Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
36:54 Webinar
Active-Active Protection with Stretched vVols Using ActiveCluster
This session will cover the benefits of using Everpure ActiveCluster™ technology with vSphere Virtual Volumes (vVols) and show how stretched clusters can help balance virtual machines and application workloads between geographically separated data centers.
This webinar first aired on June 14, 2023
Click to View Transcript
All right. So we're gonna go ahead and get started because there's some good content to cover. So the first thing we're going to talk about active active stretch clusters for vials. And I know this has been a long time coming, but I can tell you that we have been working on this very hard, is one of our design partners and we are very close
probably within maybe the next 3 to 6 months. Just you have to, I can't give an official date obviously. And until you see it, that's where uh well, the next slide, I'll let that go. So my name is Jason Masa. I'm the technical marketing architect for storage name.
So OK, there we go. Sorry. My name is Nelson Elam. I'm a solutions engineer at pure storage. So Nelson and I work together on a lot of these products and so active. Active. Oh, we don't have, it's not up there. So there's supposed to be the disclosure which you guys may or may not have seen.
This is a future looking concept, but I can tell you that we are actively working on it. There's a lot of engineering that's been going on with Vals. And I can tell you that Vivas is the primary focus for external storage with VMWARE. So that doesn't mean that vmfs, nfs even they'll say the bad word RD MS are not going away. It's just that the primary engineering focus is
on vals and that includes within all of the ecosystems. So cloud foundation containers, tan Zoo, that type of stuff is really focused on vals. And so that's why this is so important. So let me jump into kind of the idea on, I'm gonna give you kind of a quick overview on vals
more what V Balls is. And then I'll let Nelson do a demo showing that we actually have this working. So if you think about the way the storage started out, we can talk about, but I'm gonna jump past that, we'll go into sand. And the idea was we would provision Luns directly to bare metal.
Now that gave us some certain features available to even at the application level, stuff like snapshots, stupid compression, all of those functions were available to the application. And so that gave customers a lot of features that they became accustomed to, especially in some of the DB A stuff that was, there was a lot of features that you were used
to using for database administration that you can't quite do with some of the modern functionality that we have with vmfs. So that jumps us into where VM Ware came up with VMFS. So the VM ware file system, now we looked at San and how that worked, which was more of a 1 to 1 mapping with the A or a volume.
If it was, in that case, we talk about vmfs, we're talking about a single one being accessed by tens or even hundreds of hosts. And then each host could have 50 maybe even 100 B MS, maybe even more depending on the newer hardware accessing that single object. Now, there's some pretty amazing technology that has allowed us to do that and it has some
incredible functionality. But when we do that type of sharing, we lose some of those array based features because we have to share a single object out to thousands or even tens of thousands of applications or virtual machines. So when you think about that way that works, we gained this shareable functionality,
but we lost some of the array functions. So that's really where vials comes into play be balls. The easiest way to describe what an actual val is if you're not familiar with, this is a well orchestrated RDM. And the way that works is there's a Vival object and these are sub lungs basically is
what they are or sub files that sub object maps directly to a VM or in some cases, you can do shared for stuff like, you know, clustering file systems and stuff like that. But the idea is with RD MS you have to manually do a whole bunch of work. You have to keep track of all these things. You have to do a bunch of zoning with V vas
none of those overhead operational tasks exist. All of that mapping of that individual object to the VM happens all automatically. There's also no more provisioning of Luns or volumes. So that's a huge step for the storage administrator. So this frees up a lot of time for their operational tasks.
They're not having to create loans or change Luns or resize lines. All of that goes away. They can provision vols based on what we call a storage container, which is a logical quota that says the viva infrastructure can use this much space so that can be limited if you want another big
feature is there's no file system. And what I mean by that is again with that shared functionality we had either NFS or V MFS, but now the guest Os is actually residing on the array itself, there's nothing below it. And so there's some efficiencies that happen with that.
And one of those is space reclamation. So if a guest OS supports trim or un map, when that guest Os initiates that space reclamation task, instead of that being processed by the file system, then the file system doing some work and passing that to the array, the guest OS is actually passing that directly to the array.
So now you have a little more efficiency in the way your space is utilized. And one of these happens to be with some of the reporting, the reporting that you see in vsphere tends to be a little more accurate than what you tend to see with say VMFS and even sometimes NFS and especially what you see on the array side, you'll go in and if you saw that little talk this morning,
sometimes you'll see where a guest Os is saying it's using say 50 gigs. If that G OS that guest OS exists with multiple of the same guest. Os, you might go on the array and it might say it's using five gigs and that's real because the array is capable of de duping that array guest OS. So you might see one that is, you know, 45 gigs and then the rest of them might be five gigs.
So there's a lot of efficiency when it comes to the way vivas work. Another big key is replication. So when you do granular VM replication, you've got to use either BS for replication which is going to be vendor agnostic. And so it has to say I can do a replication for this VM regardless of what their storage is
now, that works fine. But it doesn't, it's not the most efficient way of doing it with V balls. And this is the case with all of the storage functions, de doop and compression replication. Snapshots are all array based So any time there's a storage action vs bear just hands it to the array and says you do this vsphere does
not do any of this. So storage DRS bio, all of those functions aren't supported with vals because those are Vsphere way of managing storage issues. This is now handed all off to the array. So now you can do a ray based replication, but you can do it at a VM level.
Now there's a lot of capabilities with that because now that you're doing it at VM level, you could have one VM that replicates every day, you can have another VM in the same data store that replicates every hour. You can also do one to many which is not supported with any other type of array array based replication.
Because typical array based replication, whether it's volume or block is done of 1 to 1. So one line gets replicated to one array with balls, you set up what's called a partnership. It's not a fixed 1 to 1 ratio. So your source can have multiple partners for replication. All of that replication is managed with policies and they all sit in the same source
data store. So you could have again, like I said one VM or one application that replicates every hour to one site and from that same data store, replicate another one every day to a different array. So you have a lot of autonomy when it comes to Val's management and it's all managed via the policy based management.
So you can see where you get a lot of these features that you get with V balls that give you the array based functionality. But of a lot of the Vsphere management capabilities because all these capabilities get to be managed within Vsphere and V Center. So let's talk about some of the things that are driving some of these features. The first one is a lot of the on premises or private cloud functionality.
Customers are wanting hyper scalar like functionality, they want to be able to scale. And when you're talking about really large scale managing Luns and volumes is not really that capable of doing that in a very efficient way. When you're talking tens of thousands of Luns, that's a nightmare to manage across multiple hosts across multiple arrays.
That really is something that can be very daunting with vials that becomes very simple. Another feature that I didn't mention is that with that V vas data store because it's not a physical object, right? When you look at a deep Vivas data store, it's not the same as a vmfs data store in how it's provisioned. It's not a lun to that data store, it's an allocation, it's a quota that Viva data store
can span multiple vsphere clusters and you're not sharing objects. So you also don't have that noisy neighbor situation with VM sitting within the same data store because each BM has its own set of disks. Another big feature that's driving this is the kubernetes functionality or containers. So we have this function called F CD. First class discs.
First class discs are objects or discs that sit within the vsphere environment that are not associated with a VM. So FC DS are what we use to you to connect or are the same thing as a persistent volume. But now that persistent volume can have its own storage policy and it can have its own snapshots and it can have its own replication.
Again, you're managing this all with policy based management. Another big feature is the cloud functionality. So being able to disaggregate compute, being able to have all these features that are very similar to say an HT I environment. But now you're managing external storage, you get all of that with vivos.
So you can see where a lot of this industry is driving these features and vivos have these features automatically. So another big piece on the value and this first one I did put in is in the works and it's very close. This one you might see much sooner than the stretch storage. But one of the things that people are still
holding on to RD MS for is being able to resize with a shared disc. So AWS FC Microsoft cluster that's sharing a DIS currently RDM is the only one that supports hot extension or hot expansion that is actively being worked and we actually have it working. It works great. So you may see that very soon. OK.
The other one is that will really help to eliminate the need for RD MS because really that was the only thing left that the RD MS had over vals, all the snapshots, all of the replication, all that functionality is already built into V vat. Another big piece is I mentioned this before is that all of the storage functions are array based. So snapshots replication, all of that
functionality and then of course modern and applications I talked about Tanz and the persistent volumes, those are now their own entity. And another big benefit is that on all of this storage functionality, the storage administrator can see all of these objects, they can see what the compression ratio is, they can see what the size is, they can see what the performance is.
So when it comes to debugging vals, it's very, very, very fast. When you think about a traditional runner of volume, there could be 1000 VM sitting in a single line or a volume and trying to figure out which one is causing the problem or which disk is causing the problem can be very daunting with V VAS storage administrator sees every single object and goes oh it's disk number two on this VM.
And here's the VM name, you need to take a look at it and see what's going on. That is all available right now with vivos. So now the use cases and benefits, right? I talked about all these features. The one thing that I want to make sure that everybody understands is that 99.9% of all customers can go and install vivos right now.
It is not necessarily a replacement. In fact, the best practice is that you're probably going to use vmfs and V VAS in, in complement because there are some things that you should put on vmfs to avoid what we call a circular dependency like V center. So in a catastrophic failure, if you needed to bring your environment up,
you do need V center and a Vasa to read the V balls. The metadata is still with the V VAS. You haven't lost any data. But if you don't have your V center, you would have to build a new V center, read the Vasa to see the. So we recommend that you put those in vmfs so that you can bring your environment up much
faster. But what I recommend is that if you have an array, especially if you have a pure array, you can go add. And I'm gonna say that specifically add V balls to your environment today. And I recommend that you do that, just try it, you can take an application and you just do a storage V motion from your vmfs to your V balls. And then your storage administrator will be
able to see what it looks like. They'll be able to see the performance, the compression ratios. What's that? Yes. Are there in Boston? Yeah. For what? 6.0. So pretty much everybody I hope is on 6.0 or above.
I hope no one's on 60 yeah, it's just 6.0 V Spheres standard and above. So it won't work on essentials but it'll work on standard. So I recommend just get it up there. You don't have to change whatever connectivity you're using, whether it's Iefcfcue, even NFS, all of those are supported with Vals.
So I highly recommend that you just try it and see what it looks like. Put test and DEV in there if you want. It's literally just a storage remotion into vals and a storage remotion out. There's no creating objects. Um The pe s automatically get created if you, especially if you use the plug in which I
recommend because that makes it much more consistent. Um It's just I really highly recommend that you guys just try it because VM Ware in general is going, like I said as a priority towards VV. But again, VMFS, NFS is not going away. It's just that the focus is on. Now. I'm gonna hand it over to Nelson so we can get
into what you guys are here for. Thanks Jason. So, uh stretch clustering is not a specific concept of pure, like all arrays and uh VM Ware specifically you can use stretch clustering. So uh what I'm gonna talk in general terms, at first, I'm gonna need a little more specific about active cluster,
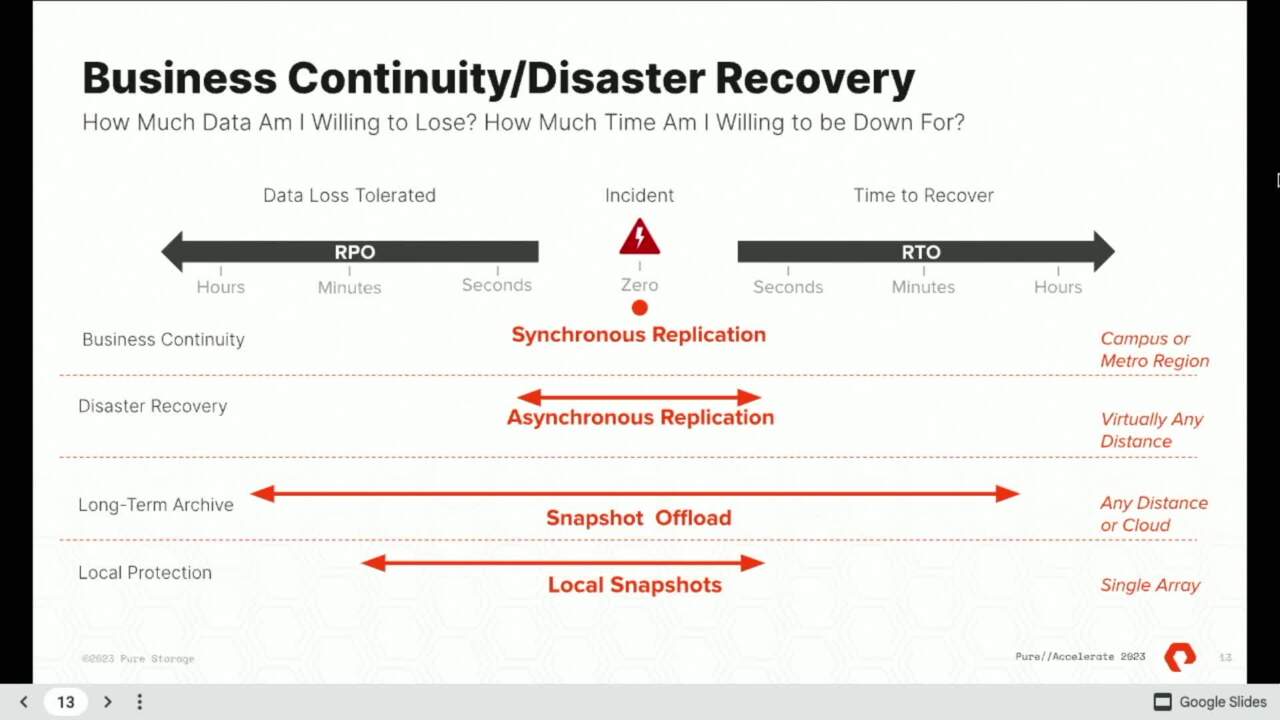
which is pure uh stretched clustering solution, synchronous replication solution. So uh really like this chart. Uh it gives you a nice breakdown of all the different options you have available to you from a replication perspective. And uh synchronous replication is what the the focus is here. So where you have multiple sites, you have hosts at one site host at another site arrays
at both sites too. And synchronous replication is a fantastic tool for the most critical of your, your V MS, your, your workload and your environment. Um I if the stuff you want to be up as much as possible uh should be on stretched stretch clusters in general, right? Um And a a sync rep application offloading snapshots, local snapshots.
Those are all, those are all options. But again, um for the really critical stuff, synchronous replication is a good idea with flash array. Um and synchronous replication, there's no additional licensing costs. So you buy the arrays and uh active clusters included as part of it. There's there is a little bit of configuration
and set up that you have to do. Um you need to involve support to validate that everything. Uh 11 millisecond round trip latency is a, is a critical uh consideration there. If it's greater than that active cluster is not gonna be able to be enabled. But other than that, it's, it's free. You can, you can set it up and do it whenever
you want. Um There's uh 22 general concepts, I'm gonna talk about from a connectivity perspective between the host and the array. The first is uniform connectivity and I'm gonna flip back and forth a little bit because I think it's easier to visualize. But so non uniform, you can see the paths in between the hosts and the arrays.
There's, there's no cross link between them, right? You have the replication link between the arrays themselves, but you don't have the host at site. A do not have connectivity to the array at site B and vice versa. So uniform is, is a really good idea. Uh for obvious reasons,
the demo I'm gonna do later is a uniformly connected environment. So all, all those hosts are in a cluster together. Um And they'll be able to talk to site B. The first thing I'm gonna show you is site a, the array goes down and then site a, the hosts go down. So you can kind of see what happens from a VMR
metro storage cluster perspective with and from a flash rate perspective with active cluster and balls. And if, if, if, if you have, if you're using active cluster at all with uh VMFS today, a lot of the, a lot of what you're gonna see here is very similar and that's, that's kind of the point. It should be very similar,
except fundamentally we're using B ball or we will be enabling you to use V VAS. And yeah, right now it's just bmfs. So yeah, from a flash array perspective, we've got uh we, the way we manage this is with a pod. So you, you stretch, you have a stretch pod whenever you move a volume into it,
that becomes a stretched volume. And that data is sync synchronized between the two sites, the two arrays at the two different sites. And uh it allows you to connect the again with uniformly connected environment uh site. A's hosts are gonna be able to talk to site B's
array without, without any issue. Um And if the array goes down, you'll just see half the paths go away. The VM will very likely not notice any impact, losing an entire array uh with a uniformly connected environment, even with non uniform. If it's set up correctly, it can happen too. But yeah, so that pod object is how we manage
that also with vals and pure. Um In 6.4 I don't remember a early version of 6.4. We introduced multiple storage containers and part of what Jason was talking about was quotas. So managing that capacity, that stuff's all uh customer definable in purity 6.4. So that's the pot object is, is a critical part of this for active cluster and with multiple
storage containers and vals also a critical part of that. But they, you know, they work well together here. You'll see that in the demo in a little bit so typical challenges you might have with backup or disaster recovery solutions. Um predictability can be hard to ensure that what you have planned actually
functions and behaves as you expect with, with active cluster and with VM Ware metro storage cluster. Um It's, it's a really solid, simple solution. Uh I the lab I spent setting up, took me half hour an hour to get to get all configured. Um I I ended up using defaults for metro storage cluster for the most part. So not a lot of extra configuration there,
but that predictability comes into play there. It's very nice to know this, this is working, this will work as I expect it to because I've set this environment up correctly and you don't have, there's not a ton to consider there from an integration perspective. Uh Pure and VM Ware deep deep rich partnership. We, we talk all the time about all sorts of engineering problems,
customer problems that like our mutual customers are having. So that that integration is a, is a critical part of all of this and uh rest assured with pure and VM Ware in good hands. It's, it's gonna work really well because we test and validate. We have to certify everything with VM Ware. Whenever we, we do a new purity release, we have to get all of that certified from a
stretch storage perspective, but also not stretch storage a whole, a whole thing. And we find, we find bugs during those processes and we get them cleaned up and it's great. Um And as I mentioned before, from a cost perspective with flash array, you, you obviously you need two flash rays, but there's no extra licensing beyond that.
You, you have, you have the hardware, you can connect them up. And yeah. So yeah, in, in the, in the circumstance where that you're gonna see this type of diagram a lot. So site one and say two um the the through VM Ware metro storage cluster, that's how that the hosts are clustered together and then with
active cluster, that's how the arrays are clustered together, right? Um Support VM Ware Metro storage cluster, those the guides I followed because that's what I did when I set this environment up for the demo, I follow, I actually went through RKB SI like to do that just to make sure we're not missing anything or it's clear enough. Um But those guides exist now for,
for uh VMFS with active cluster and once active cluster and is is available that they'll, they'll largely be, they'll be, they'll be pretty similar. Um But that, that content exists now. And yeah, as I mentioned before, this is like, you know,
the most critical of your workloads is what, what this solution is geared towards um that low, low RPO zero RPO zero RT O is really what you're looking for there. OK. So I'm going to switch back and forth here a little bit and, and this is what the demo will highlight in the case of a site failure. Um VVVHAVM Ware Metro storage cluster will actually like you can configure it,
you, you don't have to configure it this way, but it's a good idea to configure it. So the V MS will reboot in the case, their, their host is no longer available, they'll reboot on a different host in that cluster. One, that one that's available um from a storage perspective when you lose, if you lose an array, half the pads go away, but otherwise you likely won't notice anything.
Um The VM probably won't notice anything either. So your users are, aren't gonna see anything either. Um And it's, it's more, more of what you've come to expect from pure, from a like a simplicity perspective. You get it set up, it, it works how you, you expect it would and it's very easy to look at and try to figure out
what's, what's going on if there was a problem, right? Um But yeah, as mentioned before, it's free with, you know, with the, with the raise you've purchased and that you get the right VM ware licensing in place. Um But yeah, something, the, the certification I, I like to mention, I wanna mention this again, because it is,
it's a really detailed certification process to do all of this stuff. And stretch, stretch storage in general is something both pure and VM ware take very seriously. So the certification process is very complex and the testing that we both do uh together and independently is very thorough because this is where you want to put the most critical of your workload.
So if the array and VM and the ESX I hosts are not able to handle that. Well, that's, that's not a great situation. So it's something we take very seriously. OK. So as I mentioned before, it's a uniformly connected environment uh in the demo. Um And I'm gonna simulate a failure of site a here, take the array down first so you can see
what an array failure looks like and then take down the two hosts that are at this site as well. And let's see this out. I have my laptop at the back. Am I gonna mess everything up for you if I connect my laptop? No. OK.
We'll find out. Ok. Well, Nelson was getting his laptop. So I apologize. How many folks here? Actually the support for that three?
Yeah. And now I'm curious what that you you for? Sorry, you have not. Ok. Yeah, thank you. Thanks. Customers are using uh vivas. OK? Um Jason Jason mentioned earlier like val is
not, not a difficult thing to set up and the the Vsphere plug-in from pure, makes it fantastically simpler if you're not using the Vsphere plug in in general right now, pure Vhe plug in, it's definitely a good thing to install and play around with. There's a lot of val's functionality built into it recently allowing you to resize Vival data stores and edit, edit them. Otherwise like a lot of really cool stuff that
would take a lot of extra steps. Ok? Thanks for bearing with me while I got the demo going. Um And I'm gonna pause this because it, I, I do go a little fast through it and that the clear. OK. So yeah, this, we have VH A turned on here. Uh VM Ware Metro storage cluster is being used
here. I have four V MS that are running VD bench, just a workload generator, um One on each of those four hosts. And as I mentioned before, we're gonna kill two of those two of those hosts. So you can see what happens to those B MS from a like a restart perspective. And just for warning, I did edit out some of this because it,
you know, some of the processes take a couple of minutes and I didn't want you to have to sit through that. Uh But I, I didn't do like as far as the recovery process goes, I was not doing anything manually, so I'm editing it out just to save time not to hide something. Um So yeah, the, the, the host had VM ware metro storage cluster enabled the
array, we've got protocol in points uh configured that are connected to those ESX I hosts. Um As Jason was mentioning that protocol in point is a critical device for vals that's part of the data path we have, you can see here we have 16 16 paths available to this protocol in point right now when the environment is up and healthy, that's eight per array,
four per controller. Um and will highlight in a little bit when the array goes down, what that looks like just goes from 16 to 8. Also worth mentioning here um status. So with, with uniformly connected environments, you those paths you might have
like it might be 10 milliseconds of latency difference between the two sites. So part of part of this configuration is helping uh helping VMR know which paths it should try to use primarily. And then, so those are active optimized paths and then you tell it which ones are active, non optimized, right? So the higher latency ones you don't want it to
use unless there's a failure of the array or a site or something like that. And in which case, you're telling it it's OK to use those. But these are marked as active IIO here. And yeah, I think yes. Oh Right. So the pot object. So again, with, with pure and vals
with me uh multiple storage containers we that that pod object is, is a critical part there. So the and also for active cluster. So the, the, this the pe is in a pod that's stretched between the two arrays. OK. And then this is where the array goes down. Um You can see struggling the load but it's, it's down.
So this array is not functional. And when we go back to, to the center, we go look at those pads again, we actually see that there are eight to that protocol in point. Now, instead of the 16 we had before because we lost an array, we lost half of the paths. But from the V MS perspective,
in this circumstance, no noticeable impact that the VM stays up. VM stays healthy and running even though it was previously like half the paths were connected to an array that doesn't exist anymore. Um And then the next thing we're gonna do 22 of those hosts go down. So those V MS that were on those hosts because of how I've configured VM ware metro storage
cluster, they will get powered on, on an available host. Um This is where most of the editing is. But so you'll see IOVM one and two down there, which were on those two hosts, they will show is inaccessible. There's a lot of scary warnings because VRH A is doing its thing. But you can see now they like before where they were at the VD bench screen where they're
generating IO now they're now they've rebooted on to those other hosts. And, yeah, um, I showed the, I, I showed that screen. I'm sure you're familiar when, when you move, if you storage V motion of VM from one host to another, that console gets stale and yeah, it, it has to get refreshed and reopened. But this, this VM came back up by all by itself. I did not do anything.
I didn't touch anything because of how VM Ware Metro storage customers configured. It's all good. Just got powered on, on a different, on a different uh ESX I host that's actually up and healthy. So yeah, that, that is, yeah, I think that's all I wanted to cover really quick. One of the things I wanted to mention,
part of the reason this has taken so long is if you're familiar with H A, we have something called V MC P. So VMWARE component protection that wasn't supported with V VAS. And what that does is that monitors the heartbeat of the application and the VM itself. So that when that VM fails in a situation where it's a stretch cluster H A will understand
that. OK. This is on V Vas, but I still need to fail it over because remember there's a whole bunch of individual objects. So V MC P previously, like I said was not supported. So that was a huge heavy lift to get V MC P working on vals. And that's part of why it's taking so long.
That's one of the components.
Want the ultimate in data resiliency, availability, and mobility for your VMware environments? Are you looking for a zero RTO and RPO data continuity solution? Do you want granular control of your virtual machine data? This session will cover the benefits of using Everpure ActiveCluster™ technology with vSphere Virtual Volumes (vVols) and show how stretched clusters can help balance virtual machines and application workloads between geographically separated data centers.
We Also Recommend...
Personalize for Me