Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
38:14 Webinar
Accelerate Enterprise AI with Your SQL and Oracle Operational Databases
Demystify AI for storage pros: explore RAG, embeddings, and vector indexing in SQL Server 2025 and Oracle 23ai.
This webinar first aired on June 18, 2025
The first 5 minute(s) of our recorded Webinars are open; however, if you are enjoying them, we’ll ask for a little information to finish watching.
Click to View Transcript
Next slide please, Anthony. That's the only reason I'm here. I've been wanted to say that all week. Uh, hey everybody, my name is Ryan Arsenal. I'm a principal field solution architect with Pure, uh, cover databases I specify in SAP, uh, but I am gonna be here to talk to you guys about a little bit of Oracle.
I know we look like a Father's Day Peter Millar commercial, but I promise we're actually here to talk to you guys about AI and enterprise databases, some nerdy stuff. Uh, hey, everybody, I'm Anthonynosentino. I'm a senior principal field solution architect. I have the longest title at Pure Storage. Uh, and it's also almost my 4th anniversary. Uh, but yeah,
let's get into some fun stuff, Ryan. Alright, let's look at the agenda. So first we're gonna talk about the AI shift into enterprise databases, right? We have the two largest software companies really in the world in Microsoft and Oracle where all your business data sits today. Uh, they are bringing AI to their enterprise platforms, right?
Microsoft, I think they said later sometime later this year, Anthony. It's not, yeah, they will not miss the year is is the is the sentiment that they have around when SQL Server is gonna come out this year. OK, Oracle is 23 AI, so you can see they've already missed it by 2 years and they're being a little bit more cagey on when that's gonna come out,
but we're hopeful that's honestly even if is is one on that one too. So yeah, yeah. Have you seen Oracle stock with OCI? Yes, I'm really regretting and invested in the media in January, not Oracle. Uh, we'll look at a little bit of the rag architecture and how relational data databases work with that.
Um, Anthony's got a really, really cool vector indexing demo that he's gonna go through. You guys can actually see what a vector looks like. Uh, as a data nerd, I think it's actually the coolest part of today's presentation. Um, we'll look at some of the performance benchmarks that we've done and how we're seeing data, data reduction on, on some of these vector databases and,
you know, how Pure storage is gonna help you guys with this, right? And, and we'll jump into that. I thought you wanted to say next slide please, next slide, please. I already did that. OK. All right, why, why does storage matter for your, for your AI workloads,
right? It's all about the data. I already said this. You have the business data that's gonna drive your AI workloads sitting in your Oracle and SQL databases today, um. AI and MML are driving massive, massive growth on data sets, right? These vectors tend to get pretty large,
um, fast, efficient access to high dimensional vectors. What's the most expensive part of your AI platform, the people writing the code? Besides them, OK, your GPUs, right? You want to be able to feed those GPUs as quickly as possible, keep them not to capacity, but pretty close because that's, that's where you're paying, that's where your money is going from.
Uh, you want to be able to scale billions of vectors, no performance hits. Like I said, these databases get pretty big once you, once you start vectorizing. Did we determine that's a verb? I think so. OK, cool. We can ask a large language model what the verb
form of vector is and see what it comes back with. It'll probably have a better answer every time. Uh, low latency, high throughput, feed the data to your GPUs, get it in there as quickly as possible. Uh, and you want a vector database because these are purpose-built for search capabilities,
um, understanding, and then eventually inference as well. Oh my So the question is why, like why does Microsoft doing this? Why is SQL Server doing this? And I think they, they obviously they're writings on the wall, like people want to drive the outcomes that AI and ML bring to the party, right? But why would we want to use this in an
enterprise database? It's kind of the next question. And this is actually the slide I used internally to show our business that I think this is where we should spend the next year talking to our customers about for enterprise data, right? So I I showed to our internal product teams and program teams like these are the big reasons why.
Number one, I think it is super important, right? The programming languages that people are gonna use to interact with these systems. You already have that expertise in your org, right? So we're gonna add some new functionality to TSQL and SQL Plus to go and to be able to enable these outcomes without having to retrain, retool, learn new stacks,
and learn new, uh, scalability models, all the things that you have today in your platform. The next one is enterprise grade availability and disaster recovery, right? Who failover clusters, availability groups, right? These are all things that we're using today. In our environment, Data guard, rack, right, the enterprise class things that we're using to
keep our databases online and keep our data, uh, in kind of a protected state and replication topologies between sites. This is all mature stuff, right? We're not gonna have to go out to GitHub and open a forum request or to get help for these kind of platforms. We're gonna go to the actual vendors, right?
Another big one is enterprise grade security, specifically the first one. When I talked to our AIFSA team about the features that are coming in SQL Server 2025, that's the one they picked out most. They're like, that's super important to us because, you know, Ryan and I have access to data inside of a system. He might have a different access level than I
have. I want to go read probably. Uh, if I want to go read financial data, right, he's gonna look at SAP, I'm gonna look at Oracle and SQL Server, and that's how we can control who can access what, not only for real level data into the traditional side of the house, but also when we're driving things with AI outcomes, right?
And so get that functionality. Out of the platform, you know, we have definitely mature things from an encryption standpoint in flight at rest, columnar, all the things that we're using to protect data can be applied here. And the bottom one is huge, right? The operational skills, we know how to maintain these systems,
right? It's not a new platform that have to bring into our environment, learn how to. Troubleshoot, learn how to support. There's also deep deep ecosystems around community tooling and things like that. In fact, all the demos I'm gonna show you today, I'm not even gonna touch SQL Server Management Studio. Everything's in VS code, right?
We're seeing things moving forward and getting good tooling out of that. It's a big fun stuff there. And so let's kind of look at the pattern for a vector database inside of a relational database when We talk about generating a vector interacting with a system for a vector standpoint. We're gonna generate this thing called an embedding, right,
which is a numeric representation of the data that we want to perform kind of natural language search on, OK? And that numeric, uh, data comes from the large language model that was trained and so in my lab I use OLama with a particular model to go and generate the embeddings which you're gonna see inside of the system that we're gonna build today.
We have our application which is gonna be kind of a natural language way that I can interact with the system so I can come along and say, you know what, I want all of the extra large t-shirts that are in red that are available in the northeast part of the United States and not right one lick of TSQL, not where product equals red, where state. In, you know, I, NY, whatever Sar Selectcktar,
yeah, it's best practice. And so I can interact with my platform in that kind of way. You're gonna see later in one of my demos I intentionally misspelled the natural language query and still got the outcome that I wanted, right? I don't have to be as discreet with the data when I'm interacting with the system.
When I come along and I ask that question, that question's gonna get passed into the large language model too and generate another embedding the search embedding. The embedding that sits in the database is gonna be one that represents each row of the data that I want to perform the search on, right? And so that response then when I go along and I ask the database.
I can combine the similarity search that I just described to you, red t-shirts in the Northeast. Also combine that with actual traditional things like where clauses in clauses, however we navigate a relational database. So bringing those two together, I can actually drive some pretty significant outcomes from a data and a query standpoint and
and bring AI to existing applications without having to re-platform, retool and learn new stuff, right? So, go ahead, Ryan, let's go ahead and show them kind of the outcome uh on Oracle 23 AI system. So this is uh a demonstration of uh a fairly simple demonstration of uh a PDF that PUR put out around the alternatives to VMware.
Has anyone heard of Broadcom in the room? Yes, yeah, OK. So PUR is, is really leading the way in helping customers figure out their Broadcom problems, um, that is 3 of the 4 options, yes, I didn't mean to steal your thunder there. Uh, so I just use that, we use that it's demo, it's just a PDF that I put in,
uh, the demonstration, I can kick this off. As you can see, I'm gonna go in, I'm gonna, I'm gonna put the PDF and what this is doing is it's gonna chunk up that PDF file and put it into the database. And the reason you want to chunk it up is to get better search results and to get really better uh uh Efficacy on on your search. Fidelity Fidelity is probably a good term as
well. Uh, if you just put in, you know, if you just vectorize the entire PDF, it's a very broad set of of information in there. So you really wanna chunk it up into things like say 200, 300 words, maybe 6000, 8000 characters, something like that, get much better results when you, when you, when you put your vector searches in.
So I go in, I put in the, the file, we, we, we chunk it up. I ask the, the question, what's 5 alternatives to VMware? And it's gonna go through. It's gonna vectorize that vectorize. I really like that, that, that question as well. the sticker for next year. Databases uh very simply go I hate when it does that.
I'm gonna pause it. Oh, here, I got you. You go, you go do everything. Yeah I'll prove it there. I'm gonna ask it what are 5 alternatives to VMware, right? This is interacting with the Oracle database where the vectors have already been generated, the vector embeddings,
and it's gonna come back, put that feed that into a large language model, and here's my results. Very, very simple demo. Uh, I think, uh, Anthony's gonna go through, I think a little bit more in detail of each one of these steps so you can see what actually the database is doing behind the scenes, but we wanna kinda just set the stage.
Now he's gonna be doing a lot of SQL server demonstrations. This is obviously an Oracle demonstration. Database is a database, right? Microsoft and SQL very, very similar. How these things don't you post that online and see what kind of responses you get?
Well, the terminology may be different between Oracle and SQL, really the way that you do these things and and interact with the database is gonna be the same is my point. Love it. break out of that. Go on to the next one. He called me up about 2 weeks ago and he said, let's not just do slides for 45 minutes.
Let's just do demos for as much of the time as we can. We figured that'd be a little more interesting for you guys to see. I have the slides though. I do slides or slides or demos. Deer's choice. OK, let's get into this. So this is running SQL Server 2025 in my lab. Again, conceptually,
this applies both to SQL Server or on honestly even post grass, uh, with PGector. And so I'm using the stack overflow database here, uh, if you're familiar with that, it's where people used to ask questions before Jat GPT, right? Uh, and what I'm gonna do specifically is I'm
gonna take, uh, the database file that I'm gonna put the embeddings into, uh, as a separate data file on a separate LUN or volume on a flash array, not for any other reason other than I just want to isolate it from a performance standpoint so I can really get a good, uh, observability about what's happening exactly inside of that database when I'm interacting with it, uh.
With a vector data type. So, we're gonna create uh what's called a file group, which allows me to create a file on a specific drive. So you can see I'm parking that specifically on the EDrive. In my uh server there, which is on a dedicated volume in the flash array, and so what you're seeing here is kind of the traditional uh TSQL
to create a table inside of a database. But now I have this new this new data type called vector, right? You see in parentheses 768. That's the dimensionality of the model that I'm gonna interact with. The external model, which I'll show you in a second, uh, is an Oama large language model and the specific model that I'm using is 768 dimensions,
more dimensions, more fidelity. I just chose this for, let's just say. Uh, ease of use, right? Uh, so 768, that's 768 4 byte floats, let's think about that, that's a lot of data to have to actually do what we wanna do because that's what actually AI is. It's being able to take text data or just any
data and apply a mathematical model to it such that it can generate the similarity between the requests that I'm making and the data that I want to get out of the database or out of any AI platform. Uh, what I have here is the code that I use to generate the embeddings. Don't worry so much about kind of the TSQL, uh, gymnastics that I'm doing on screen, but focus on that one part that I had highlighted
there for a second, which is, did you write all these comments? I did write all these comments. OK, actually Geminis. Yeah, uh, so, uh, actually one of the cool things about large language models that I'm using with copilot specifically is I write the code, I write the comments about my code. But then I'll write all the demos. You see there's multiple tabs across the top
and I'll stylize them in one and say for the rest of the files in this project, write the code about comments like this one, and everything looks beautiful and I'll comment it correctly. Uh, so actually it saves me a ton of time and then we can argue about tabs and spaces later. So AI generate embeddings is what's going to take the raw data from my database and then
feed it into the external AI model, generate the embedding, and then stick that back in my database, OK? And that's gonna be how I can search the database using the kind of the pattern that Ryan showed and how we looked at it architecturally. Cool, right. That's just restart, I did just restart,
bummer. All right, so let's go forward. We'll jump past this. I ran this code um in my lab a couple of days ago and recorded this. This took about 8 hours to actually run because it's about 4 million or 3 million rows uh that we're gonna generate vettings for. And the, the reason why I can get into the reasons why it's super fun,
uh, nerdy conversation. It has more to do with the scalability of the API endpoint that I'm generating the embeddings off of. But to look physically at what those are, I'm just gonna get the top 10 rows so you can see like what's actually being stored in the database. And so there's the text, you know Ryan described it as chunky earlier.
That's my chunk. I'm gonna generate embeddings for all the titles so I can ask this database, Hey, I want to find a particular type of article, but I'm not gonna say where equals whatever. I'm just gonna ask a question in natural language of the database. And then for each one of those, the actual semantic meaning of that text is encoded in
this giant super scary uh vector data type that we're gonna look at a little more closely here in a second. And so for each row, I have this thing stored inside the database, 768 4 byte floats. I use that trick with Control F to count very, very quickly. The last one to have comma, but it is 768, trust me. So here, we're gonna do our first natural
language search and as I described earlier, I intentionally misspelled uh the question, but it's still going to give me the right answer because it's close enough, right? And so there I'm going to generate an embedding for the search string that I want to go interact with the database. So the query text, then you see I'm doing the query embedding.
I'm gonna use that same function to generate the um the embedding for the question that I'm asking. And then I'm gonna go use this new function on line 128 here at vector distance for the query embedding. Compare that with the embeddings that are in the table that we generated at scale a few minutes ago, and then give me that similarity score.
So let's look at The answer after I asked that question, to select top 10 query embedding from the stuff that's actually in the table. Run this code. So current Anthony is telling previous Anthony to hurry up right now. So I don't want to scrub. It gets weird when you like start sliding back and forth.
So this is gonna take a hot minute because it's actually doing a table scan because there's no index yet on this database or on this data structure, I should say. Uh, so anyone familiar with their EBA is doing table scans is generally not happy with that outcome. Uh, so we'll talk about indexing towards the end of the session, but you'll see this takes, this takes a pretty good amount of time to get
through at 20 seconds. I think it's about 30 seconds for this demo, because it's scanning all of those things. The key difference between what we're looking at from an AI standpoint, when we look at indexes, is when we do an exhaustive search like this, it's a, it's like what's called a K nearest neighbor search.
I've, I've searched every single thing and I gave you the most accurate answer I can. If I add an index, we're gonna add what's called an approximate nearest neighbor search to the party, which means I have to be able to make sure that that index that is generated is actually representing the data as accurately as possible because we're comparing these things from a similarity standpoint, not an exact deterministic standpoint.
So correctness actually becomes part of the, I guess the, that's what I'm looking for, um. One of the things that we want to do we're designing the system. I'll talk about that when we talk about load testing here in a second. So here's the outcome of our search, right? You can see all the SQL server performances she
posts are starting to pop up. I have my similarity score in reverse order, the smaller the number, the more accurate that answer is to the question that I asked it. Any questions or comments, team? Is this cool? Getting nerdy? Yeah.
OK So let's go and ask our SQL server how much space all those floats took up. OK, so 2.9 million rows just shy of 3 million. That's about 12.3 gigabytes, trust my math, please. Uh, fills in the back how we do it in his head.
We convert that from kilobytes to gigabytes, so 12 gigs. So pretty substantial influence on the size of the database. The overall size of this database is just north of 220 gigabytes. So I just added about 5% to the party. What I, what I'll call out is when you build an index, even on a relational database without
all this fancy stuff on it, you're basically making a copy of the data. You're storing the data in a different order on how it's being accessed, right? And that's really what we're gonna be doing here. We're gonna make a copy of the data, although the copy of the data is just numbers, so it's representing it in a different way,
and we're gonna create an index to access that in a storage efficient way. So, You know, you hear a lot of things and people say, oh, my database is gonna blow up in size, of course it is. We're adding more data to the database, right? Simple as that. But there are some knobs you have to turn in terms of what data reduction looks like inside
of the platform. So and that 12 gig was a single table, a single column, correct, right? Yeah, some of the architectures I've seen where you maybe want to use different models for uh different reasons, you'll actually have a whole separate additional column for that model's embeddings in the database. Cool. Let me go ahead and jump to Where we left off.
Yeah, I'm looking at one last embedding and then we're gonna, at the very end, I'm gonna show you what it looks like inside of the flash array. So there physically, we see it's 12.24. This is why I kind of carved it off into its own separate volumes they can very easily see. The storage allocation with this, so 12.4 um of actual storage being stored,
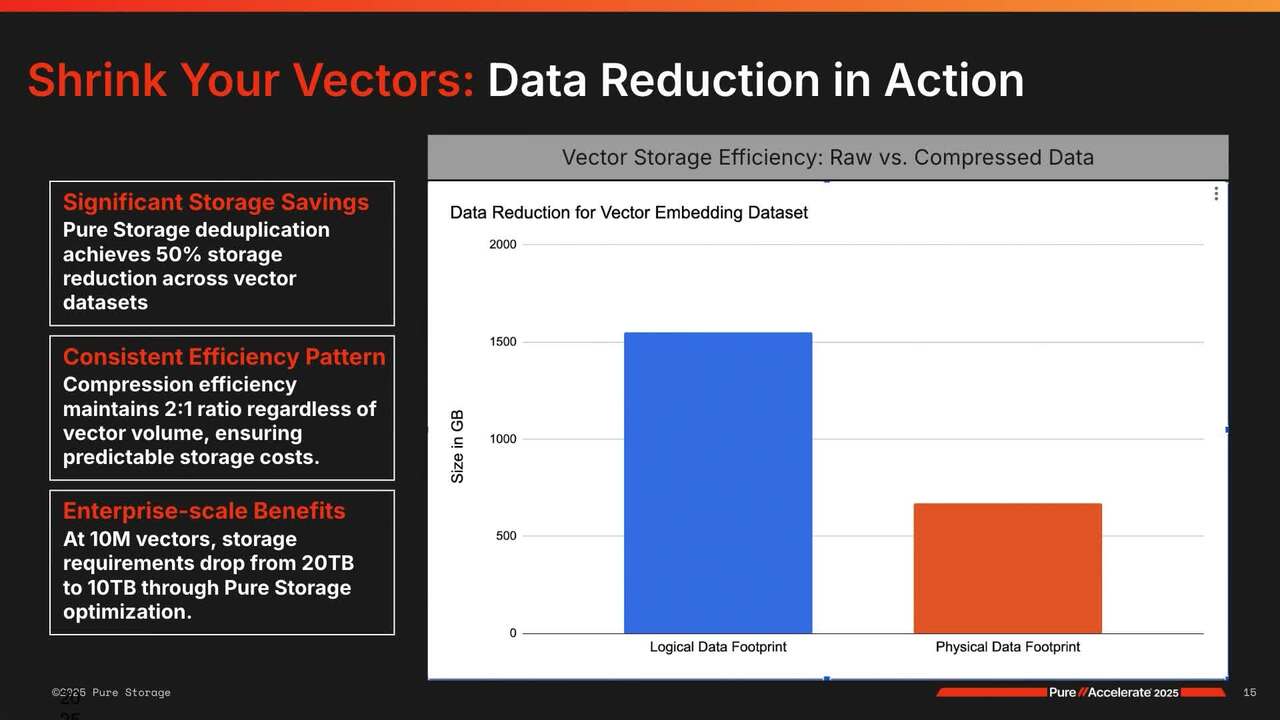
we apply some data reduction to it at 2.9 to 1, uh, and it's actually gonna consume about 4 gigs of data in the array. So I'm pretty impressed actually that Flash was able to get through that historically, pretty gnarly data to data reduce and still get a good outcome from data reduction standpoint. Yeah, so looking at this, we, um, we saw this in our lab too.
This is from Postgrass, a very similar pattern. Um, what I wanna call out is you're not, it's, it's very much so different than a structured database. We're talking about data reduction for vector embeddings because there's so much additional information that goes into how much storage is gonna be consumed. So for example, That 768 is going to be defined
by the model that I choose. There's models that have 1500, a billion parameters, like these are things that we're gonna have to take into account when we start to how much storage is gonna be allocated to this. So if I use the 1500 vector, 1500 dimension model, it's quite literally gonna double the storage allocated with that. And additionally,
chunking, right, when Ryan described the PDF example. I have an 80-page PDF. I don't want one embedding for that. I probably want 12, or 10 per page, right? And that's gonna add that to the party as well. So again, it's a really, we're able to get some pretty good data reduction out of it, but the game has changed from a design standpoint and how we consider and size our
platforms. Cool. Any questions or comments to you? OK. So in, in today's world for Oracle and SQL Server, um, Keeping those embeddings updated is gonna be a challenge, right? In the sense that if I come back and I make an edit to something in the database, well then I have to update the embedding because I might
have changed the meaning of the thing that's in the database, right? And so I wanted to show you kind of how people are gonna handle this at scale inside of platforms and specific to SQL Server 25, and I know Oracle has this as well. We have the ability to enable change tracking. This isn't. Uh, CDC, no one, no one loves uh change data
capture inside a SQL server. This is an additional feature that came out in 2022 and it's been refined in 2025 that allows you to do change tracking on data, right? So basically if I come along and add data or change data, I can kind of push it to the side in a special table and come back later and do something with it.
Uh, and the good thing is on our platform, that's all gonna data reduce out under the hood. So what I'm gonna do here is go and enable change retention for two days and have auto cleanup turned on. Your mileage may vary on which settings you want to use your auto clean up or not or retention intervals and things like that. I'm gonna track changes to the posts table, that's the one that we generated the embeddings
on. And so if I go and I look at the embeddings in that table for posts, you can see I have the uh the body of the text here, and I'm gonna go and make an edit to that. I'm gonna update that text to something new. Maybe there's a spelling error or something that shouldn't be there uh on a public website. And now I have a change, right? That embedding is no longer valid for the data
that I just changed. And so I wanna come along and I want to use SQL Server to manage that change and track that change. And so we have the ability, I'm not gonna go too much to the code, just understand that. What we're doing here is we're capturing the changes, whether they're inserts or updates, and at that point in time,
we're gonna feed it into the model, generate a new embedding and stick it back in the database. So help us kind of make little rocks out of big rocks and managing the change over time inside the database. We certainly could do this in mass, but I want to kind of do it in a trickle because, well, that's a pretty, it's pretty resource intensive operation to go do this work,
right? There's the update. I'm just going and bumping up the new text against the model, and then I track that in a table, uh. So I can come back and just kind of have a log of what's occurred, and there's my tracking table right there. Cool.
And so we have that stored procedure on so 160. I can run this every hour, every 5 minutes, every day, and it's gonna go scoop all the records out of the change table and generate the new embeddings. So I come back and I ask for the embeddings. You can see it was updated a couple of days ago, uh, after about what's that 5 or 6, I can't I what's 13 minus 576?
Seriously? Uh, several days later, I come back and you can see it was updated inside the database. Very fun. See, jumping ahead. All right, cool. So final demo demo, I think it's final demo. Yeah. All right.
So one of the things that's pretty cool about both SQL Server and Oracle, uh, SQL Server had is 2022. uh Oracle is in 23, 19C is the ability to add this thing called an external table. SAP had it in 2019, really. Did was did he, uh, all right, so what, what I can do with this architecture is this,
uh, I can take the stuff that's old, right, and put it somewhere else, maybe on a cost optimized platform, right? Maybe that's a flash blade or something like that in the system and also it's gonna make what I have on the hot block side of the house smaller, right? If I take a bunch of old data and I push it out the object, the things that I have left.
Inside of my flash array on hot block are gonna be smaller, right? So the database backup smaller, the indexes can be smaller. The amount of things that I have to care and feed for are gonna be much less than if I had the entire thing inside of one singular database. So we're gonna go ahead and walk through some
pretty gory detail on. How to manage that externally. So let's get into this. This is kind of one of the, the funder demos I think when we went through this, uh, in the prep for this, this is the one I think Ryan was most excited about. So what we're gonna do is go uh tell our SQL server again,
this could be Oracle as well to go talk to a flash blade just over S3 object, right? And you can do this for any row data. It's not specific to embeddings, but I wanted to call this out in this example because we are adding a lot of data to the system in terms of volume, right? And so the external file format that we're gonna write into is Parque.
And in SQL Server 25, specifically, uh, the ability to interact with S3 uh over Parquet, CSV and Delta is built into the engine now. I don't have to install any additional software or tools or anything. I just have to turn it on, which is what I'm doing here in 57. A line 57. And there's a lot of polyba export and so we'll
create this thing called an external table. And what that's gonna do is give me the ability to interact with objects so I can put data in there or I can pull data out of there again with no external tools. This blows my mind. I think about what we had years ago about the ETLs and moving data between platforms, right? And so I just went real quickly and just stuck
10 rows in there just as a, as, as a, as a test, right? A smoke test, hey, I could talk to a bucket. I got some data in there. And when I go into, um, I use a tool called S3 Browser and I go and I look inside my bucket, there's my data inside of a parquet file. Cool. So now, let's do some fun stuff.
I'm gonna go scan across the whole database and I'm gonna aggregate posts by year. Right, how many of us have databases with transactions like 1997 in them? Right? All of us, I guarantee you, all of us, right? And so you can see here as I aggregate it by posts and you know, do I, is it really relevant to my business to have some posts from 2008
about VB6 in kind of the hot block side of the house on my, in my database? Probably not, but, but you can't archive it, because you can't, you can or cannot, you cannot move it out of that database, correct, right. But I still want that data. It still means something to the overall thing that I'm working with.
This could be this could be orders, transactions, you know, medical records, whatever it is. And so I want to take that stuff, leave it in the database, but I also want to generate embeddings for it too, and it's probably not gonna change very often either. So let's go ahead and I'm gonna take everything
from 2008 up to 2022 and I'm gonna stick it into flashblate over objects. So let's go ahead and do that. And so this loop right here will go through. Uh, my post table and just start parking that data 2008, 2009, 2010 inside of Object, and this actually goes remarkably fast. I think um I did fast forward the video for this one,
but for this database, I think it's gonna move about 12, you know, 9 gigabytes of embeddings. So just a couple of seconds to get that to run. Alright, let's go ahead and. I think I scrubbed through this one. It takes a minute. Oh, they're gonna see it,
yeah, generate inside the flash blade. So as I refresh, it's gonna go, it's gonna make a folder for me inside of there, you're gonna see year by year, right, so I can come along and actually just query one of these or a subset of these if I wanted to. There's all the parquet files, that's the actual data that's being inserted uh into our
target system, or the flash plate specifically. So that should finish up here in a second. Jump ahead. There we go. You can see what it marched through year by year by year to get that data into our system. It took about 1 minute and 40 seconds in real time.
Now, what I'm gonna do is I'm gonna create another table on the block side of the house, and I'm gonna take all the new stuff from 2022 and stick that into that uh that table there, that takes a few seconds. And insert everything from 2020 forward. So you see what I'm doing kind of separating data out. I'm gonna keep the stuff on hot block that's
still relevant to the business, but I also have the stuff in the archives here uh that I can have access to you later. And then I'm gonna drop the old table, right? Generally a pretty scary thing to do. Uh, but you're gonna see with no code changes, our application is gonna be fine.
I'll show you that in a second. So that's gonna insert all that data on the block side of the house, drop the table, which in SQL Server world and in Oracle world just marks it for reuse. We're gonna look at uh how to reclaim that space in a second. I can now create a view and notice the view is the same name as the table,
which means that applications don't have to change code. Right, but I get all the benefit of being able to push things where I wanna push them and control where where that data actually lives, OK? Cool. And so I took each one of the external tables, which is each one of the uh folders inside of the flash blade,
unified that with the block side of the house, and so now I can come back and I can do the aggregation again, the same exact query. And get all of that data and do that aggregation. So I have access to all that data with no code changes. I did add what's called a query hint to this because I want to call out that,
yeah, I say there's all the data from 2008. When I read from Parque now, I do that concurrently, right? So I'm gonna each one of those files, it's gonna kick up a separate reader thread, a separate TCP stream, and then a flash blate. So we're gonna drive all that IO out of the flash blate at scale.
Right? So now I can start to do these like really strong analytic scenarios, that's each one of the remote scans all running concurrently. I can start to drive some really cool analytic scenarios and kind of get kind of a scale out uh data warehouse scenario going with this type of configuration. So I still have a bunch of data on the block side of the house,
that's about 27 gigs, but I want to reclaim the space that I got rid of, right? Because I, I dropped the posts table and I stuck a lot less data in this new table. So to reclaim that and actually get that out. Of the flash array and shrink that back down. I do have to shrink the table, which for a DBA generally is a scary operation, but they're OK with doing this in these kind of
scenarios to reclaim the space back and we'll do some things to make sure that it's still performing on the side of the house. But you can see I went from 12 before 27 now. Our data reduction went down a little bit just because I'm storing less stuff, so it kind of drives that back down. We're gonna see that kind of climb back up here in a second for a different reason.
We don't have time. No, OK, pretty good. Yeah, so this is the flash blade out of the house. So we took all those embeddings. Parquet is already a compressed file format, uh, but we did eke out a little bit more, 1.1, it's kind of cute, uh, on the data that's inside of the flash blade.
Did you roll your eyes? No, yes, you did. OK. All right, it was kind of cute. It's totally a dorps. All right, so remember I talked about table scans and making us sad as storage professionals. So we do have the ability to add uh with uh a
vector index. This is new, um. Actually, this is, yeah, this is new again, the SQL Server 2025. I'll add the vector index, which will give me more high performance search into the database. And so I'll go ahead and do the same query that we did before. To find me all the posts about SQL server performance issues,
not that there are any of those ever, and go and find that data inside the database again, the same quarry that I did before, but now I have a vector index. I'm no longer do that, uh do a table scan on the block side of the house. I'm gonna seek to the rows, a subset of rows and return that back. To the application, but I'm also gonna bring in all that data as well cause I'm going across
all of my posts with this query. So you can see I'm still getting a very good performance out of the whole system. I've scanned every row in my database in under 15 seconds, right? Pretty strong performance story there. Oh, break out of this.
Kick it back to you, Mr. Arsenal. Is that cool? Cool stuff. Kind of demystifies the whole thing, right? AI is not complicated. It's just numbers. Yeah, it's just numbers. Um, so, so how does pure storage help, right? Obviously we have some best practices for being
resilient. I think you probably know about our non-disruptive upgrades, right? The ability to keep your storage up and running, uh, for these processes. Um, Active cluster is just a, a great tool to be able to, to be able to run this stuff, right?
Protecting both sides of the of this of the database of the scenario, um, having those synchronous rights go go between just protects everything, uh, when you need to. And then snapshots, we'll talk a little bit more about more snapshots in in a minute, but. Snapshots, backups.
I did a whole session that last year. Uh, snapshots are just, we don't, we don't talk about them enough in my opinion, at Pure Storage, and I talk about them every day. I still don't talk to them about them enough because it really is our secret sauce. And if you've ever explained a snapshot to to a DBA who has no idea what a snapshot is before,
and you see his eyes just kind of roll into the back of his head because it's life changing for him to be able to do a snapshot. This is the guy that's waiting 2 hours for a backup to restore just to get access to his data. Now we can do that in milliseconds. Nextslide. Oh you. Oh, it's back to me.
You wanna do this? No. All right. Uh, so when you did, you did the work, I did, yeah, um, I'm just here to look pretty, remember? Yes. So let's get into what benchmarking looks like because there is an additional dimension, that's a really good pun right there, on how we want to define good for benchmarking for vector
databases again, both on the SQL server side, Oracle, and also postgrass too. So the bottom is the stuff that we're used to doing as storage professionals, right? How much data do I need? What's the data reduction ratio? What's the latency associated with the transactions that are occurring and what's the actual throughput uh from the system because
you saw the data is gonna grow, we're gonna move more stuff, right? And so that becomes part of what's important to an AI, AI vector database load test. But the things at the top are kind of the new things to the party in terms of what defines good for a benchmark for a low test. So queries per second,
obviously how much work can I get done in a fixed time interval. Recall rate, that's that concept around accuracy that I described earlier when using things like approximate nearest neighbor search. And so you'll see when people post or when they do um load tests with uh things like vector DV bench, they're gonna um Also have the recall rate with it because again, I want a good answer out of an approximate search and
also index creation time becomes important as well because in some database engines, the actual vector database index uh is read only. So you mean you have to burn it down when you do row changes and. rebuild it back, which can be challenging. So architecturally, we're seeing some folks that are starting to build Rewrite indexes.
If you're familiar with column Store inside a SQL server, uh, when that came to market initially, it was read only and then it got better readrite, and then you've seen optimizations there. So I expect to see a very similar pattern out of Microsoft for that. Uh, one of the things that we did see, uh, on Monday, CTP 2.1 shipped.
Uh, Microsoft, uh, did a bunch of performance work around the index creation. It's 2.5 times faster than CTP 2.0. So they're actively investing and making it faster and it was pretty fun. I was, I woke up a little too early on Monday and ran a bunch of load tests in my hotel room because that's what you do when you're in Vegas, right? That's cute, yeah.
So when you're jumping into AI, if you, if you're, if you're a business that says, hey, I got an idea for some AI, you're not probably not gonna go out and immediately invest hundreds of thousands of dollars in GPUs, right? What's a good place to be able to do this, this work when you have that idea in the cloud, right? You can rent some GPUs, very easy.
How hard was it for you to get some GPUs to be able to do the work you did? You had to beg, borrow and. I borrow and steal. Yeah. So the clouds are really, really good place to do this, and that's where I think our data mobility story can really, really start to help here, right? All your data sitting on a flash array in your
data center. You want to be able to put, you want to be able to vectorize, get your vector embeddings onto that database, but you don't have the GPUs to do it. Snapshot, very easy. Fire up a cloud block.
For instance in Azure, for example, move your data up there, move your snapshot up, attach it to rent some rent some GPUs from Azure, uh, run your embeddings, and then you can send it right back. Uh, you obviously can't overwrite that database, but then you can run some tools, maybe ETL type tools to get those embeddings back into your original database.
So very easy way in our data mobility story makes that extremely easy to do. And bring it home. So what have we learned? I don't know what have we learned? Ask you guys. Vectors are kind of cool, right? They're pretty neat. I, I, I, I'm a data nerd and I used to, when I was in IT,
I used to be the guy that wrote the queries, right? Oh, you want to find out how many t-shirts were sold that were red in, in the Northeast? I would be that guy that would run that query. This would have changed my life to be able to do something like this to then just sell it. How many t-shirts did we sell? Like it totally would have changed my life.
Um, the AI shift is happening in enterprise databases, right? The two largest software companies in the world are bringing AI to their databases because that's where the data is, right? And they're gonna continue to invest. We've seen them continuing to invest. Um, Anthony has a lot of contacts within Microsoft, and they've promised that they will
continue to invest in this area. Rag architecture's relational databases aren't that complicated, right? You generate some embeddings, you, you ask, you do a search, and you, you saw in the demo. It was, it was pretty easy to do, not a lot of code either, and you wrote that code directly in SQL
Server, which is still extremely cool in my mind that you can't do an SAP. You have like Java, yeah, old school. It's like a bolt down tool. OK, sorry. Uh, vector indexing SQL Server 25 2025 and Oracle Oracle has a similar, uh, indexing approach. You saw how quickly he was able to then do
those full table scans once he did get a vector index put in place. Um, performance testing, right? We've showed you just how easy it is to to get this stuff together and the data reduction. I think we were both pretty pleasantly surprised with that 2.9. Love 3, and round up 2.9 to 1 on those vectors. That's, that's pretty good because you saw what
the data looked like, right? It was just a bunch of numbers. But an asterisk on that one. It depends on dimensionality, how you chunk, like, so that's, there's a lot of knobs to turn on that, but it's just I was I was just pleasantly surprised to see like historically diabolical data structure or pattern get data reduction on our platform.
To cool, yeah. All right, I guess any questions or comments team? Open it up. We got 6 minutes.


We Also Recommend...
Personalize for Me