Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
17:37 Video
Everpure Purity ActiveDR - Always-on Protection and Recovery
Explore a continuous replication, non-synchronous solution in Purity//FA that provides minimal data loss, and can work across any distance, while making failover and failback very simple.
Click to View Transcript
Hello everybody. Thank you for joining us for this session on active VR for file. I'm Jonathan, I'm a senior product manager here at pier storage for file services and I'm vin, I'm senior product manager for data protection at pure storage here is a very customer driven organization and the story of Factor V R is quite unique.
This happens when my team was working with a financial client in New Jersey and as usual at practice, we were discussing with them some data protection solutions that they could use for their enterprise. We discussed with them that snapshot based isn't gonna solution. We also discussed with them the high availability active cluster solution but the
client turned around and told my team guys we have learned a lot from Hurricane Sandy. Now my data center set in New Jersey and Alice, can you give me an option that walks across that distance with minimal data loss and empowers my team to confidently say they can bring back the business very simply without going through an instruction manual. My team took that back to pure Engineering and
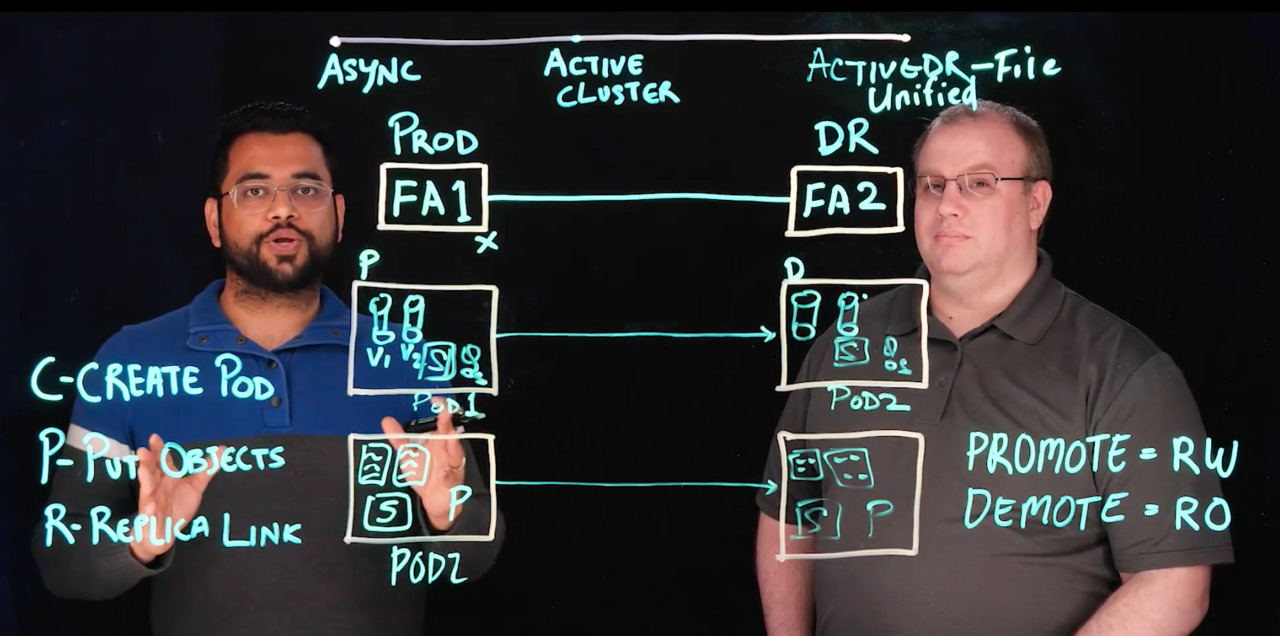
we came back with active D R after D R is a continuous replication solution that provides minimal data loss. It is a non synchronous solution so it does not have a write latency and can work across any distance and we build it from ground up to make feel lower and feel back, very simple in just two commands. The first prerequisite for any replication
solution is to have to flash arrays. So in this example I have flash everyone, which is let's consider our prod site and flattery to which is over the our side, you just need to make sure that these are connected over replication connection. Once we have that much, all I tell my customers is to prepare for D R.
Remember to do cpr and it's an easy way to remember the setup steps, C stands for creating a part. So in this example We have 41 which is on the outside and pods are nothing but a logical container to grow up and hold the objects that you want to replicate together. The second step is to put the objects in this
pod. So in the block world, let's say we want to replicate volumes. So I will put or move in those volumes within that part. Can you do this with existing data non destructively. And that's a good question because we can do it with existing volumes that are on your flash
array non destructively. So you can move those into this pod at any point of time when you want, you can also create volumes directly within this pod and replicate those as well. Now in the D. R. Scenario, I know we want to have more than just data. What else can you replicate?
And that's true in the real world scenario, while data is the most important thing, you can also have some other data protection policies that are associated with these volumes. So you can have snapshots that are equally important and you have defined them here. You want them to be exactly the same on the D. R side as well. And you can also have some que os limits that you're defining associated with these
volumes because they ensure the quality of service that you provide to your host and your applications and you want them replicated too. So that when an actual GR happens you get exactly the same kind of behavior for your d our hosts and applications don't worry about mainly sinking those now. I think that's where the world of file is a little bit different because you have different objects.
We do so we follow suit pretty much to exactly how you're doing it. We do a pod. So you would have for example Pod two. And then we are able to do final systems within a pod. You know, you have one or more and again, just like you guys, you know, these can be moved, you know, these can be existing file systems,
new file systems, you can move them in non destructively. Now the configuration part profile is also slightly different. We are able to bring over all of our snapshots into the pot as well. And these are directory snapshots. So all those directory snapshots, if they're attached to any of these final systems, they would also appear inside the pot
and be there and then we have some data management tools, we call policy policies and the two policies that we wanted to be able to replicate is quote directory quota policies that way, when you're controlling, you know where your data is that on your source, you can have that same experience on the other side and the other one is the snapshot scheduling retention policies. We wanna be able to replicate those as well.
That's awesome. Based on either your block or file, there are different kinds of objects but essentially you're putting those objects into the parts. Exactly very celebrated. You don't have to learn anything new. It's exactly the similar behavior. Right? That's awesome.
So now the third step and the final step is the replica link which means that now you want to replicate, you want to set up a replica connection between this part with a remote part On the remote area. And in this case let's say there is part one and I'm creating the replica wing with part to have to recreate that. No, you don't.
So we have designed the customer journey or the or the setup journey completely source driven. So you're not hopping between your prod and D r raise. You can do all the setup completely from your source. And you can also define that the system should create a new part on the remote side which becomes the container for holding the replication of all these objects which are four
blocks and four file in their respective pods to hop around. It's really nice. I know. So once you set up your replica link and let me do it for your files as well. We will start seeing the same objects on the replica side.
Mm hmm. And that's it. You have essentially executed three steps to set up a real DVR solution for your environment using these two flash arrays. So earlier you asked me why we chose Active here. This is one of the main reasons. It's so simple and figure three step setup and
you're ready to go and it's replicating. Now, I don't have any schedules, right? You don't have to do any schedules because it's continuous. I don't have to prioritize pods. No, you don't have to prioritize pods. You don't have to do any scheduling. Once you set up this replica link, the system takes care of continuously replicating the
changes coming from product shipping them to D R. So now we can truly say that active D R has been extended to file. And you can also say that for protecting blocks and files. If the customer wants to prepare for the are they just need to do cpr and they can have unified replication.
Yes, that's awesome. Thanks for going through that with us. Um, I think the next thing we want to talk about, you know here today is that we want to talk about the situation where things have gone bad and we were going through the disaster. How do we fell over? How do we re protect and how we fell back?
Yes, john that's a very good question. And disaster is always a very critical and stressful time for our customers. And we wanted to make sure that we can give enough that we can empower our customers to say confidently that they're ready for such an unfortunate event. So to implement a D. R. Scenario and to get ready for that,
we have to talk a little bit about the status is of the part which are promote and demote. So when apart isn't read write access, it's in, I'll give you a mark. Thank you. It's in a promoted shade. And when a part is accepting writes, reads only, it's in a demoted stayed and the flow is happening off. Changes from property are now in case there's a
disaster essentially let's say you lose your flash everyone that's on the bright side now, nothing on this side is available anymore. And all you have is your flashlight to what you will need to do is go to your flashlight too and change the status of this part from demoted to promote it. And that's one single command.
Once you do that this part and for that matter of this part as well will become read, write accessible at that point of time, you connect your hosts here and spin up your applications say connect to this flash array to these interests of volumes and file systems and start your operations back on and we can we can reconnect host here. Right? Yes. You can't reconnect host beforehand as well.
So you can have kind of a warm D are in that sense? Yes, cozy. Warm br cozy. Warm D are awesome. All right. So now we have failed over. The second scenario would be that you have your product coming back online maybe after a day or
maybe after a week. At that point of time, you would have uh gotten all the changes for during that time on your D. R. Side. So you need to bring back your product to that consistency level. What you need to do the art, What do you need to do for that is once the product prod f A one comes back online and I'll give that back to you when that comes back online,
you can change the status of this part from promoted because it wasn't promoted shade into demoted shape. And once you have the setup from promoted and demoted between these the flow of data changes. So at this point of time this will become kind of your primary so as to speak to start shipping changes from here to here. And that way you're getting two things one, you are able to bring back your product to the same
data consistency level that it lost during the time it was down and also you are now re protecting your D our side because during the time if your D. R. Is operational and something goes wrong, you didn't have anything again to feel back on. So now you have a re protection of your D. R side too. So that's where the reproduction comes in,
I think the final and the most ideal status that it has been some time since the D. R happened and the customer operations are coming back to a more natural and ideal state and they're ready to now turn back on their products as a real problem with all the applications, let's assume that by that time with this flow, both the parts are at the same level of data because of replication,
then what you need to do is go to the prod, change this from demoted to promote it and change your D. R. Part from promoted to demoted. And that way, just the two commands and your flip the direction of replication again. And now this is, you're again the proud primary and this has become your gr secondary and the flow of information again starts happening from your product to your D.
R. Yeah, I think this is actually one of the parts I liked is that you don't have to manage this replication connection and that's what we wanted for our customers as well, is that they don't have to worry about, like trying to figure out which direction the thing, all they have to worry about is where they want to have production at uh, you know, and what they want to do at that time.
So I think it's really important that we did that automatically for them. This kind of makes it very easy and gives the confidence to the story administrator that they'll be able to face the stress and the challenge during a disaster recovery. I love this whole thing about the D. R. One of my favorite parts and one of the things I loved about when we chose this for file is the ability to do D are testing.
You know, um I used to be a sys admin in a previous life and D. R. Testing was always one of those things where you're you're always stressed out, you're always having to put everything on the target. D. R. You're always worried about losing our piano, losing redundancy, all this stuff and and and if you're like a Murphy's law,
the worst time to have something happen is when you're sitting over in the D. R. In the middle of test and it's the worst time. And that's usually when the stuff actually happens. So how do we how do we fix that? And that's a good question.
And that question came to us while we're building activity are as well because they're actually financial institutions that have to comply with certain regulations to do this kind of this kind of disaster recovery testing at least once in a year And they can span two a day or a week, very stressful, cumbersome and risky, uh during the testing phase. So what we have done is we have built in a workflow which accommodates that scenario and
what that would look like is, let's say this is your scenario of your ideal state, you have probably our data replicating from your prior to D. R. This partisan promoter state, this partisan demoted state, all you need to do is go to your D. R. And change the state of this part from demoted to promote it Now at this point of time,
because promoted means read, write this part, becomes read, write ready and now you can spin up, europe's on the host on the pr side, start doing your reads and writes, start testing your D. R. Does that stop replication? Exactly, it doesn't. The good thing about this is at this point of
time, while you're rewriting from your D. R. Side apps, your changes from products still being shipped and the part is taken care of just hiding them, putting them behind the scenes, not surfacing them to you because it doesn't know what's the intent right now, it just assumes that you are doing some testing. Once the testing is complete, what you would do is change the status from promoted again
demoted and what that does to the to the part is discard all the changes that came from this side and reconcile everything, All the changes that were shipped from the outside and you go back to normal replication straight coming from prior to d R without losing any changes that were shipped during the day are testing, did you lose any R P O? No. Did you disrupt anything on the production side?
And I know that's my favorite. Yeah, I love having the fact that you don't have to suffer a loss of redundancy or suffer a loss in our P. O. Just to test your diy our site now. I mean that's that's got to give a lot of people back their weekends, you know, and peace of mind, peace of mind as well.
Alright, so this is the ideal star use case of disaster recovery. Why don't you tell me that in file? There are some more use cases? Yeah, there is actually some other ones. One of those that I like to mention is content distribution. So obviously there is a great use case, but in the final world sometimes you have you have you have people in very distant places
that need to access the same files. The issue that comes up there is that they have to cross winds and VPNS and hit latency to access those files and that maybe software that's essential to their job, maybe it's an issue so they need to be able to install and so with this solution of continuous replication, replication that's adaptive across distances, we can actually supply a secondary site with a read only copy of those s O of the software
images and they can access that or any other, you know, um, content, they need access over a distance. And if they're updating it over here, let's say they come over here and they say we need V 1.2 available now. Well now that's going to be over here, You know, 1.2.
And so it's easier for these people to not see those long since he's wasting time waiting for something to download when they can have a local source. Regionally source of that data. Alright, so now I'm going to ask you the million dollar questions that's super important for us and for our viewers, how much does it cost to implement? Active?
Er for our clients? Well, because everything that you every feature that we produce for flash where it's free, it's free. It's completely free. Yeah, that's included with the purity software. As you upgrade your code to a version of code that supports activity are and activity are for
file. You can utilize it with no extra charge, no new hardware, no licensing. It's all there included. They say the best things in life are free and so is actively are. And that's unified. Unified Eiffel Tower, awesome. Mhm,
mm hmm, mm mhm
We Also Recommend...
Personalize for Me