Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
45:41 Webinar
Driving Great Developer Experiences to Delight Customers
In this session, we will explore the strategies and tools you can use to create an exceptional developer experience. Using real-world customer examples, we will demonstrate how organizations are leveraging best practices to accelerate application development.
This webinar first aired on June 14, 2023
Click to View Transcript
Welcome everybody just to buy a show of hands or are there any developers actually in the room? Oh, nice 11 developer. OK. So we might have to ask you a question later then. Uh This is our session on driving great developer experiences. So this is tailored towards developers, but it might not be what you think.
Uh My name is Eric Shanks. I'm a technical marketing engineer with port works. Uh You can find our Twitter handles up here and I'm joined with Pasha again part of the technical marketing team. And uh this is all about what developers want, right? So maybe Bob, what do you think developers want?
I don't know uh I DS visual studio code. I don't know. Yeah, it's wrong. OK. Uh How about how about try again? I want cloud credentials so I can spend as much money as I can. Oh, that's also a good answer. Completely wrong though.
Uh developers actually want storage services. OK. Wait, don't get up and leave on me. I know what you're thinking. I see some of you rolling your eyes right now. But listen, we're at pure accelerate. You knew storage was going to be in here somewhere, right?
Um Let's take a little trip back in time so we can understand what we actually mean by this. Like, how did we get to where we're at? So, uh originally, we used to build monoliths, we used to build these on virtual machines or we used to build these on bare metal servers. Uh An example, monolith that I like to use is a website here from long ago,
you might recognize it. Uh They used to sell books here on this website. Uh It was a monolithic application, there was a web layer, there was an application layer and there was a database layer, but all of those things were were a single monolith.
We're really focused on the application layer here. Um Meaning you know, the Amazon web page, for example, might have had a cart service or shopping cart service, right? Something's got to manage how you buy things, a return service, a search service promotions, all of these different things that you have to build into that app or that website are all contained in this one app layer.
That was the monolith that we were, that we were managing. Um monoliths had a lot of problems. One of them being, everyone had to share the typically shared the same code repository. Another one being that every service in the application had to be scaled at the same time. So if you had an application that had performance issues you had to scale the entire
monolith just because maybe the cart service or your search service were requiring more resources. And each service in the application used a single database uh that was available for it, right. So typically back when we were on a monolith for everything, you had a couple of options, it was either a SQL database or an oracle database.
Those were generally your two options. Um So we've got our monolithic app, we've got a web server here that sends us to our monolithic application. It's got all of those individual services in it and we share that one database in the back end. And we've got our database administrator here saying, you know,
man, I sure do love databases. I love working with databases and all these things, right? It's a database administrator. Of course, they like that. But some of the challenges that they had was they were all sharing the same code repository. So the search team would say who we just finished updating our search service and we
would push our application up to our version control repository. And the search team was happy that they had pushed a new release. But all these other teams would say, uh you know, my service is broken now because the search team pushed something to our main branch. And now all of a sudden the dependencies that I had for my application no longer work.
Um It would happen across other teams that were also building things for the monolith. And of course, as the monolith grew in size, it would take longer and longer and longer to download all the code between all the version changes. So um developers pushing all this code to a single get get repository uh was a bit of a challenge. So we've begun changing those things to micro
services. So the front end still looks kind of the same, we've still got a web server, the front ends like a load balancer of some sort. Um But then each one of those services becomes its own application, we call those micro services, right? And one of the things that changed was each of our teams now has their own version control
repository. So we kind of solved that problem, but we've also introduced some new problems with micro services. Now, each one of those services has their own database if they would like. Right? So now we've increased the number of databases that we have to manage microservices gave us a lot of other uh important uh
features, things like scaling. Now, we don't have to scale that entire monolith all. At one time, we can scale individual parts of that monolith. So if our search service is the one that needs more, um we need more CPU or memory or whatever, we can scale just the search service and it gives us a little bit more uh uh telemetry information for us to understand how our
application is working. We don't have to just guess our monolith uh was using too much CPU which service was using too much CPU. It's a little harder to do in a monolith. In a micro services architecture, we can see each one of those services and we know how much CPU and memory those are using, we can scale a bit independently.
And of course, each service has their own database. But when we started breaking monoliths into micro services, each of those micro services got to use their own databases. They also got to pick in a lot of cases, their own databases. So now we're in a situation where not only did we increase the number of databases that we
have to manage, we also increased the different types of databases that we have to manage. So now we can be using things like mysql or post, we can use red. Um We can use Kafka cues not necessarily a database, but maybe we're pushing our data into a Kafka Q where another service is going to pull that data out and do some sort of processing with it, right? We have all kinds of new architectures now
based on the fact that we just split that monolith into micro services, but that's introduced new challenges. So has anybody in here read the book, the Phoenix Project. If you haven't, I highly recommend it. Uh It's a great book that talks about probably lots of things that you've encountered in your
day to day life at work as an it professional. Um But one of the lessons that comes out of the, the Phoenix project comes from Bill, the mentor and they're comparing the software supply chain with uh manufacturing. And he says in the book, any improvement made, not at the bottleneck is an illusion. So if you're, if you've got a process that takes many steps and you have a bottleneck
somewhere along that process. If you're making improvements anywhere along that supply chain, that aren't at the bottleneck, you're fooling yourself. You're not helping provision anything faster or you're not getting code out any faster. It's an illusion, right? So you need to be focusing on the bottleneck.
Well, what is our bottleneck? Our bone is data. So you've got, we've got one of our team members here. Uh that says, you know what I need to start writing some applications and before I can write an application, I need a no SQL database, right?
Their specific service needs to use no sequel. As opposed to a relational database. I'm just gonna open a ticket to our service portal, right? We're talking about the way we used to use ITSM and he's thinking it should be pretty fast, but we just looked at how that application looks and it's no longer this one application that needs a single database. All of those team members now are saying before
we can start writing a uh our application, we need to each have our own databases deployed, right? So they're opening tickets and our DB A is over here who used to love databases and now he's seeing, you know, three tickets per team member because they're trying to get production DEV Q A all deployed for their database before they start writing application code.
Um The DB A is also trying to do other things. They're trying to do typical DB A type work, right? They're doing indexing on databases, they're doing troubleshooting and patching, they have to manage security, they're doing encryption. All of these things are still part of the D BS job. Um but they've increased the number of, of
databases that they have to manage and the types. So the new challenges mean we have to build, build some new solutions. This is where uh Kubernetes kind of comes into play. So think further back, we used to do everything bare metal. And if you needed to go and deploy all of these things in a world before like virtualization
happened, you'd have to open tickets with network administrators, storage administrators and compute administrators, right? You'd have to build all these things out before I could ever get anywhere near building a database virtualization came along and it was a platform. So instead a lot of these things were done behind the scenes and when you needed resources
for your applications to be deployed like a virtual machine, you had to open a ticket with the virtualization teams to build you a VM and the networking and storage and compute was already built for you. You're limiting the number of tickets and like churn that you have to have before you can get your applications built. So virtualization became a platform for us to
use. Um Cober Netti is becoming that new platform, but Kubernetes is becoming that new platform um for the multi cloud or hybrid cloud because we've got four different environments that we could deploy to. We've got Aws and we've got Azure and we've got Google and we've got Vsphere, but Kubernetes can land on top of that.
We don't care what the underlying cloud is or the underlying environment or what storage is being used. Kubernetes is that platform. So now we're asking the Kubernetes team, the platform engineering team to build these services for us and we can run all of our databases. So now if we're using Kubernetes as a platform, we say,
OK, we've still got to deploy all these databases before we can start writing code. Um I need a no SQL database, it should be pretty fast and they can get self service access in many cases to Kubernetes because Kubernetes is going to be ubiquitous. It's the same everywhere, it's being deployed. But underneath that, you need additional services for data and this is the data service,
it's part. So Kubernetes does a great job of um standardizing the way we do networking and compute and we how we do deployments. But it's missing features that you would need for an enterprise class application. You can't deploy anything with state full data in it. Nobody would deploy a database to production if it didn't have things like backups or high
availability or disaster recovery because if you lost that, it was important to the business. So Cobert needs to be paired with a data platform so that we can still get self service access to our resources. So I'm not sure what your background is in the room.
So a little bit of information about how Kubernetes works with persistent volumes and storage. We've got a typical storage system here that's orange for reasons that I won't go into. Um But we've also got a Kubernetes cluster and typically, if I wanted to deploy resources, uh uh state full resources to the knas cluster, I'd have to go into the storage system,
I would create a volume of some sort and then I would have uh an abstraction in Kubernetes called a persistent volume. This is how Kubernetes references this storage volume for us in an external array. And then we can deploy our pod, which if you're not familiar with Cubers, a pod is basically your containers.
The container uses an abstract called a persistent volume claim. And the persistent volume claim takes our persistent volume and maps it to our container so that we can we can manage them independently. That's a little tedious. And Kubernetes gave us a way around some of this by using a storage class.
And the storage class is a way to provision these persistent volumes in a more automated fashion, right? I don't need to go call a storage administrator to build me a volume on our storage array. Before I ever do anything in Kubernetes, the storage class can do that for us. So our storage class gives us a desired state of what we want our persistent volumes to look
like and we can change the characteristics of those volumes. But this is just an example here. We've got our pod, our container deployed in Kubernetes and a storage class is also deployed in our cluster. When I want A I, when I need storage for my container, now I just have to request my persistent volume claim and tell it what storage class I'm going to use.
And when I do that, the storage class reaches out to the storage array, builds the volume and then creates the persistent volume. So it nails all that up for us automatically. So that's our self service access. So that's helping us. So earlier when I said, what, what do developers want? They want storage services,
let's tweak that just a little bit. They want self service storage services, right? They don't want to be waiting for these things before they get started with their work. They have their own deadlines and they're wasting a lot of time just sitting around waiting for environments to be provisioned. So now port works is that data, that data platform that works with Kubernetes.
So now Bob is gonna tell us here how we do some of these things to make them enterprise ready uh in a self service fashion. So Bobby, how do we handle high availability and reduce our outage during our uh uh uh uh during a failure event? How does ports do that? OK. So uh what we have in this section or in the
next few sections are just demos about how port works enable self service for developers without even bothering the developers in the first place, like everything is transparent to them. They don't have to worry about configuring these things and including these things in their tickets, they know what storage class they should be using and what how port works under the covers
will handle high availability, for example. So uh if you go to the next slide before we look at the high availability demo, we just wanted to do a quick intro on how port works is actually deployed on your communities cluster, we have a couple of different different deployment models port works being that software defined storage or cloud native storage layer can run on top of your communities cluster itself.
So uh I know Eric pointed out all the different distributions uh that you can run port talks can run on each and every one of them. You can have a disaggregated mode where a subset of your nodes in your communities cluster act as storage notes. And then you can scale up or scale out your compute nodes based on your application requirements and your storage notes can always
remain constant. Uh And the most popular mode that the which is the second mode, the hyper converged mode is where each node in your cluster is actually a storage node as well. So each node is responsible for provisioning those volumes and it can host those community spots as well. So that's how a port work deployment looks like
in real life on your communities cluster. If you just take the same example that Eric used a couple of slides back talk about how storage classes work uh with port works, you get an option to customize your different storage classes through different parameters here. As you can see, we updated the replication factor to two.
Again, this is going down the high availability track and how port works enables that. But any volume that gets provisioned by this storage class has two replicas. So it it has this primary volume, primary volume and then it has a replica that's running on a different node in your communities cluster. Uh After which like again, it automatically gets mapped to a persistent volume and gets
mounted to the pod using the PV C object. So if a node goes down, that's hosting your pod and your persistent volume. Whenever communities fails over your port to a new node in the communities cluster, it redeploys it on a node with the volume replica already there. So it ensures data locality. It ensures that the application doesn't have
down time. Just a matter of a couple of seconds, the time it takes for communities to reschedule ports and you have your application back up and running. So with that, let's jump into a demo and look at how uh port works enables high availability. So in this case, what we have is a three node, Amazon Eks cluster running in us two and
all three nodes are distributed across different availability zones. So what we want to show you is without the developer even having to worry about high availability, how port works can just enforce this anti affinity rules. So the volume and its replicas are spread across different A CS. So if you lose an easy, which is what we'll simulate in this demo,
your application can still come online with access to all the information. So we have a simple application with a front end component, a back end post stress board. And that part is backed by a persistent volume claim that's running on top of port works. As you can see the application is a really simple one.
Wherever you click, it generates a logo and that X and Y coordinate is basically stored in the post stress database. So that's the state full component. Uh If we look at the volume itself and do a volume inspect, it will show you all the different details around that port works volume. So we're using the PXCTL or pixel storage utility or cli utility that port works has.
And if you look at the volume and the details, you can see where the volumes are or how the volume is actually created where the replicas are spread out across the cluster. Since we are using a storage class with the replication factor is set to three, you can see we have three replicas spread across three different nodes. And since these nodes were already running in different availability zones,
you are safe or you are insured against an availability zone failure because you already have all your data. Uh If you look at the volume consumer section, you see that's the poster spot that we looked at earlier and it's running on the same note to simulate that a failure. What we'll do is we'll cordon off the node, we'll delete the port and have Eks or have combin reschedule it on a different node which
gets the plot on a different availability zone. So if you look at our application, if if you look at our port, it just takes a few seconds for the port to come back online. And now it's running on a completely different communities. Note again, if you're talking about the developer persona.
They didn't have to worry about any of these things. All of this is transparent to them like you, you don't have to have page duty requests come in and jumping on, on calls right now to figure out how to bring your application back up. Everything is automated for you because of the way port works provides high availabilities for your application data.
Uh If you look at the new node that your port is running on, you can see 34.7. And that's also the uh the like that's the node where the port is running. And if you do a volume inspect again, we can see that that's the new uh uh that's the node that's actually hosting my replica as well.
If you go back to our application tab, all the data is still there. I can continue using my application. And that's how like that's a quick one on one high availability demo and how port works helps users. OK. So now what do we do about security? And it's gotta be self service security.
Yeah, everything has to be self service. Come on. Uh So uh talking about security, right? Uh when it comes to security, there are two things that everybody needs to keep in mind. The first one being a role based access control. So we are following the principles of least privilege. You, you don't allow access to uh to resources
that shouldn't like a user shouldn't have access to a specific resources on the same cluster. If you're running a multi tenant environment, how do you enforce that? And the second part when it comes to securities is how do you encrypt your data address? So that uh if I get access to your cluster, I can't actually mount your volume and start reading all your data.
So from a security perspective, if I can make the slides work, OK? From a security perspective, that's the challenge we are solving for, right, we're solving for a challenge where you want to run a multi tenant cluster. But you want to make sure that user A doesn't have access to the resources in user B's name space.
So the way port works does this is by using the concept of JW JWT web tokens and enforcing it on your clusters and you can have different roles inside your communities cluster itself. So I can get view access, I can get admin access to all resources in a specific name space. And by defining these roles, I can ensure role based access control for uh all the storage resources that are part of your communities
cluster. And then when we, when it comes to volume encryption again, you don't want your data sitting in plain text for anybody to mount your volume and start accessing it. You want your storage solution to encrypt all the data at rest, regardless of whether the developer wants it or not.
So this is again taking away that headache from a developer perspective, I don't have to worry about writing encryption inside my application. I want the storage system to take care of it. That's where port works can help because port works allows you to encrypt all the data at the storage cluster level by using a single key or if you wanted even more granularity. And if you wanted to have uh keys associated
with individual persistent volumes, if you're running a multi cluster, you can, you can implement that using port works as well. So that's how works plays into the security and provides that self service security element eric. So capacity management was always a thing that also caused tickets to come in, right? If I was running in something in VM Ware and I
ran out of disk space, I had to increase the disk space somehow and usually had to call somebody to go get that done because I couldn't just do that for my application. I the app owner, how do I handle that? Right. Uh And all of those happen for some reason at 2 a.m. in the morning, right? Like 2 a.m.
is the best time for storage to become. So that's what like port works, autopilot heads with. Uh we allow developers or administrators like you can to set their own rules and the port works autopilot which is a rule based engine, monitors those rules and monitors those conditions and once those conditions are met, it performs certain actions for you.
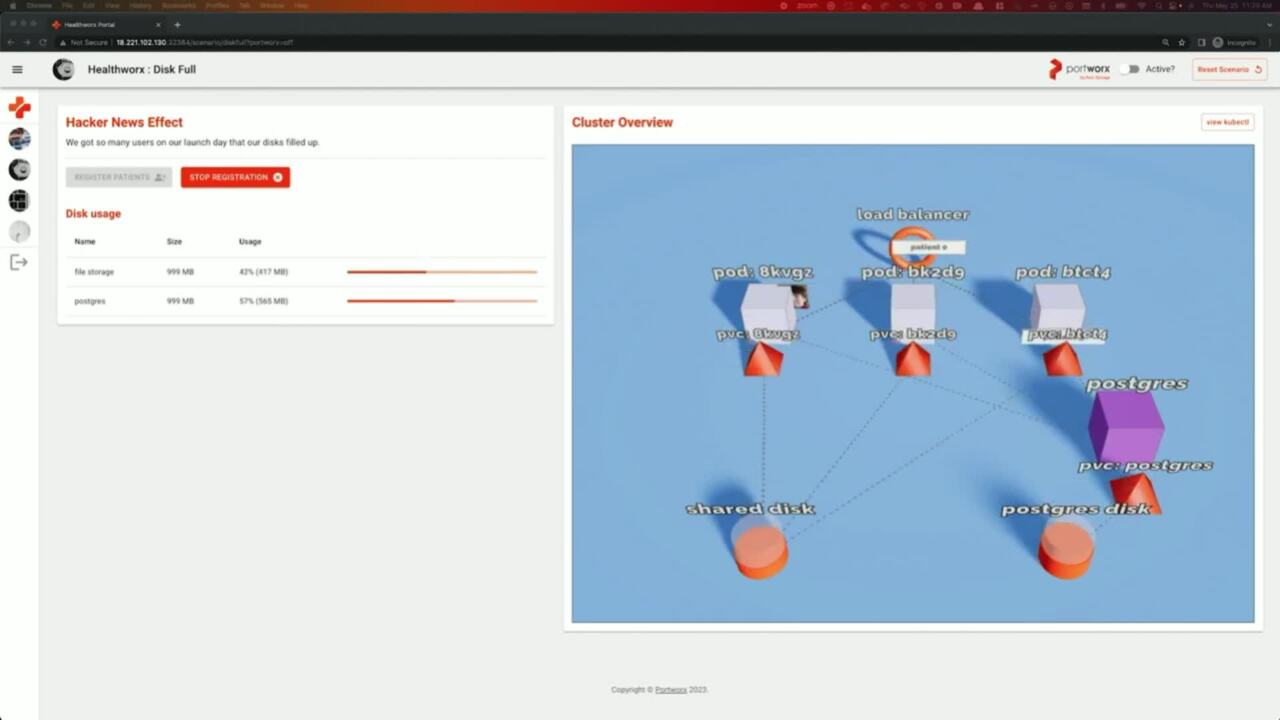
So let's look at a quick demo of this in action. Again, we have a lot of demos. So if you have questions at any point, feel free to like interrupt us and we can talk about some things in a bit more detail as well. So here we have another demo application where we are you looking at a scenario where our disc gets full? As Eric said, you don't want to be in a
situation where your app is down because you're out of storage. Uh We are going to look at a scenario when you don't have port works and what happens and how your application actually goes down. And a scenario where you enable works, enable ports, autopilot, configure a rule and how port works handles all the automated automation and provides you with
automated storage capacity management. So we have a simple application where you have a shared disc where you are storing user images and then a post disc where you are storing your register or patient data. As soon as you start registering new patients, you will start filling up your back end databases or back in persistent volumes. And at a certain point,
if you're not monitoring this actively and logging into the cli and expanding those volumes, uh manually, your application will go down. And obviously this is not a scenario that you want, especially not at 2 a.m. That's where that's why like we will use the pro autopilot functionality and see how it can help admins like Eric or people like Eric who don't want your application to go down.
So uh we'll uh since our application is done, we'll wait for a couple of seconds and then we'll activate both works. Again, this is something that we have done in this application. This is real uh but just a good U I way to show things. So this is OK, this is not the best for the screen, but an autopilot rule basically means that you are specifying a set of selectors like
which persistent volumes should this action be applied to? You're specifying a bunch of conditions. So in this case, we're like, OK, if my persistent volume exceeds that 60% threshold, which means I might be getting closer to get my volume being full, perform certain action for me. So in this case,
my action is just double the size of my persistent volume. So to start with our application, we'll have one gig of storage for both of those shared disc and post disk respectively by configuring that autopilot rule and applying that against my communities cluster port works is monitoring your utilization for you. It's looking at how much storage is being actually consumed by your application.
And as soon as it crosses that threshold, the 60% threshold that we have it, it will perform that action for you. But as an admin. You also don't want to be in a situation where automation takes over and you're just increasing your storage utilization uh with, to, to handle those scenarios, we have uh a different parameter where you can set a maximum size when it comes to persistent
volumes. So keep doubling it till you reach, let's say 100 gigs. And then at that point like and the admin should ideally come back and expand and make sure that the application is still working fine. So uh OK, this is Google one second. I'll just open up the local copy.
Sorry. Yeah. OK. I think this is where we were. So port works is enabled, autopilot rule is configured. We are writing more and more data as we cross the 60% threshold on those persistent volumes, we will uh you will see that port works automatically perform those actions for you and
increase the size of your volumes from one gigs to two gigs because we wanted the to be scaled up by 100%. So uh just a few more seconds and you will see that in action. Any questions for auto pilot till this point? Ok, cool. And this can be done across different name spaces as well like it doesn't have to be one
rule for all name spaces. You can do a name space, label selector, you can do a volume name, a label selector so you can really customize this and, and, and you have board works, autopilot, perform these actions for you. So now that we have crossed that 60% threshold works. Autopilot is now going to trigger that rule and perform that action on your behalf.
Uh And you'll quickly see that your one gig persistent volume post person is now a two gig persistent volume same with file storage. So the storage underneath uh underneath the covers expanded automatically, your application is still working. There was no down time. You didn't have to wake up at 2 a.m. And uh yeah, you still have a job the next day. So uh that's,
that's how autopilot can help you. Let me switch back to the slides. OK? OK. Same thing with disaster recovery. Then I can't just put an application out there and assume that if the you know a meteor hits my data center, the business is just done. We need a contingency plan for that. How do you do that with? OK. Uh So I, I haven't met as many developers who
care about disaster recovery, but there are a few and as an as a, as an operator and as an administrator as an SRE you definitely care about disaster recovery. So let's talk about how port enables Dr uh So board works enables, it provides a couple of different options for inside the same region or metro situations. Uh You, we can provide synchronous disaster recovery, zero RPO,
zero data loss. So if your primary cluster goes down, all of your components are running on the secondary cluster. If you wanted a multi region architecture where let's say us east one to us two, if us east one goes down for some reason, you can still recover their applications on us two with a 15 minute RPO. So both of those scenarios are supported with
port works. Uh Here, what we are doing is we're using uh an application that Eric has built called port works barbecue. And this is we have deployed this application in such a way that it has a front, a few front end parts. But the back end component which is a Mango DB database is still running on virtual machines, but it's running on a virtual machine on top of
Cuban. So it's using the open source cube word project. In this case, we're using an openshift cluster and using openshift virtualization. And we're talking about how works provides you the ability to build AD R solution for not just your containers but also for your V MS that you have running on communities. So the application was just placing some orders, hopefully hoping for barbecue to show up.
But I don't think that will happen today. Uh But uh that's what the application looks like. You have a few front end boards, you have the virtual machine object that's still running on my open openshift cluster and then we are going to set up disaster recovery. So this is a synchronous Dr solution. Both of my Openshift clusters can are in that 10 millisecond latency are able to meet that
requirement. So it's two Openshift clusters, one stretch board works cluster. So all the storage replication happens at the storage layer under the cover. So before even a right is acknowledged back to the application layer, it's copied to the secondary site. So you don't have any data loss. If your primary cluster goes down,
all the data is already ready on the secondary site. Uh And then for the disaster recovery solution, you need something like a recovery plan. This is where a migration schedule object can come into the picture. Let me just pause it here, hopefully, but buffers but migration schedule if you're not able to read this, uh it, it allows you uh it allows you uh for a way for you to configure
how or how to customize your DR solution or DR plan where it links to your name space, where that application is actually running it links to the schedule policy. So even the storage replication is continuous, uh your community objects will need to be moved from one cluster to another, from your primary to the secondary. And that's where your schedule policy comes into the picture.
We'll set up a few flags like we don't want to start the applications after the first migration because again, I only want to bring my applications online on the secondary site in case of a disaster, not during first migration. So once you have configured all of these things, OK. I'm just going to pull the local demo. Sorry guys.
It worked before it worked on my laptop. Eric. OK. Once we have our migration schedule ready to go, we'll go to the secondary site or secondary cluster and make sure that our cluster is ready. You'll see. It's a on a second openshift cluster, three master nodes, four worker nodes. Uh If you look at the resources already
existing in that demo application name space called app dash demo, you won't see any parts, you won't see any persistent volumes already created. Uh When you actually deploy that migration schedule on the primary site is when we'll go ahead and create those resources and make sure that they are ready to go in case of a disaster event. So we'll apply that migration schedule and at
each scheduled policy interval, it creates a new migration object. So first migration happens as soon as you apply that uh YAML file. And if you look at the details, you see uh our our migration schedule is uh already running. It's in a successful state. If you look at more details, it shows you the migration has been successful. All 10 communities resources have been migrated
from primary to secondary, the volume is zero because that is handled at the storage layer. Uh If you look at the secondary cluster, now we'll be able to see all the different resources like the service objects like the VM objects already ready to go and ready for a disaster event. So if you do a OC get all in the APP dash demo name space, you can see we have service objects. We have our routes,
we have virtual machine in a stopped state. One thing to note here is our deployment object is actually set to 00. So we don't want your application to come online. After the first migration, we store that metadata for you and in case a disaster strikes, that's when we'll actually spin up those application ports. So your application can come back online.
So let's go ahead and simulate a failure. Let's try to restore your application. So you don't no longer have to worry about since this is true, disaster recovery for communities, you don't have to worry about deploying a new cluster, pulling backups from an object bucket repository, your your secondary cluster already has your application ready to go one single command which is activate migrations in that
name space and we'll start deploying those pods that are missing in the first place. So we'll deploy those three additional pods we'll deploy or we'll start the virtual machine that's running my Mogo DB database. Once everything is ready to go, we'll make some changes to the load balance at end point. Because again, with Dr you need to do that, you need to make sure that you can access the new
endpoint for your application. And once that's done, once everything looks good, you can start uh your users can continue using your application. And we'll also make sure that the orders that we placed before are still there and I can maybe place a couple more new orders. So uh we are just editing the route, which is making sure that our load balancer can talk to
the new application instance running on the secondary cluster. So instead of OCB dash zero OCB dash one again, don't name your clusters like this. This is just for demo purposes. Uh But yeah, once, once you apply that, uh once you save that configuration for that running round object, uh you can now start using your application.
So we do one final check. We do a OC get all in the dash demo name space. Uh Just make sure that all of our pods V MS persistent volume, everything is back up and running and then we'll navigate back to the U I and make sure everything looks good. So uh as you can see the route that we had updated is now uh current like OCP dash one is where we can access our application.
Let's copy that endpoint, go back to our browser and then try to access our application. So if everything has worked, I should be able to log in to the same application using the same user name, password combination. I should be able to see the same orders in my order history. So demo at port works dot com with a super secure password.
Uh uh I I'm I'm able to log in. So that means at least one collection inside my manga DB database is working and then I can see all my previous orders as well. So this is how port works provides that disaster recovery solution. Again, this is this was easy to develop because all you needed to configure was a single migration schedule object to point to your where your application is running.
And port works basically does all the work under the covers for you. So let's go back to the slides and see what other questions Eric has for us. Yeah, of the database. Are you saying that that in the the gas storage? Then there is. Yeah. So the storage replication handles that is done
at the port works layer itself. So port works is that software defined storage layer. So it's running on top of your cluster. So when you're deploying that Mango DB persistent volume object that is running on a port works storage layer or storage pool and any right is automatically replicated to the secondary site. So that's how the replication is handled at the
storage layer. Yes. Yeah. No. Yeah. And uh that's another good part of having a cloud native storage solution that you're not reliant on the features of the underlying infrastructure. You can get the same functionality. If you're running in GK, you can get the same functionality if you're running between two bare metal environments
with both works on top. So you get the same functionality everywhere. Yep, it smell like. OK? No. So uh to just to repeat the question uh is, is the disaster recovery replication or the storage repli uh dependent on the type of database? The answer is no, we can work with any and all
databases. Uh We can also provide you with uh pre and post access tool. So to make sure that whenever the replication is happening, oh, in in SDR case, it's obviously done uh in an application consistent way in an AYN DR situation, we can also make sure that it's application consistent at that 15 minute interval. So it's not clash consistent.
Yeah. OK. So what about data protection? I don't always want to fail over my entire data center to another data center if I have lost some sort of data or someone messed up uh configuration or something. Yes, how do we protect that data? So we have a a couple of different scenarios for that Eric. So uh like I'm sure admins in this room who
have managed some sort of infrastructure have had requests from their developers that oh, I accidentally deleted something. I had a bash script that basically deleted my volume. Can you please recover that? And again, you can have snapshots of your persistent volume. But with port works. And even with pure, right,
we have a feature called a volume trashcan where we are storing your persistent vol in a recycled bin kind of location. So if you accidentally delete a volume, we have that ready to go and you can recover, recover or restore your volume from that recycle bin or from that trash can and bring your volume back up online. So we'll do a quick demo and instead of trying to use the Google demo,
I'll just skip to the local one. No. OK. Again, a simple Amazon Eks cluster. What we have is we are setting an option where 7 20 minutes is how long we'll keep that volume in the recycle bin. So if you accidentally delete something, you have enough time to recover from that trash can.
Uh we'll deploy a new storage class for this demo. So that storage class, the reason we are doing that is uh if you accidentally set the reclaim policy as delete communities will delete the persistent volume from your cluster if you delete the persistent volume claim object. So you obviously don't want that. You want that layer of safety from the storage
layer. So we'll apply that or configure that storage class on your communities cluster. We'll create a new name space, we'll deploy our demo application. Uh In this case, it's the same application where you click on the screen and it creates a bunch of communities logos and stores that in information back in the post stress database.
So let me skip forward a bit. So here is we have we had the application, we generated some data. Now let's go ahead and be that person who deletes my database or deletes my back in persistent volume. So we'll just delete the YAML file which deploys a post stress in instance in the trashcan name space. And once we do that,
you'll see all the different resources, the parts, the persistent volumes will go away. If we go back to the UI, you don't see any data being written. So that's not a situation where we want to be in. How do we fix this? So you can do this by a simple command with our PXC DL utility or PIXEL utility where it's just a simple volume restore dash trashcan command
which basically restores the volume from the trash can into the storage pool itself and all and then all you need is a persistent volume object and communities to connect back to your application. So 23 steps, but again, you don't have, you don't have to go and find snapshots and figure out which was the right one. You, you, you had your actual volume sitting at the storage layer and you can recover from it.
So once my volume is up and running I I will create a persistent object inside Quin uh If you remember the, the diagram that Eric showed earlier in the presentation where the volume exists on the storage layer that gets mapped to a persistent volume object. That's what we are doing right now when we apply the CML file, and then eventually we need our post stress components to be back online to be able to talk
like to for them to talk to the persistent volume object. So that's uh the same diagram. But in action, once we deploy our post stress component, my application is as smart as port barbecue. So I do have to like reset my front end components. I'll just delete my front end parts and deploy it again.
So it makes that new connection to the post stress database. And once that's done, I can navigate back to the demo app tab. And if I refresh the page, I should be able to see all the logos that I had before. So this is how you can restore volumes and uh from, from that trash can and bring, bring your application back online.
But that's just one component. Er since you asked a fairly large question or a fairly wide question, what about data protection in general? Right? That's where our um backup solution comes into the picture as well. So going back to the self service part where uh as a developer, I don't really have, I want to go to a backup tool and creates uh create
backup schedules for my application. I don't want my to create tickets for my backup admin to create those backups. For me, I want the the data protection solution to be smart enough so that when I deploy an application in a new name space with a specific label, in this case backup equal to two, it automatically backs up that application with the sl a requirements that I have. So that's what we are doing.
We are deploying a couple of different names faces keeping it simple PG one and PG two. PG one has that label uh from the start. So backup. Cool and true. Uh PG two, not really, but we'll fix that as we go through the demo. Uh we, we are deploying the same app which is a APG bench board with a couple of uh per objects.
So it's identical application. We're just deploying across two different names spaces. So you can see the pod and the question volume claim across two different name spaces. And then we'll also verify that our name spaces are labeled correctly. So I will do a clear and do a uh show labels. So as you can see for PG one,
we have backup, equal to two flag is set and for PG two that we don't have that flag. So now as a backup admin, right, I don't, I, I just have to do this once I need to go to port backup, which is the community's native backup and recovery solution and create a new backup schedule. So I can set my namespace label as anything that has the label backup equal to two automatically protect that.
So once I said that it, it identifies that PG one is the namespace that already has that label. I can hit back up and then give it a name. We'll give it something really smart. So, namespace backup label, auto, I guess. Yep. And then select a backup location. Again, we can use a regular S3 bucket. We can use an object lock enable S3 bucket as
well. And then we'll select the 15 minute schedule policy because that's the sl A we want for all of our applications. Once I hit, create it instantiates, the first instance of the backup schedule starts protecting my everything inside my PG one name space. So the two persistent volumes, the five different communities resources that we saw are
now being protected and backed up into an S3 bucket. And again, this S3 bucket can be AWS S3 or if you're using flash plate today, it can be uh an object bucket on flash plate as well. So once the backup is successful, you will see that it's protecting uh PG one name space. So before the next, uh and again, before the next section of uh uh our next
interval of the 15 minute time interval, we'll create a label, the PG two name space as well, call it, call it back up through. And then basically, uh whenever the next instance happens, you'll see that in addition to PG one, it automatically backed up PG two again. So the user didn't have to do anything. The admin didn't have to do anything.
The developer didn't have to do anything. Backups are automatically enabled and this is not just backing up your volumes. This is also backing up all of your community objects as well. So I know we are running out of time today. We did have so many more demos to show you. Uh We'll be at the port works booth inside the zone if you want to stop by and look at any of these demos or have any detailed discussions
around any of these features. But let me just fast forward and maybe um yeah, uh hand it over to Eric to summarize the presentation. As you can see. We, we did come with a lot of demos. Yeah. So basically we, we in the demos, you didn't see uh we would have solved all of the typical challenges that you have for enterprise
applications that are running staple staple data. Uh just like you would do for bare metal or virtual machines, you have to do the same thing for Cober Netti if you're running staple data, and we've solved all of these uh these answers through adding port works data data, uh the data platform to the Cober Netti data platform.
So now I can get self service access to most of these things. Obviously, a developer doesn't have to worry about disaster recovery or backups and things typically on their own. But they do have to wait for some platform engineer to make sure that they have deployed these services in the uh in an enterprise fashion.
So that's what we're trying to get across here. Uh Like, like Bob and had said we've got uh plenty of demos at the booth in the zone. So stop by, if you want to ask further questions about any of these, any of these demos and how they work. Uh Just to summarize what we got going on. There's another session here at three o'clock.
We're gonna be doing uh Port works, uh food services and engineering expedition. We'll be doing a little bit of role playing. It should be a fun, a fun session and then tomorrow we'll have sessions in here all day as well. All on port works things. Uh So please come back and join us. Uh If you need information, more resources that you want to just look up on your own.
If you scan this QR code here, it'll take you to a link where you can get some additional information about Port works, data services. Port works, backup port works enterprise. Yeah, that one question. So if I'm not mistaken, these, these devils are actually available as labs and hands on labs here in one of your room,
right? Uh Some of them. So we have uh hands on labs for uh three of uh three things. Kubernetes 101 has nothing to do with port works. It's just trying to introduce you to how Kubernetes works in concepts. We also have a Port works uh uh uh 101 as well. So then you can see how port works,
adds functionality to Kubernetes that's missing uh to do the enterprise Dr and all that stuff. Uh And then the, the blast demo is actually uh ad R demo. So you can set up your two clusters and do a fail over uh and see your applications come back up. Yeah. Thank you.
In today’s fast-paced digital world, delivering great developer experiences is more critical than ever. Developers are the key to building and delivering the innovative products and services that delight customers and drive business growth. In this session, we will explore the strategies and tools you can use to create an exceptional developer experience. Using real-world customer examples, we will demonstrate how organizations are leveraging best practices to accelerate application development.
We Also Recommend...
Personalize for Me