belangrijke dataopslaglaag te bieden.
Delta Lake wordt gedefinieerd door:
- Openheid: Het is een snel groeiend integratie-ecosysteem dat gemeenschapsgestuurd is.
- Eenvoud: Het biedt één enkel formaat om uw ETL, datawarehouse en machine learning in uw meerhuis te verenigen.
- Klaar voor productie: Het is in de strijd getest in meer dan 10.000 productieomgevingen.
- Platform-agnostisch: U kunt het gebruiken met elke query-engine op elke cloud, on-prem of lokaal.
Delta Lake vs. Data Lake vs. Data Warehouse vs. Data Lakehouse
Een Delta Lake kan het best worden begrepen binnen de bredere context van het datacenter, met name hoe het past in de buurt van datalakes, datawarehouses en datalakeshuizen. Laten we eens nader kijken:
Delta Lake
Delta Lake is een open-source opslaglaag die de integriteit van uw oorspronkelijke data behoudt zonder dat dit ten koste gaat van de prestaties en flexibiliteit die nodig zijn voor realtime analytics, artificiële intelligentie (AI) en machine learning (ML)-applicaties.
Data Lake
Een datalake is een opslagplaats van ruwe data in meerdere formaten. Het volume en de verscheidenheid aan informatie in een datalake kan analyse moeilijk maken en de kwaliteit en betrouwbaarheid van data in gevaar brengen.
Datawarehouse
Een datawarehouse verzamelt informatie uit meerdere bronnen, herformatteert en organiseert deze vervolgens in een groot, geconsolideerd volume van gestructureerde data dat is geoptimaliseerd voor analyse en rapportage. Bedrijfseigen software en het niet kunnen opslaan van ongestructureerde data kunnen het nut ervan beperken.
Data Lakehouse
Een datalakehouse is een modern dataplatform dat de flexibiliteit en schaalbaarheid van een datalake combineert met de structuur- en beheerfuncties van een datawarehouse in een eenvoudig, open platform.

Probeer FlashBlade
Ervaar self-service met Pure1® voor het beheer van Pure FlashBlade™, de meest geavanceerde oplossing in de industrie die native scale-out file- en object storage biedt.
Hoe werkt Delta Lake?
Delta Lake creëert een extra laag abstractie tussen de ruwe data en de verwerkingssystemen. Het bevindt zich bovenop een datalake en maakt gebruik van het opslagsysteem. Het verdeelt data in batches en voegt vervolgens ACID-transacties toe bovenop de batches. Delta Lake maakt ook schemahandhaving voor datavalidatie mogelijk voordat het aan het meer wordt toegevoegd.
Delta Lake slaat data op in parketformaat en gebruikt het Hadoop Distributed File System (HDFS) of Amazon S3 als opslaglaag. De opslaglaag slaat data op in onveranderlijke parketbestanden, die zijn geversieerd om schema-evolutie mogelijk te maken.
Hoe verbetert Delta Lake de dataprestaties door middel van indexering?
Delta Lake verbetert de dataprestaties door indexen te maken bovenop vaak gebruikte data. Deze indexen maken snellere data-ophaaltijd mogelijk en helpen de prestaties te optimaliseren. Hoewel elke database indexering gebruikt, is Delta Lake uniek omdat het een combinatie van automatische Metadata parseringen fysieke datalay-out gebruikt om het aantal gescande bestanden te verminderen om aan elke query te voldoen.
Delta Lake-architectuur
Delta Lake is een extra datalaag en vertegenwoordigt een evolutie van de lambda-architectuur, waarbij streaming en batchverwerking parallel plaatsvinden en de resultaten samengaan om een query-antwoord te geven. Deze methode voegt complexiteit en moeite toe aan het onderhouden en bedienen van de streaming- en batchprocessen.
Delta Lake maakt gebruik van een continue dataarchitectuur die streaming- en batchworkflows combineert in een gedeelde bestandsopslag via een verbonden pijplijn. Het opgeslagen databestand heeft drie lagen, ook wel een "multi-hop-architectuur" genoemd, en de data worden verfijnder naarmate ze zich downstream in de dataflow verplaatsen:
- Bronzen tabellen bevatten de ruwe data die uit meerdere bronnen worden opgenomen, zoals het Internet of Things (IoT)-systemen, CRM, RDBMS en JSON-bestanden.
- Zilveren tabellen bevatten een meer verfijnd beeld van onze data na het ondergaan van transformatie en technische processen.
- Gold-tabellen zijn voor eindgebruikers voor BI-rapportage, -analyse of machine learning-processen.
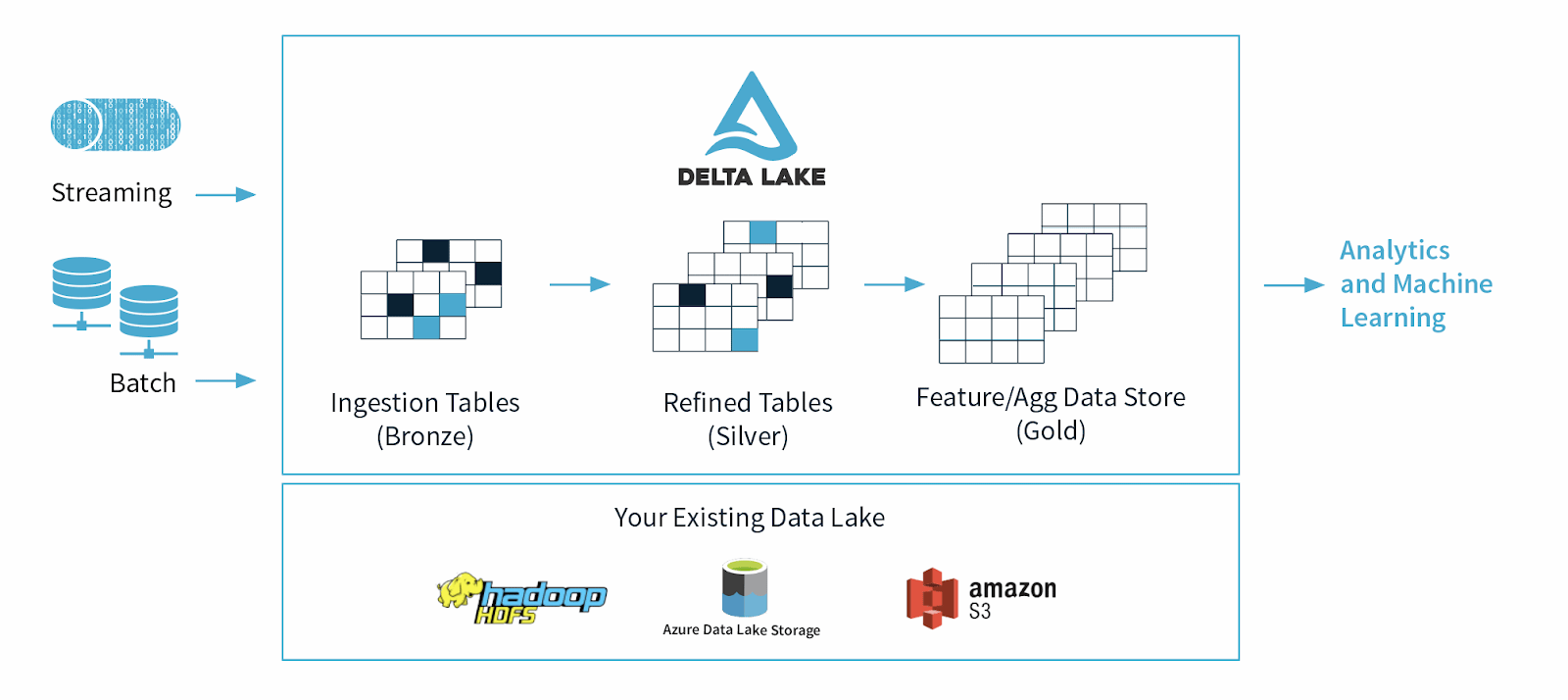
Figuur 2: Delta Lake-architectuur.
Voordelen van Delta Lake
Delta Lake kan elk bedrijf ten goede komen dat vertrouwt op robuuste big data-oplossingen, waaronder die in financiën, gezondheidszorg en retail.
De belangrijkste voordelen van Delta Lake zijn onder andere:
- Betere databetrouwbaarheid: Delta Lake biedt transactionele garanties en snapshot-isolatie, waardoor de betrouwbaarheid van data wordt verbeterd. Bovendien kunnen gebruikers mislukte transacties terugdraaien zonder andere succesvolle transacties te beïnvloeden. Delta Lake gebruikt versiebeheermechanismen om nieuwe data toe te voegen aan het datalake zonder bestaande data te beïnvloeden.
- Ondersteuning van schema-evolutie: Delta Lake kan schema-evolutie in datasets ondersteunen. Het verwerkt schemawijzigingen door een versiegeschiedenis van het dataschema op te slaan en stelt gebruikers in staat om het schema bij te werken voordat ze de data schrijven. Delta Lake controleert ook op validatie van het dataschema voordat de data worden geschreven.
- Compatibiliteit: Delta Lake is compatibel met verschillende big data-verwerkingsengines, waaronder Apache Spark, Hadoop en Amazon EMR. Delta Lake wordt ook geïntegreerd met SQL-achtige queries, waardoor gebruikers inzichten uit de datasets kunnen manipuleren en extraheren.
Al deze voordelen maken van Delta Lake een belangrijke oplossing voor dataopslag.
Nadelen van Delta Lake
Hoewel Delta Lake veel voordelen heeft, heeft het ook een aantal nadelen, waaronder:
- Niet ideaal voor ongestructureerde data: Als u niet te maken hebt met grote hoeveelheden ongestructureerde data of een kleine behoefte hebt aan dataopslag, is Delta Lake misschien niet de beste oplossing voor u. Traditionele data-opslag oplossingen kunnen eenvoudiger te implementeren en kosteneffectiever zijn.
- Niet gemakkelijk te leren: Hoewel Delta Lake een uitstekende oplossing is voor big data-workloads, kan het extra ontwikkelingsmiddelen en -tijd vereisen om te implementeren. Daarnaast is er een steile leercurve voor gebruikers die nieuw zijn op het platform.
Hoe u Delta Lake kunt krijgen en implementeren
U kunt Delta Lake uit verschillende mogelijke bronnen verkrijgen, waaronder Apache Spark-opslagplaatsen van GitHub, de Delta Lake-website en populaire applicaties van derden, zoals Databricks. Delta Lake wordt geïmplementeerd door het toe te voegen als een verwerkingsengine aan een bestaand big data-cluster, zoals Apache Spark, Hadoop of Amazon EMR.
Conclusie
Delta Lake is een uitstekende oplossing voor big data-workloads waarmee gebruikers ongestructureerde datasets betrouwbaar kunnen beheren. Het biedt functies zoals ACID-transacties, schemavalidatie en API-integratie. Hoewel Delta Lake een aantal overhead opslagvereisten heeft, kan het de schaalbaarheid van een datagedreven bedrijf effectief aan. Delta Lake biedt een robuust kader om de kwaliteit en betrouwbaarheid van data te verbeteren en is een nuttige aanvulling op elk big data-platform.
Op zoek naar opslaginfrastructuur met objectopslag die snel genoeg is om uw Delta Lake te ondersteunen? Lees verder om te leren hoe u een open datalakehouse kunt bouwen met Delta Lake en FLASHBLADE ®.
Wij bevelen ook aan...
Blader door belangrijke resources en evenementen

BEURS
Pure//Accelerate® 2026
June 16-18, 2026 | Resorts World Las Vegas
Maak je klaar voor het meest waardevolle evenement dat je dit jaar zult bijwonen.

PURE360 DEMO’S
Ontdek, leer en ervaar Everpure.
Krijg toegang tot on-demand video's en demo's om te zien wat Everpure kan doen.

VIDEO
Bekijk: De waarde van een Enterprise Data Cloud
Charlie Giancarlo over waarom het beheren van data en niet opslag de toekomst zal zijn. Ontdek hoe een uniforme aanpak de IT-activiteiten van bedrijven transformeert.

RESOURCE
Legacy-storage kan de toekomst niet aandrijven.
Moderne workloads vragen om AI-ready snelheid, beveiliging en schaalbaarheid. Is uw stack er klaar voor?
Personalize for Me