Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
42:50 Webinar
Efficient Database Data Protection with Everpure FlashArray and FlashBlade
You'll learn FlashArray snapshot fundamentals and how to design a snapshot replication architecture, as well as more about performance tuning backups and how to protect databases with ActiveCluster™ and ActiveDR™.
This webinar first aired on June 14, 2023
The first 5 minute(s) of our recorded Webinars are open; however, if you are enjoying them, we’ll ask for a little information to finish watching.
Click to View Transcript
Yeah, we're good to go. Yes, it's one o'clock. It's time for the The Antony Show. So do you want to tell them how this happens? Every year we get to do this. Yeah. So, uh, on the right side of the shop is Oracle on the left. But at my right and Anthony is is is,
uh, Microsoft. So every year, every year we submit nearly the same session, and the person that's the manager of the contents, like you all should just do this together. And so here we are. So hopefully it means that there's something for everyone because lots of our customers run both Oracle and Microsoft. So it's it's good we're sharing.
Yes. So, uh, these good looking fellas pop my head. That's me, Aikins, uh, principal architect, working out of, uh, looking after the oracle side of the shop. I'm an director, Anthony. Hey, I'm Anthony Noo. I'm a principal field solution architect at
Pure. I focus on relational database systems, specifically SQL server and azure. I'm also a Microsoft MVP. So, uh, I get the luxury of working very closely with the sequel server engineering team on new features and things like that we'll talk about some of those at the end of today's session, So today's session is around data protection and some of the measures you
can put in place to help you out. So really, this is what we're going to cover just to quickly gonna say, you know, what is malware, what's meant. And we make sure we all understand the terms. Uh, I have a background in, uh, in data security. I spent 20 plus years working for an aerospace defence contractor.
So everything I do is around secure data handling. That's why I think that's what I you know. I've been used to working in those sort of highly regulated environments. So I I I'll share a bit about protect a new environment. So think defence in depth. And then, from a pure point of view,
how we can protect ourselves against ransomware malicious intent and also some just general good backup and recovery mechanisms. Yes, so we're happy to take questions at the end, but also if there's something really interesting on the slide, if you put your hand up Anthony and myself, we're quite happy to to field it then. So malware ransomware just quickly So this is a definition from the national cybersecurity.
Uh, it's a It's a UK government agency, and it says explicitly what malware is. So it's when someone takes your machine over, causing it to be used against you, stealing information mining. Cryptocurrency is a really good example of that, but it's it's an umbrella term. Ransomware is a bit more precise. It's a type of malware,
so definition there and is surround. And I guess the name helps Ransomware. It's about taking money out of your organisation by using your IT data so it may be stolen. It may be encrypted. It may be made unusable, but they are holding your data to answer.
It's strange when I talk about Ransomware and I do. There's lots of conferences, people think, Oh, it's something really complex, You know? I could never do that. They must be the best guys in the world who can write this stuff. That's not the case. You can go to the Internet.
And if you look for Ras kits, Ransomware is a service. You can find some scripts, and you don't need a, uh, a degree in computer science. Go to this sort of form fill in the information. What payload you want? Who you want to attack? How much you want to, Uh, charge, Hit the button.
And it'll give you a, uh uh, an email that you want to send out or a a bit of malware that you might want to put in a USB stick and leave it a conference on someone's desk and see if someone picks it up and uses it. You know, don't ever pick up a USB stick that really easy to use. Classic model. The writer takes a percentage of your take.
So as the the user of the malware, you take 80% revenue. But the creator of that script, he gets his cut as well. He gets 20% so really easy to use. So, you know, that's why we sell all of them ransomware. You know, when it hits, it can be really public,
you know? Think of it as the the the blue screen of death that we used to see in the windows in two days. Uh, this is an example of a Deutsche Barn train table. So every train station in Germany had this pop up. Not great. Everyone knows that they're being compromised and doesn't want to get on a train.
That's the one o'clock incident there. But there's more and more versions of malware comes out, and it's not just trains planes. You know. There's two examples there railway line and their airline, but also schools anywhere where there's data anywhere. There's value in it. You know, you're likely to be attacked so all
your organisations could be exposed to this. It's not slowing down, you know, this year we've seen multiple attacks, and they continue to grow. Continue to become main news on lots of news outlets globally. And this is where pure comes in, you know. So when we think of where it's easy to think,
it's about your production database, and we put lots of measures that look after our production database and rightly so. But it's not just our database we should be looking after. We also need to be thinking about our backups. Just some numbers, you know, bit scary.
Developers of these ransom quit kits are getting better, their dwell times coming down, you know, we expect it to be less than 20 days in 2023 so this is the time they come on their system and compromise your platform, get the information they want to get in and out. They know the measures that vendors have put in place like pure and other storage vendors.
You know, we're looking for IO storms looking for changing data reduction, looking for access in unusual hours. So they they try and work against that. They protect themselves against that. So they don't need to encrypt the whole database. Just a couple of blocks here and there. Make it unusable. So that makes it invisible to detection.
They could do this during the normal business day. So you don't see any unusual activity. So, you know, we always have to be on the card. Backups are our last line of defence. No. If your production database is gone, you want to go to your backups?
So you get this pop up. What do you do? Do you pay the money? Take your chance. Roll the dice? We're in Vegas. Why not? The chances are that if you pay, you'll pay again and again and again. And that's what they rely on.
That you're gonna come in. You think it's too complex we can't recover. We've got no choice. We think as pure. It's such a big thing to protect you in the new version of purity. It's on by default. Save most snapshots. So I just learned at lunch literally 15,
20 minutes ago that some governments are going to fine you if you pay. And so that gets to be to get double dipped against in that scenario, to prevent the motivation of actually paying that ransom and invest in your infrastructure to get you to the point, you can recover without that. So what can we do now? This is where we had to start thinking the
security onion. You know, we start at the outside, you know, policies, procedures, physical security, network security, host security, application, security. And the heart of it is the data. That's the value. That's the bit they're after.
So, you know, think about the protection you want to put in place, think about how you organise it and have visibility, your database, plus the infrastructure. So start with policies, procedures, you know, training education, telling people not to, uh, open up the emails. They don't know where they came from or stick
in USB drives physical securities. It was easy when we had physical places and there was someone on the guard outside or a key system to get you in the building. Yeah, sometimes they're working remotely. It's not easy. So we need to think about how we do this. You know, looking at the data. Look at the platforms.
Make sure your hosts are fully patched. Only run the services. You need unnecessary. Turn them off. In the organisation I worked for, we will turn off banners of a system So we didn't advertise what operating system it was because it gives you a clue. The more you share, the more you expose, the easier it is to be vulnerable.
So make sure your servers are hard and make sure your application service are hardened your applications as well. There's no point spending all the time having secure platforms. If your application servers aren't being maintained and your applications as well, and then finally your data, you've got to know where your data is.
We may know where our production data is, but development test copies. When you take a clone, do you know where that goes? Who's got access to it. So think about all of that. One of the bigger breaches I was involved in earlier in my career Um the CIO.
Came to me and was like, Hey, I want you to build this integration and literally it was an S FTP integration to move data between site A and site B. And this is gonna sound kind of egotistical, but I'm like, that's kind of like having me do that's like, you wanna fly with a sledge hammer? I'm like, Why do you want me to do this? And then what I found out was it was the data
for this particular integration. Someone downloaded a test copy of the database to a laptop the office was broken into. It just happened to take that laptop. It was one of the largest data breaches in North America at the time. And so it's not just production systems, but the developers that are working with that data to build integrations,
right? And so we then had to go and fix all of that and undo that and come back with a secure integration. So So we see more and more organisations mandating that their downs street systems are used in some form of ossification so that you don't have production access if you don't need it. You know the need to know the, uh if you don't
need access to production databases, don't have it. Protect yourself. Protect against the organisation. So protecting our databases. So for an Oracle side is very much an oracle position. You know, we've got some advantages here. Uh, most Oracle databases run on block.
So if you've got a malware coming in, it's most likely you're gonna be attacking a file system. If you're running or a SM on block, you've got some protection out of the box. It just makes it a little bit harder. It slows you down. You know, if we are using a SM. A SM wheel driver is your friend.
This gives you another level of protection as SM philtre driver means that only the Oracle process can talk to your block devices. So someone's on the server. You know they can't. They can't see the file systems so they can't get those encrypted. They can't delete stuff and they can't only the
or process the database. If all the features that Oracle has that don't exist in SQL Server. This is the one that I want the most having the direct blocks access from the database engine. But that's never gonna happen. Not now. All right, So, uh, data guard, uh, is another way we protect
our local databases. Uh, I would say protect, but it's, you know, it's a It's another roll of the dice. Here we are saying now we are our primary database on one side, and we have our standby database in our secondary data centre. There is no replication between them. It's it's a redo stream.
So it's not file based, So it could be that your secondary data science hasn't been compromised. So touch wood, you get your primary site compromised, and you can fail over to your DR site, and it hasn't been touched. That's assuming that the malware hasn't done its job and, uh, gone everywhere in your organisation. So don't rely on a SM don't rely on redo
and stand by because they may save you. But they may not. Yeah, in that scenario, whether it's availability groups or even our array based replication with active DR, I always combine streaming replication technologies like that with the snapshot technology at a periodic intervals so that you can control the recovery point.
I might need to go back seven minutes ago on the Fail over because something might have happened on the database. But if it's a streaming replication technology, its job is to keep the remote site as up to date as possible all of the time. But I might not have to go back to a previous recovery point. So when you are looking at those kind of Toppo
couple those two technologies together so you can control the exact fail over point, find me snapshots. So that's exactly that. You know, when I look at my applications and we're doing the recovery, uh, think of the database but also think about the way the database lives in an environment. So the application code,
the binaries, uh, what you don't want to do is restore the database back and you haven't cleaned the server up. And the, uh, the binaries have been compromised. So they just reinfect the database, So use the storage snapshots. Nothing faster than a pure storage snapshot metadata only, but also make sure that it encompasses all the files you need not just the database.
I'll let you have this one. Hm? You have this one. You want me to do this one? OK, so automation is near and dear to my heart. The last thing I ever want to do when I'm in AD R situation is think right. I wanna execute. We've all thought about building run books and doing these things.
And what I like to say with all the technologies that are listed on the screen here is we'll meet you where you are in your automation journey, right? If you're in the terra form world and you're building playbooks and building automation around that, we'll be there for you. Uh, generally on our my side of the fence,
it's gonna be powershell your side of the fence. It's gonna be curl bash and python, but also, uh, native rest. So we can integrate with other platforms that might be part of an a orchestration engine in your environment, so that when you do build your run books for execution, you have all of these tools and techniques to help you where you are. And I and I love the fact that we don't
actually don't have a auto orchestration platform Because now you can plug in exactly where you are today with your existing technologies in your in your, uh, in your environment, I think the the power that comes for the vest, you know, we can use those natively but the SDKS accelerate your deduction. So the power shell SDK you could be up and running a map of hours,
can't you? I could talk all day about that one. who, uh who here, um, has used the power shell SDK to talk to their arrays to do tasks. 234. Ok, four, python. Anyone in the python universe? Cool. Yeah, in the book. See, I, I do lots of great, you know, I, I do most of my automation with an now we still
customers using, uh uh, bash. And but it's not as productive from a delivery point of view. You use the SDKS. You're gonna reduce your your automation by a long time. Yeah, anything you see in the, uh is implemented on top of the rest API and all the modules that we talked about there interact with that rest API.
So, uh, I'm sure I don't wanna say there's exact like for, like, functionality because I haven't done a complete gap analysis. But the idea is powershell python and all those, uh, will implement all of the same features that you'd see inside the inside the areas. Yeah, Pure is a first company. Everything we do is based on rest. Whether that be the command line interface,
the web, U I or the SDKS. They're all using the same rest using the rest. Uh, for the Oracle team in here. I've got a database package just to show you that we can Actually, this isn't using the SDKS. We can use the rest natively. I'm using the Oracle UTLH TT package.
I develop a P SQL script, and from there I create my database session on the flash array. And then I create the payload to do a protection group snapshot so I can take a snapshot from inside my oracle database without logging on to the flash array using the command line interface or the Web U I or from the operating system. So in the database. And this could be a database package and then
from the database package I can do Exec, there's the package name. There's the URL to the flash array, the token and the protection group. So now I've enabled DB a S to take a snapshot from their database. Maybe before they apply a patch, maybe before they do an R man backup or after an arm man backup. So it's quite powerful when we use the A PAS at
the application database level. And there we said, it's so even though I did it through the rest, we can go to the flash array and we can see the details of there's the snapshot being created. No matter how you do it, it will be visible in the flash array and in the audience one click Go back that one real quick. Uh, one of the things I love about the flash
array and the simplicity behind it is So this snapshots here, right? Who uses a ray based snapshot replication? Anybody all right? A little less than half of y'all to replicate this snapshot somewhere else, whether it be another flash array, cloud block store or even to an object store, you add a target here and you set a replication
schedule here and that's it. You now have AD R strategy, right? Because now your data is available to you somewhere else. And you can get access to that data by cloning that data into a volume and get access to that data in another data centre or cloud. Yeah, we could actually take a snapshot at the same time.
Launch the automa er, the replication. So that's really cool. So you want to protect your backups, do that, take a snapshot and and send it somewhere else. And that's what we're talking about now. Backups. So here is really you know, this is our strategy for for all databases you can see in
the middle there. We've got our man, but we've also got, uh, my QL and Michael sequel backups all going via the protocols that they prefer to the flash places. So any primary storage would love this to be a flash ara. But we know that not every database lives on a flash array, but it doesn't mean that you can't use the flash blade as a backup target.
So any database database servers back up using the native tools NFS pretty much all global database that backed up to NFS. We'd always say offer A you know, follow the 321. It's a It's a really good way of thinking about your backup strategies and data protection. So free Prime plus two backup copies. Is that something that you do? Yeah, that's good.
+22 different media types. So I've got this. I've got my block and I've also got flash blade for file. Just ask me if I run back up. Is that what will you do? +321 You do +321 make if I do. +321, put the plus on the end. And then one So two, we've got two different types and then one keep a version offsite.
So for that, be AD R site or in the cloud. And we can do that all with pure. So you know, it gives that full level of protection, and the plus is immutable. That's the bit for malware protection. So we can take a snapshot here and we got that point in time recovery
from the flash away. We've got our backups going over to the flash blade and we can take snapshots here and we can send those snapshots somewhere else to another flash blade by replication. It could be backing up to S3, and it could be replicating to an as your bucket. So from the flash play, we can replicate through NFS.
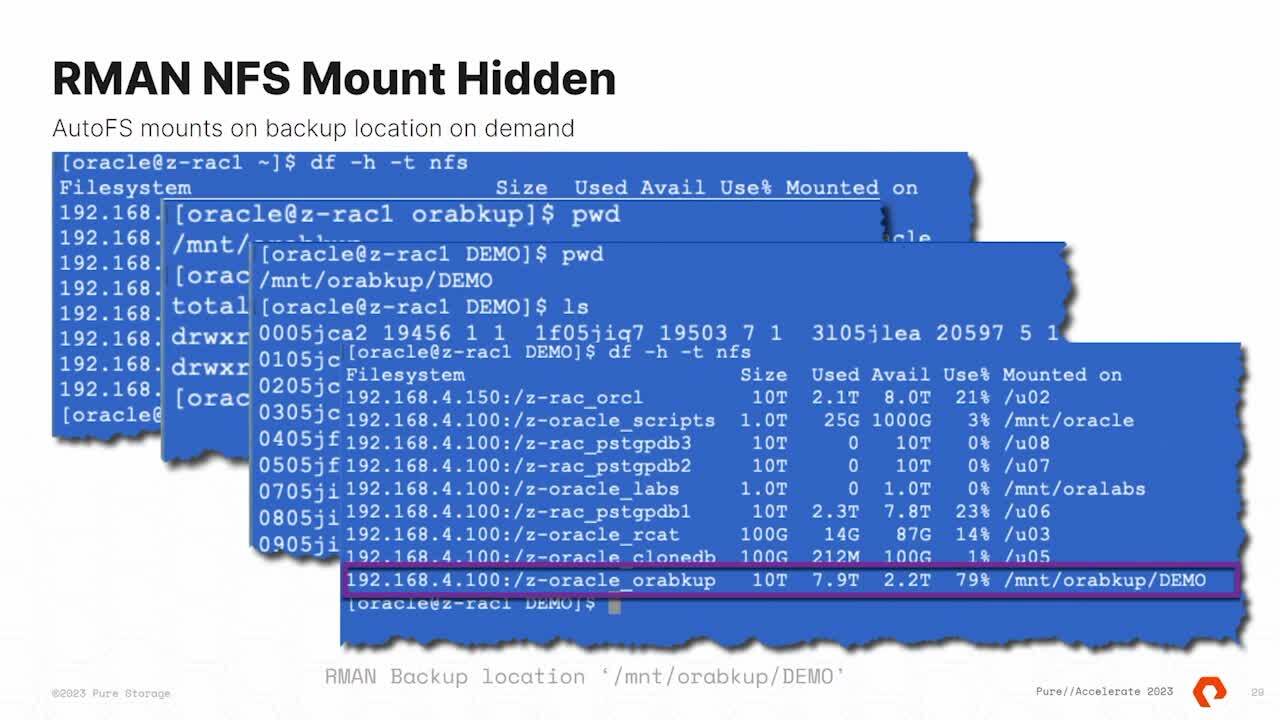
And we can also replicate on, uh, through S3. We talked about making it harder at the beginning. So this is what we could do on the side with NFS. Uh, hide the NFS mount points use auto FS. So we only mount the NFS. Uh, it's always a wonderful thing when you see mobile phones.
I always want to run over here, right? Auto FS makes it harder for you to see your backups. It only mounts the file system when you come to do them. So from an all call backup point of view, I will only mount them for the duration of the backup. So I go to my database server.
I set it up here by default. It's five minutes. I've reduced it to 180 seconds, so a bit a bit shorter. I sell it. What databases I want to mount and where to mount from. So I'm an intruder, and I'm looking for your
backup. So I'm doing my backup hunting. I see here there's a server, and there's a director called Mount Oh, That could be where the backups are. So I'll go into there and, uh, all the backup I look there, there's no backups. No, I haven't done any yet. I'll go on, move somewhere else,
doesn't know any backups. The reason there's none there. Cos auto MOUNTER hasn't kicked in yet. I ceded to where the backup should be. Bang Flash Blade mounts the file system, and those are my backup files. That's pretty cool. As soon as the backup's finished,
that's no longer being accessed that directly, it automatically gets unmounted. Now. If I did AD F minus H, you can see it's mounted the, uh, the all the backup demo directory. This is stuff that's in Linux. It's just a way of using the protection and the features. And the Linux operating system and the flash
play together to give us another level of protection in the same way we can automate the flash array snapshots. Flash Blade has rest interface as well, so there is SDKS, and there is also the ability to use curl in the same languages. So here I've got Python as an example. So I've got a python package which can take a flash based snapshot.
So here in my arm man backup script, I can take a snapshot. One of the great things about when I take a snapshot on the Flash Bay for my backups. It creates a dot snapshot directory, which is quite cool. So here's I got scripts. And actually, this script supports replication, so I can say source one and then a target.
So I take a snapshot and replicate it to someone else, all in one command. So the back of my end of my backup now my backup launch this to protect my backups. So they read only dot snapshot. They're IUT through safe mode and they replicate to a second site. So I've covered all my bases here.
One thing that you could do with before I hand it over to, uh, Anthony. With the dot snapshot, I see customers look at their snapshot directory, and then they always have their arm and catalogue pointed to the like Mount Backup. With all we can register the dot snapshot directory in our our man catalogue.
For that point, it's just a read only file system so Oracle can restore out of that directory. You can validate the dot snapshot directory to make sure that your database integrity is good. Before you do a restore, we should always test the integrity of our backup before we use it. Take a snapshot before you do a restore. Because what you have today may be better than
your snapshot and your backup. So protect what you have. Validate your backup and then restore at that snapshot directory without having to copy it from the dot snapshot to the, uh, the backup location. How would you do that with, uh, Microsoft, Right.
Uh, wait. So you're doing the the snapshot back. How did your back, right? We'll kick it off there, then. Uh, well, the first thing is I'd start with what we were talking about earlier is is a layered backup approach. I'm gonna focus predominantly on native backup today, but I think it's getting to the point
now where data production database systems are getting so large that restores aren't generally, I think are gonna shift away from coming off of native backup and restoring the actual size of data back into the production database. I think building a layered approach that involves snapshots on the array is gonna become core to recovery techniques. Right, Because if you think about it as a DB a What you're doing is you need to get back to
that previous state at a point in time and from, uh, array based integrations, whether it be in database engine or with VSS or things like that, we can get application consistent snapshots within the array, or we've use crash snapshots depending on what your RPO is, and so that layered recovery technique. I'm encouraging customers to go with snapshots
first, but always coupled with native backups, because you're gonna service a different use case with native backups because as a DB a right, I might have to go back and research a data anomaly from seven days ago. Or maybe a business process failed and the books didn't balance for whatever period of a of a business cycle that we're in. And that's that's really what you have to talk about when you're recovering.
Database systems is recovering from the immediate failure, but also data anomalies and things like that over time, right? Do you agree? Yeah. What I would say on the side is we used to lay out our databases for performance. So depending on how long you've been working with, or you might have had a seven dis model
or 15 dis model 22 dis model, that's all gone now. But what we do want to do when you lay your database out on your flash array is to have certain volumes one for your data files and that could be a dis group. Or it could be a file system and then one for your control. And we do so if you want to go back to a point in time,
you could roll the whole thing back. But if you actually want to go to a point in time recovery leave, you don't want to restore your control and you redo on your on your archive blocks. So you just shut the database down, go back to a point in time for the data files, roll those back and then you can roll forward for your log files so we can use snapshots with
traditional database recovery mechanisms to do that point in time recovery. Yeah, so but in the SQL server space, let's look at what some innovations are in the native backup world. So as of SQL Server 22 which came out in November, uh, SQL server now talks S3 for both access to data external data that's stored an object but also for backup and restore. And we,
uh, as pure, had the luxury of working directly with the Microsoft engineering team to do some pretty cool testing around this integration and the idea when we're talking about backups, especially in in large data states. And this is what I talk to customers most about is there's two scenarios that we have to deal with who has that one big giant database. That's kind of a pain that we all have to worry about the multi terabyte one or hundreds of
terabyte one. And that's the big one that we all have to care about. We can get that scalability out of the platform. We'll talk about how to drive currency, uh, in S3 and, uh, SMB for sequel server in a second. But one thing I talk to customers a lot about is getting backups done in a backup window,
right? If your business is a 9 to 5 shop and you execute your backups. Uh, in the evenings, you have to make sure those are getting done in a certain amount of time. And the other way that we could provide provide concurrency in the platform is running multiple instances of backups at the same time. Right?
So we always think about like maybe I need to paralyse this one database backup. But what if I can run 10, 20 or 30 instances backups at the same time? If a network infrastructure can support that, and that's going to shrink your backup window? We did a PSC, uh, with the customer last summer on a flash blade, and they took out their entire stack of J servers that were kind of a shock absorber for
their backups before they replicated the S3 pointed all of that stuff towards a single flash blade, and they reduced their backup window by four X right change, no code, no backup tuning. Just point it at a different device that was able to deal with the concurrency of the backups are executed against it, and so that provided a lot of value to their business because before what they were doing is
they were backup failed that they re execute the backup, and it would bleed into the business day. Right. And what's that gonna do that's gonna make end user sad or, you know, and slow down the business? So those are really the two scenarios that we're seeing, uh, or I'm seeing a lot with when it regards with regards to,
uh, designing enterprise backup strategies for native backups And so big environments are really thriving with this type of topology, the concurrency the platform provides for them. One of the other values that we're seeing, especially in S3, is the idea of landing backups in a single name space. Uh, that customer that I was telling you about had to write code specialised code to find the
right backup across all of those J bod servers to get that back up back if they want. And so the fact now that they can land all their backups in a single name space means they can have simpler code and a simple strategy when it comes to bringing the data back into their production environment. Flash blade specifically allows me to replicate data very easily.
I looked at, uh, array based snapshot replication a second ago, a similar pattern for replicating data in S3 out of target and sending a bucket to that remote location. And so 321, Right, the DB a have one job, right? Get backups off primary storage, and then a second part of that is getting that out of the data centre as fast as possible.
Right? And the platforms like flash blade give you the ability to do that in an extremely simple way. Um, I don't have this slide in this deck. Uh, but this platform, we did some solution, Engineer. Our solutions engineering team did some testing with the S3 object integration into flash blade.
And we were going to back up and restore it nearly a terabyte a minute, right running eight concurrent V MS into a flash blade over S3 at the same time. Um, when we did the initial analysis, I got the data back and it was actually 62 terabytes an hour. Uh, back up at about 61.2 restore and And my manager at the time, I was showing her the data. She's like,
That's a terabyte a minute. I'm like, Oh, that sounds a lot better than 60 terabytes an hour, right? And so that's, uh, the performance he to get out of that. So on your side of the house, Yeah. We all call come back up to S3. You may not be doing it today, uh, but if you know the flash blade,
if you got one, you've got S3. You've got NFS. Uh, the adoption maybe is not as great. And that comes down to licencing. So if you want to back up R man to SV you need or secure backup licence and you have to licence that per R man channel. So if you haven't got those licences and you want to have the freedom to use backups,
you know you're going to have to buy the licence. The reason you have to buy the licence or has been doing backups to S3 for probably nearly 10 years now. And it was designed for AWS. And when they back up to AWS, they say, Well, you need compression and you need encryption. So when you use the OS CB licence, you get encrypted and you get a compressed backups
and the reason being, if you're setting it to the cloud. That's what you want to do, so it doesn't make much sense when you're doing it on premises. Uh, but you have to pay for that licence, so proceed. Precaution. You speak to your account manager if you want to do that. But there has some advantages, performance and also the ability to replicate that into a cloud
bucket. Yeah, we'll look at some performance on that in a second, but there's another feature in 22 that came out. Um, that was It's pretty innovative. It doesn't sound on. On the surface, it doesn't sound that important. But when you talk about large environments with large databases, this becomes very important. So in 2018,
Intel introduced a technology called Quick Technology. It has a PC I card. You pop into a server, and it can runs compression algorithms. Simple as that, right? It's a $800 card, uh, in Q one of this year, Intel took that same technology and put it on core and the Sapphire rapids chips up. OK, so now we have compression on core.
Inside of a processor or a card, SQL Server can take its backer compression algorithm and offload it to this card. OK, it doesn't sound great on the sticker, but what it does is two things. One in our lab, we ran a test, uh, a 24 core system with a non blocking infrastructure to write into a flash blade if I did a back up with compression for a large database.
Uh, the CPU cores are actually the bottleneck in this environment. The backup, pushed with compression, pushed 24 cores to 60% CP utilisation. Right? Driving that back up into a flash blade because it was non blocking architecture. Literally. The CPU was the bottleneck we turned on. This feature ran a backup with offloaded compression.
The CP utilisation was 6% right? And so if you have a large database that's performance sensitive in a 24 7 shop, that's a substantial gain for your business to get that back right? And I don't make fun Sequel servers, $7000 a core Good. That's good, right? And so now you're actually providing value. Would you just say it was cheap?
Is that what you just did? There? Good value. That's so British, not 45 K. So right. And so the idea here is now Those cores aren't just writing data out for you or compressing it and writing it out. They're providing value to their business because now users can use that performance and
not have to worry about it. I think that's a win for the Microsoft side. We haven't got that. Yeah. So, uh, for an R man backup, I would say turn off compression and let the compression happen at the flash blade because you get your backup will be quicker because you hit the CPU issue that you avoid it. So our CP US are bound and we we can't back up quick enough because we're doing the
compression on the database here. And we want the database here to be doing database work, not storage work. But Ron, wait, there's more. So this backup algorithm isn't the native sequel server backup algorithm. Uh, it's a LZGZ something. I forget exactly what it is.
What's that? That's my Yeah, that's my street name. Anyway, the backup algorithm is not the native sequel server backup algorithm called MS Express. It's a different, uh, compression algorithm that yields a 10% smaller backup file, right? So if you have a very large database. Having a 10% smaller backup file is substantial, right?
Because now it's getting done faster. It takes less CPU, and it's 10% smaller. Remember how much I told you the card was in the beginning of the conversation? 800 bucks, right? And so that's pretty good value to a business to be able to leverage that technology. That's pretty cool.
Yeah. So a block post there on that one. Cool. So when you're looking at backing up into flash blade parallelism is the key, right? And so when you start building backup infrastructures and you're working with your DB a S the one of the challenges that we had because the architecture of SMB is when you run a SMB stream,
Uh, from client to server in Windows, it serialises into one TCP stream. Right. So if I have I'm backing up to 10 backup files across SMB. That's still gonna serialise down to one stream and send that across the wire, which is in odds to what flash blade brings to the party with the concurrency. And so one of the ways that we can get around
doing that is by adding additional data VIPs on the flash blade and having a backup statement that looks like this and it gets it's a little more, uh, configuration heavy. Um, so that's why this isn't the first go to that I talked to customers about When it comes to concurrency. Just run more backups at the same time, get your backup window done.
But if you have that one database that does need that high throughput, this is the kind of pattern that you're gonna land on in your system. But S3 fixes that problem because the S3 model paralyses in on both ends so we don't have to do anything special anymore. It'll have independent TCP streams from client to server, because that's how S3 is architected. So in this example here,
you'd get eight concurrent TCP streams from client to server with compression. Uh, one of the nerd knobs that you get to tune to actually add more throughput is what's called max transfer size. So again, this is about driving throughput and concurrency at the same time. And so here you can see I've adjusted MTs or max transfer size to 20 megabytes. It's a very big MTs right.
If you're doing all man, uh, and you've got multiple nicks in your server Look at using direct NFS. It will give you high availability out of the box. It will give you low balancing. And also, it takes away some of the kernel overhead of NFS so you'll get a performance gain there. So that's the way we get paralysed from the
side. Thank you. It's, uh, from my testing what I've seen and it obviously it depends on the data set. Uh, NFS has got, uh, some efficiencies over S3. Still from an old man backup. Yeah, and you're gonna see that, um, in most block based protocols with NFS and SMB will generally eke out S3 a little bit in raw, single stream performance.
Uh, because when you talk to S3, you're talking literally to an API server. So it's a higher level construct right than a than a block to block file operation. Uh, the way that you overcome that, though, is by adding concurrency with threats, right. And so then you'll you'll be able to achieve the throughput that you want by just adding additional threats to the party versus the
single stream throughput but you'll quickly find that you become bottlenecked on your your network interface. Yeah, so the flash blade is very rarely the the problem here. It's always the database. It's usually it's usually a mis configured top of rack switch that brings the entire cluster
down. Oh, wait, that's never happened. The three version, Yeah. Oh, yeah. And I've already kind of walked through all this, um, an artefact of S3 and also azure blob as well. Uh, is a maximum object size, Uh, and I'm assuming you have this a similar constraint on yes.
So the max object size, uh, for S3 is 100 gigabytes. And so one of the the one of the reasons why MTs becomes important, uh, and compression is because it allows you to get more data into an individual object. And so what I'm saying here is that the individual object meaning of individual backup file so that first one there TCP H full one back, right.
The maximum size is about 100 gigabytes, but I can in a backup set, I can have 64 of those, right? But that doesn't mean I can only back up 64 times 100 gigabytes of data, but with compressions. That's the maximum backup set size, not the source data set size or compressed target Backup set is 12 terabytes. So in SQL Server,
you just see about three or 4 to 1 to compression. And so that's again an artefact of the object size for S3 and also azure blob. So if you didn't you haven't seen that constraint on yourself. I would see 100 gig files. So maybe there what we do on the Oracle side, we would look at our database. If you've got a large database,
you know, 10 terabytes, 100 terabytes, you're probably using big files. So you want to get big files. You want to break them up into small, manageable pieces, paralyse them up so you'll use your section size. So you probably end up with small files. Cool. Let's go back to you.
I love this quote, but it's on a t-shirt showed as backup. The condition of any backup is unknown to whose store is taken. And this comes down to, as you know, data professionals as people that are responsible for your database. Don't don't trust that it works.
Prove that it works. Repeat it. Actually, if you're actually using your backups for development activities, you're testing the integrity of your backups daily. Uh, I've seen many organisations that the backups overrun, and the first thing that the ops team do is kill the back up in the morning.
That's bad news. So you know, you you want to test that. It's it's works. The process works, but also that it's completing every day. So change that unknown to a known state. Yeah, my consultant is I would, uh, talk to customers.
And I say nobody cares about backup. Right? What they care about is three stores, right? So this really comes back to the business side of it, you know? Is your backup good enough? Is your backup window under pressure?
What's your service level? Agreement? How fast do you have to restore? How? When was the last time you did it? Have you ever done it? Is it documented? Is there any system in dependencies?
You know, if you got HR system and a AC RM system and an ER P system, can you restore one in isolation? Or do you have to do them all as a set? What you don't want to do is change your accounts payable system. And then you leave your your purchasing system in one state. And so it looks like you're sending purchase order out to suppliers you haven't built yet.
So you've got to make sure they're all aligned. You know of the the way of working what I like the one that's the yellow one. Get someone else to test your process. If you test your own run book, you will step over operation because you know the next thing. So OK, get someone that's not done it before. That's not familiar with that platform.
So they've got clean eyes, because when you have to do it surreal, you don't want to be sweating on it. You want to have it easy. You wanna have it documented and, uh, the confidence that anyone can do that, because it may be not you in that date for that. Yeah, some friends of mine in the sequel server community.
What they say is, uh, your run books should be written by the most senior people in your team and tested by the most junior people on your team, right, And that goes to the, uh, pilot. We're all data pilots. I. I love that. You know, a pilot trains.
They have training before they're allowed in the sky. But then they have to keep learning. They go into simulates. How many of us have got a simulator that test our recovery? How many of us have got a cockpit companion that says in the event of a disaster? This is what you do.
If you're that pilot and there's a problem in the sky, you can speak to the tower. You can speak to the airline, you can speak to the manufacturer and we've got all of that we can speak to pure. We can speak to Microsoft we can speak to you can call, you can call. You can call me if it's the right time of day.
But, you know, if you're on the ground in our data centre and it's three o'clock in the morning, you want that cockpit handbook. You want to have a flick through the page and know that it's it's up to date, it's maintained, and it's gonna get you out of jail document, simulate it and practise, you know, think of all the scenarios and Have you played those out? Do you know IIII?
I guess, you know, rolling forward in the real world. Sometimes the technical solution is easy. Do you know who you'd have to call to notify to do a production resto. So sometimes it's a human element. Who's the Who's the internal approval loop? Who's gonna say, Roll back the payroll system? So last night,
Just because you can doesn't mean you can. From the technology side, we may have it all documented. Have we actually documented who owns that system? And that's the end for time for questions and we've got.
This session covers the benefits of FlashArray™ snapshots and FlashBlade for high-performance, native database backups. We'll discuss key features and best practices for implementation and management. We'll also showcase real-world examples of successful data protection implementation. You'll learn FlashArray snapshot fundamentals and how to design a snapshot replication architecture, as well as more about performance tuning backups and how to protect databases with ActiveCluster™ and ActiveDR™.

Test Drive FlashArray
Experience how Everpure dramatically simplifies block and file in a self service environment.
We Also Recommend...
Personalize for Me