Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
37:59 Webinar
FlashStack Converged Infrastructure for Modern Workloads
FlashStack Converged Infrastructure for Modern Workloads (Sponsored by Cisco)
This webinar first aired on June 14, 2023
Click to View Transcript
You know, it's always interesting when you get a presentation slot at one o'clock at a conference like this because everyone is eating lunch, right? And you sit here and you're about to enter a food coma, right? I'm almost in the same boat with you guys. So I appreciate it. Uh Being here today if the person sitting next
to you starts to snore, give a little nudge, you know, just trying to wake him up a little bit. So for those of you who haven't met yet, my name is John Mable. I lead the project management in the Cisco's cloud and Compute business unit. And I'm really excited my travel schedule finally this year,
let me attend because Flash Jack has been a core element to the success of Cisco, particularly when you're driving mission critical workloads. And it's the area that my team really focuses a lot on. So I appreciate being here today and I'm really looking forward to this presentation because we've got some exciting new announcements to make around Flash Jack we want to talk about
and give you guys some of an update. Um So that's why I'm here today. And so you know, why are you here today? Well, you might be here today because you thought, well, I've heard of Flash Jack, but I'm not really sure what it is.
What's it composed of? How do you manage a flash ta system? Why should I trust my mission critical workloads of flash tack, probably most critical for some of you. Is, has anyone done this before? Right. Have the customers out there that have been
there, done that with flashback have implemented it had some success. OK. So we'll talk about some of that today. Although I know for some of you because we're in the middle of a conference here in Las Vegas. It could simply be, well, you know, it was kind of a filler session, right? I needed something between now and the sessions
later today. And so I thought, well flash jack, I'll, I'll come in here and we all learn about something that might pick up down the road. It's kind of like one of those psychology courses you had in your freshman year at college, right where you didn't really want to take it. But yeah, we all learn something and it turns out you do that you actually use down the road,
right? So hopefully you'll fall in that same boat. So to kind of get started, you know, CISCO has been really deeply involved in the data center since really about 2009 when we brought the Unified Computing system to market and I joined Cisco in 2010. So I've been 13 years as of tomorrow into this journey. As I said, we focus my team especially a lot on
mission critical applications in Oracle Microsoft VDI with Citrix and vmware horizon or key application workloads. And with those workloads, whenever we test them on systems like flash tack, we always test them. Now with the, with the public cloud Azure, Google Aws and we do things like we'll force more workload on the system that can handle.
So it bursts out to a cloud to make sure it does that appropriately. Obviously backing up and restoring, do some other work with the cloud because hybrid cloud is the world we live in today. Right? Along the way, we also try to incorporate maybe some big data solutions Cloudera. We may look at some data protection. And historically,
we did a lot of work with Vim and COMT more recently with rubric. And then for those of us who have some A I or graphical applications that we need to run. Obviously, we do a lot with NVIDIA, bring their GPS and soon Intel GPS will be brought into the fold of our compute offerings and all that ties right into and supports flash ta. So what is flash tack? Well, flash stack in a nutshell is a converged
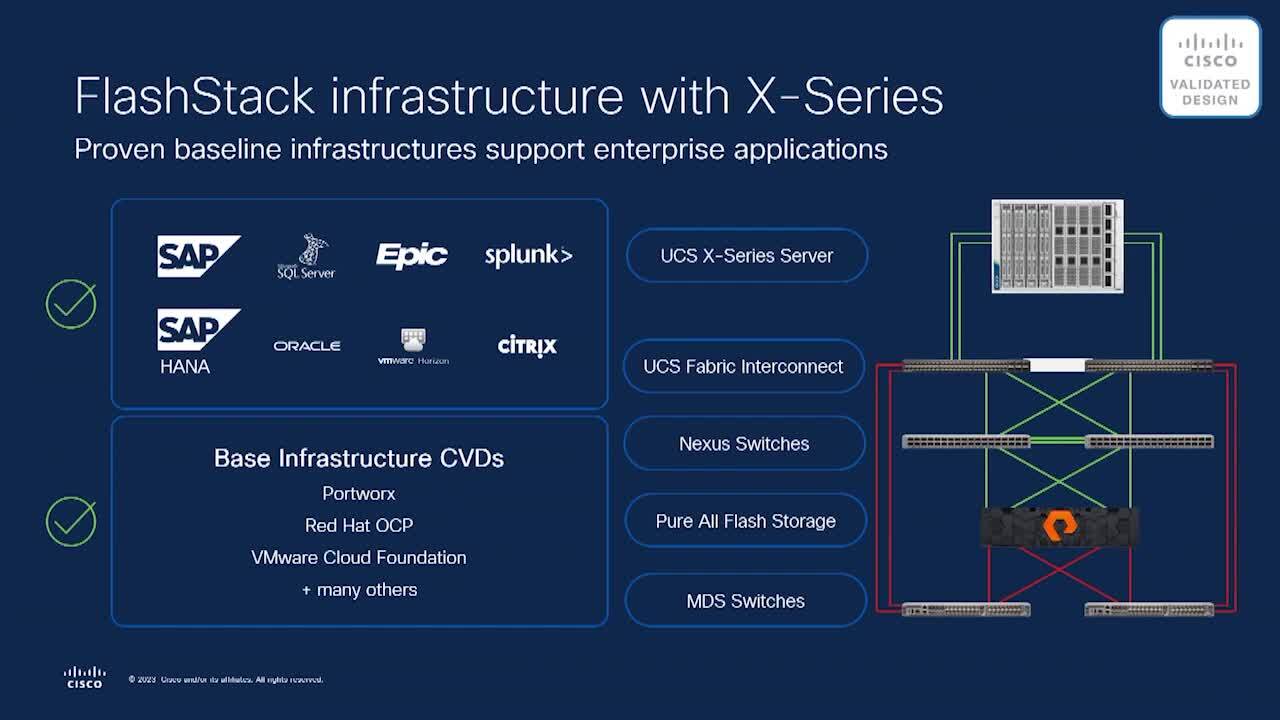
infrastructure that is sold in a meat in the channel model. So you go to our channel partners and talk to them about flash stack, they pose a system together to you that is based on Cisco's servers and the servers themselves we're going to talk about today are X series. So it's highly dense modular policy driven compute that Cisco has been known for,
for the last 13 years. We also tie in Cisco fabric and I won't even ask for a show of hands on how many of you are running Nexus technology or data centers. It's probably 75 80% of you. And then of course, we tie in pure arrays that you've heard a lot about the conference today. How efficient they are. How if you bought an array back,
you know, 67 years ago, it take up 12, you, it only takes up three u of space in your system rack in your data center. So we've worked with pure along the way to manage these different system elements into a flash stack design. Now, design itself is actually pretty simple in a nutshell and it's designed in such a way that as your needs grow and change the system grows and change with you.
So it's no longer the case that you invest in a system of architecture. But if your needs change, if you grow faster than you thought you got to rip and replace, right? That's what you did to you guys 10 years ago, right? These days, you can invest in architecture and flash deck and the elements can change So in the initial installation,
say it's for oracle, you'd have three servers, nexus switch and a pure storage array. Maybe your data grows faster than you anticipated add in another array, right? The number of server stay same, the networking hasn't changed. Perhaps down the road you say, OK, now I take flash stack, it's storing oracle, but now I'm going to take VDI repatriate it
from the cloud, bring it back into my data center. But now to do so, I need some additional servers and I need a couple of those servers to have GPS in it because I got some graphical applications that I want to make sure those GPS are doing the rendering of and not the intel cps that are in the servers themselves. And so each of the elements of flash stack can change as your needs grow and change into the
future. Now, we've been involved working with pure for really about 78 years in flash for about seven of those years and it really has been the top growth engine for converged infrastructures for Cisco. You know, we've got thousands of customers running on today. The engineering itself is done within Cisco labs by Cisco engineers,
peer engineers. And often with the engineering teams of the application vendor, we work with either the engineers from Oracle Microsoft and so forth. These best practices we capture into Cisco validated designs and then hand those into the marketplace for you to review consider and implement into your data center. Now, who's doing it? Maybe the better question is who's not doing it
right? As the chart says, 4100 customers, the last time we looked is probably closer to 4500 these days. And we see that there are sales in 47 different countries around the world. So clearly mission critical workloads from large customers, small customers around the world are being used on flash stack.
National governments are using key applications on flash jack. They won't tell us what they're running because they have to shoot us right for security reasons. But needless to say if you've got a critical workload, flashback is a system that you should be considering today. Now X series, we have one on display. It's a three quarter scale mockup that's in the
booth here at the conference X series we brought to market just about two years ago. It's the latest um design of the unified computing system that we originally brought to market in 2009 time frame. Think of X series as a different form fact than what you've seen from us in the past. Think of it as you're taking normal rack optimized servers in which you'd have a
motherboard with processors and memory, some disk drives into it. But we're gonna take that we're going to turn outside and slide it into the chassis and we can put eight of those into a fully loaded chassis itself Now the back of it doesn't have a back playing like you might have seen in the past how we connect is through the X fabric technology at the bottom of the chassis that allows for connectivity between the different
blades within the chassis itself and for connectivity to the outside world. Now, we have different types of compute nodes. We've got two socket and four socket intel compute nodes last week at the Cisco live conference here in Las Vegas. We announced our plans with a MD to come up with a two socket ad blade. So you'll be able to enjoy that in the 2024 calendar year time frame.
We also have a GPU node. Now, the GP node is there because we know customers like yourselves have GPS or a range of GPS that you need to support. And so the NVIDIA product line think of a 16 S A 40 S A 100 gps T four GPS, they can be housed into a single compute node slid into the X series chassis, either an initial installation or at some point in the future to take on those additional
workloads that may come into your data center into the future. So this is how we're able to design a chassis that can handle needs into the future. We've got some designs and some future compute nodes 234 years down the road that we will introduce at those times, the whole chassis itself then is powered by, you got six power supplies and four different fans to provide adequate air flow through the
chassis. Now, just a quick closer look at the two socket compute node two Intel uh fourth generation Intel Xon processors are available today. And I would highly recommend you look at the fourth gen as opposed to third gen, not just from a performance standpoint. Fourth G also includes some integrated accelerators into the processors itself.
One example of the benefit is what they call quick access technology. In the labs, we have tested SQL server 2022. And if you had the prior generation Intel processors, we show a backup time of X and amount. But with the new fourth generation, we can cut the backup and restore time by 2.5 times. OK. So that's just one of the benefits that the
latest generation of Intel in the X series chassis can provide to database based administrators like yourselves. The system itself obviously can put 12 terabytes of memory into a single compute node. We have six NBME drives, not spinning drives IE all at the conference ND drives 180 terabytes per blade. Now for a flash tax system, most people will
have, you know, a couple of drives for operating system, but the rest of the drives are empty and they rely on the storage being in the pure array obviously, but they're there in case you need it and we do have some customers that will utilize some of the drives in the compute node for smaller data database and small application support. OK. And again, eight of those can go into an X
series chassis. Now, when we designed X series, we had already seen the trend in the marketplace around sustainability. And when we designed X series, we think we've got some key advantages over rack optimized servers also by the skill design and how we actually source the product and bring it to market. So one example of advantage over rack optimized
servers is that with inners site, which is our systems management tool that we're gonna talk more about here in a minute, it has the ability to monitor the heat that the system is actually is actually generating in the fans. So that those four fans you saw in the back of the chassis, everyone thinks they all spin at the same speed. Not necessarily, it can actually control the speed of each fan to make sure the air flow is
adequate for what you need. If you don't have to power up the fan as much, you don't drawing as much electricity. Hence, we're saving you power in your data center. Just one of the examples of the design we've done here. Secondly, if you look at some of the efficient components we have here, some of the plastic components, the resin that actually makes those
components are actually derived from recycled older servers that we've brought back into Cisco from your data centers have broken them down and recycled those elements to put them now into the X SERIES chassis. And our commitment to uh uh uh uh consumer rights, uh human rights, excuse me, for human rights is resident in how we design the system because we only
source from countries and from manufacturers that adhere to certain standards that we have mandated for those factories that build components for our systems now. And so it is a nod to Cisco's support of human rights all across the world. Now. Seal is a corporation that announced three weeks ago. They're winners for um looking at
sustainability and they chose X Series ahead of all of all, all the other competition in terms of its ability to maintain sustainability, yet performance, ease of use and so forth. And so it says in their award that if one of the key elements of the solution you're looking at is is here in sustainability, you got to look at X series, it absolutely meets their standards and exceeds it.
So this is the award we got three weeks ago and the link is there. As you get the charts after the conference, you can click on it, take a look and see exactly what they said in their report. Now, I know some of you are thinking, well, that's great for X series. But what about flash stack as a whole? Well, our friends at ESG have written a similar
report in which they looked at flash stack, including all the major elements and said, OK, how does this compare against the legacy hardware platforms? How does it compare against other converged infrastructures in the market? And they've got some very interesting data. One of the data points I saw was that if you compared flash stack to systems that you installed four years ago,
you could save 85% of the power in the report over the older system, right? And so they've done a lot of the analysis of work for you. I encourage you to take a look at that report, download it, view it, pass it around to you know, your friends where you work at and have them take a look at as well. I think you'll find a lot of sustainability
efforts that we highlight are in that report. So how is flashback managed? Well, it's really managed through Cisco inners site, which is Cisco's cloud based systems management utility. Now, if you're familiar with Cisco in the past, we have s manager which we still sell in the marketplace. It's the tool we first brought out in 2009 has
a front end written with Microsoft technology by the way. And so that tool is still in place but looking into the future and why we brought X series to the market, we want to take that tool that was stayed resident within the data center and put it up into the public cloud. And so I always like to say the inner site is the tool that gives you the ability to have
world domination. OK? Because a lot of the elements of U CS manager such as service profiles are now in Cisco inters site. So you think about it, you as a DB A say, OK, I've got data servers around the world. I know exactly how I want those servers tab to run oracle or SQL server. So I will main main,
I will take that set up. I'll save it as a server profile. Make sure it's perfect. And then I'll send it up to inters site at that point. You can copy it into any server, any, any data center that you have that's running inters site and ensure that every server is set up. Absolutely the same.
It eliminates one of the great problems that an oracle DB A s have faced for years where you get two different servers that are set up differently and that can lead to some performance issues down the road and they're really hard to root cause this service profile capability eliminates from that ever being a problem for you. OK? Yes, it does help status monitoring information
like other things, but it also CISCO can track some of the data of insight. And if we start seeing errors and certain issues, we can actually root cause what those errors might be write a patch, post it to insight. Your company can download from that point and you can download that patch for inners site to all the servers. So you can actually sidestep and avoid
potential problems and challenges before they become a problem in your data center. One of the other things I love about insight is yes, there's an app for that, right? So you actually through your iphone or Android can pull up inners site, you can be alerted if there's any issues or problems with flash stack and be able to take policy actions as you'd like to,
to be able to handle those types of current events and so forth. So you're at a conference, you're at a ball game, you're at the beach, drinking beer and so forth. You could have inters site on your phone and be able to manage and monitor your systems. Now I mentioned, I mentioned flash stack in my last comment and that's because we have open
program ability with insight and we have open API S such that you can take tools such as answerable Terraform service down and write plugins intoners site. And we've got many of them. The two I'll highlight today, of course, are pure with flash stack and obviously VMWARE V center. And so through this, we're able to be able to manage, monitor the peer or raises as part of
our flashback system, health task monitoring, information, performance information and so forth So it does give you that single pane of glass to be able to see all the elements of a flash tag system and let you take actions appropriately as you need to. OK? And you can expand the number of, of plugins that you need to as your needs grow and change in the future with flash stack.
Now, a lot of these best practices we write in a document called a Siskel Valid design CV D. That's what is kind of known for, right? These are very exhaustive documents, think 304 100 pages, great bedtime reading. By the way, if you haven't saw me, you can read him and fall asleep.
But these are documents that are written by Cisco engineers documenting the testing they've done in Cisco labs on a targeted system like flash stack. OK. So all of the elements of the configuration are there all the way down to the individual operating system firmer levels, any patches that are updated, they're all included there.
We also document a level balanced level system performance that you can achieve with the proper setups. The goal of these Cisco validated designs are such that if we have all the best practices in place that really gives you soup to is how you install the system. We should go to compress the installation time for you from the time that you slice the boxes open when they arrive in your data and the time
that it's fully up and running, running the workload you have on it, you can take that time frame. It would take weeks, months in the past to determine those best practices and compress that down the days. That's what helps to separate CV DS. Another element, separate CV DS from competition is the supportability aspect.
So let's say you buy a flash deck, you get the CV D and download it from Cisco, you're setting up your data center. And for some reason, you can't seem to get the right level of performance that we documented in Cisco val design. What do you do call Cisco Ta or Cisco support team? Even if you don't have a support contract,
by the way, you tell them I'm loading flash stack. I've got the CV D, I'm following it. I'm not getting the performance. We will work with your team to find out what the problem is. We'll start with telephone webex, that kind of thing. And if we absolutely need to and if it's OK with your Cisco or your COVID policies,
we'll take one of our support engineers and put them in your data center and work with your team and get that system to low performance that we've documented the Cisco validity designs. That's what helps separate CV DS from IBM red books and other white papers that other competition we put out, we stand behind it. We'll put a body on site if we need to.
Now, there are two really different types of CVD that we develop. One I like to call is an infrastructure CVD, right. We take a standard setup for flash stack, see all the elements listed there and we're going to load on maybe red hat OCP for containers and maybe port tricks. And we're just going to load that up. We'll do some baseline test fio which is an
industry standard utility to ramp up some workload and just test to make sure that those baseline elements of our flash solution are running. Well, we'll introduce some break, fix into the design, make sure the system responds the way it's supposed to and have that infrastructure defined in the CV D and available to you. Then my team takes over and we take that same CV D and we add on a workload.
As I mentioned, it could be oracle, it could be epic in the medical space, it could be sap and now we add on the additional element and we say, OK, here's the baseline CV D and the best practices. Now, here's the best practice of adding on that database. Here's how you would set it up. Here's all the different patches from that OS
vendor or from the database vendor you would load and so forth. So you've got a complete soup to notes of how to implement these different mission critical applications onto a flash tag solution. Now, a couple of these new designs that we've just brought out a highlight for you. The first one here is Red Hat OCP with portraits.
So what we wanted to do was to document an infrastructure that showed OK, we want to run containers, Red Hat's latest technology and we did that also with portrait. So we can say, OK, people are going to have a data center cloud backup. Let's use the pure capabilities here to make sure that that copies of the data are absolutely identical and they can easily move between the two between the cloud and the on
premise data center. That's good from an infrastructure standpoint, this is published. You could look at today what you're going to see in about two months is a new CV D where we took SQL server 2022. And we said, OK, what's the biggest data warehouse you can put into a single container right now when you want to implement that or not up to you.
But we're going to document that. We're also documenting putting hundreds of smaller SQL server databases, each one running in their own container on redhead OCP again. So it gives you a menu, it gives you the ability if you want to set that up in your environment, you can all the best practices are defined for you with oracle, with Microsoft's latest technology that just released on January
1st of this year. And I know some of you may be a VM Ware shop. So VM Ware cloud foundation and if you've got your phone, you can hit the scan and be able to take it straight to the CV D V Cloud foundation. Gives you the latest and grace technology from vmware. We set up the infrastructure as I mentioned previously and we loaded up,
I think it was an oracle workload on this environment showed our balanced level performance I mentioned beforehand. But then we introduced a new element. We said maybe customers needs to have grown and change over time. Maybe we like to introduce a VC. So we took four C series which are rack optimized servers.
V SAN radio nodes added it to a flash tack configuration, had those servers connect directly into the fourth GEN fabric interconnects. And now you can set up the V SAN for flash stack, have it run as a separate workload. All the best practices of how you would do that are defined for you here. OK. So a point is that's the flexibility of the
design, you implement flash tack once and you don't have to rip and replace it just grows and changes as your needs grow and change into the future. Now, I'm getting a little bit closer to where I live and breathe in VD I space. The latest CV D that we published here was horizon eight on Vsphere seven. We have a new one coming out next month on Vsphere eight.
By the way. And what we wanted to do is to say OK. Look, customers are really in this um mindset where they're looking to repatriate VD I from the cloud, right? When COVID hit, you all had to say, OK, I gotta set up all my employees in remote environment. And so I got up in the cloud, it was really the only alternative you had,
right? Because it gave you consistent interface, it was immediately accessible. Uh Azure could give you a snapshot of where your costs are gonna be. And so boom, you had to go set it up out there because you had to set up those environments by like Thursday of next week, right? There was no time to do any kind of analysis,
right? So you had to put up there now a couple of years down the road, some of you are starting to get some of those bills going. It's a little bit higher than I anticipated, right? And the security profiles don't really match what we want to do in our own data center. And if one of the cloud runners makes a mistake, they say,
oh, we're really sorry about that, but that's all they get is is you're sorry, they're sorry, right. There's no um ramifications uh from their standpoint. And so a lot of people are looking at taking those VD workloads and bring it back into the data center. And what they told us is that they don't want to put say 5000 or 10,000 desktops on a single
architecture. They want to keep about 2500. It seems to be that sweet spot. So we took flash and we said, OK, let's take a VD I broker horizons eight, we're going to scale up to 2500 users and we're going to use the login V SI which is an industry standard tool for VD I and ramp up the users and we're going to choose the profile of
a knowledge worker now a knowledge worker. What's that? It's like you and me, right, professional workers, we have a bunch of applications that we access. We've got a couple of database we access, but we're not doing any complicated highly graphical applications that require GP U knowledge worker is the most popular user profile for VD I by the way.
And so we're going to scale up to 2500 users. We're gonna document the best practices, we did that. And then we also said, OK, we're going to add on some graphical applications now and put the GP U note into the XX series chassis with the NVIDIA A 16, I think a 40 GP US. And we're going to run some graphical workloads and show the performance at that standpoint. OK. So that work is all done.
A couple of things that came out of this particular CV D was we did some comparisons of the latest X series with M six and M seven compute nodes and said, OK, how does that compare to what we sold you 34 years ago. So if you have Cisco's M four technology and you want to go to M seven, it's about a 4 to 1 compression, right? From the amount of servers it took in the past
to what it takes. Now, if it's, you're running the M five base servers, it's a 3 to 1 compression, right? And of course, your mileage can vary right Based on how you set up your workload and so forth. That's in general what we saw in our data center. So this CV D is out for you to take a look at.
Um now something else that we do in our CV DS and I'm illustrating with the VD I one I just spoke of, but throughout oracle and sequel server and other CV DS, we do, we do a lot of break fix at the system, right? Because flashback was designed for not just a, not a single point of failure, it should withstand many different failures simultaneously and yet keep on running.
Right. It's like the whole time watch, right? Takes a licking and keeps on ticking. So what we did, we said, OK, we're going in our lab for this particular CV D. We've got the system set up and we said, OK, let's start injecting some faults. Yeah, sure. This drive fails, said fortunate.
It happens once in a great while, but it does in our site detects the failures happen and alerts you and through policies you set up, it automatically moves the data over to the other healthy drives. Puts a support call out to Cisco support. We can come out and fix the drive for you. Ok. That's nice. How about whole blade fails?
And what we can do. A lot of customers do when they buy X series is they'll buy an extra spare blade and have it in the chassis and extra compute node. Now, if one of the healthier ones were to fail and you can set up policy and say that's a mission critical application I need for that spare one now to take over the workload of the one that failed. So it takes the service profile for say or
database copies it from inters site down, makes that one blade have the personality set up to run or rack and then it can be taken and inserted into the cluster. So again, you're up and running, you're alerted that the issues happen. The system has automatically done all this stuff for you and then you can see what's happened, put a service call in for that one failed node,
but all your transactions process, all of the work gets done. Your executives are happy they stay off your back, right? That's the benefit. Now, let's just say we have some cable outage. Let's see, you know, one of the connections between maybe the X series chassis and the fabric
interconnect or between the fabric interconnect and the top of switch has gone out. I go to read three of them here for you. No problem. Right? Because we designed the system so that even a single cable can handle all the data needs of the system. You got two. So in case one goes down, you're still good.
Let's say a, a fabric interconnect were to go out. OK? You call Cisco, we try to replace a couple of parts and get up and running, but that doesn't work. We pull out the entire fabric interconnect. Bring another one in a standard best practice we have here is when you have a pair of switches or a pair of fabric interconnects,
each want you to maintain a copy of how the other one is set up, right? So the failed one goes out, bring a new one in copy over the set up from the healthy one and that fabric interconnect can be brought very quickly and get your system fully back up and running to the maximum capacity. Same thing with Nexus switches. OK?
So here we've illustrated seven different failures happening simultaneously to a flashback system and yet you continue to be up and running. Ask the competition how many failures their system can withstand? And can they prove it in a Cisco validated design? Will they stand behind and have an engineer go on site and work with your team?
If God forbid, you had seven failures at one time. Ok. So that's the type of resiliency we put into our designs. Now a bit of a commercial to our friends at Pure. They talked about the keynote this morning, how part of their, their cloud um designed for the future is being able to pay as you
go, right? No longer having to write the big checks. Well, flash stack as a service really is a service that they're talking about. And so this is all about no longer having to write, go to finance and write a big check and say, hey, I need half a million dollars to buy a flash tax system, which is always hard to do with talking to your friends at finance,
right? It's much easier for them to understand that. Hey, I want to get a flash tax system. I won't be able to purchase the system. I'm gonna pay for it based on our needs, right? How many CP us we use, how much memory we use, how much dispace we use. And if our needs grow,
we'll pay more. But if we use less, we'll pay less. It's a model that finance teams can understand. Think about. Some companies have some seasonality in their business, retail companies, right? They kind of cruise along through the year and then also November, December, right? Christmas shopping season takes over.
We're all buying all kinds of presents for our family and friends. So the course the compute needs grow as a result, right? But then after you get to the first of the year, then down, you go back into a normal state. So by telling the finance team that hey, you're going to pay based on usage,
but it's going to match with the revenue coming into the business. That's a model that finance can understand, right, that match in cost to revenue all is good. And so it's the wave of the future. I think some of you, I see lots of head bobbing in the crowd. So you understand this. And so this is the pure solution to how you do
pay as you go. And so it's another way to get flashback into your business, different finance model than what you may have done in the past. Security. Security is also very important to everyone here in Cisco. We literally on this menu of products, I'm showing we could do a two hour breakout session
on every one of these products and we still wouldn't cover all of its capabilities, right? So I can't do it just as in the presentation I have today. But suffice to say we have a lot of products that can help you monitor the security of your data both at the server level throughout the network. And then as you go out into the cloud and what
you do within the cloud itself, let me give you an example of one of these tools, there's a product called Cisco tetration I think it's going through a brain change, branding change, but still called tetration. As of last night, taxation is a tool that you can load onto flash stack and it ties directly to your databases and what it does is it monitors the database and it monitors if someone tries to load an
unauthorized patch to the database. If it detects it, you get notified, it takes the patch itself that someone tried to load and quarantines it so it can't be implemented. You then as the administrator with global world domination at your fingertips can decide if it's something you want to implement or not and simply delete it,
right? And so it gives you the power to be able to set those policies and implement those policies in your data center. T is a way to help you to make sure that your database is stays secure. Just an example of one of the many tools here that Cisco can bring to market to help you in the in the guards of security. So we sit down with you,
tell us what your security needs are. We'll match up the products we view them with you and we can add these to your flash deck solution to make sure your security needs are met but exceeded. Who's using flash deck. As I said, who's not? Um we saw this morning that the formula one racing team from uh uh Mercedes apparently is
using flash stack, right? That's how you get those signed hats with the Hamilton's name on it in the interest of full disclosure. I have to admit Cisco does not support Mercedes. We are actually sponsor of the mclaren racing team. So those orange cars are gonna be running around Las Vegas. We want them to win the race.
Not Mercedes. Ok. Obviously, wide range of, of vertical markets are using flash jack, you know, state of Mississippi Department of Revenue. If you're from Mississippi, it's all going through a flashback system. No service now, Nielsen TV. Ratings. Domino's Pizza,
which we all had in college, right? If you're a baseball fan, the San Diego Padres and the San Francisco Giants use flash stack to, to be able to manage all of the financial data of those baseball teams, right? It's all the beer sales, all the ticket sales, all the checks you have to write out to those baseball players that are making 50 60 $70
million a year. So that all goes through a flash tag system. The point is no matter how varied your needs are. Flash tack can be the platform that can take it and drive it and get you the low performance and security that you need into your future. So what about support?
You know, we're dealing with Cisco, we're dealing with pure, we're dealing with any wide range of companies that are applications are running on it. Well, there is a third party clearing house for support calls called TS A net. Some of you may have heard of it. Ts A net is a way to be able to move support calls quickly and easily between different
companies. So the way the process will work, you have a problem in your flash check system. Call Cisco, right? We'll go through it and make sure it's not a Cisco authored product, right? It's not one of our hardware drives, it's not Cisco inter anything like that. We determine it's not a Cisco problem.
We place the call into the TS A net. In this case, a flashback, we'll flag it for pure. So the wheel spins pure pulls out those tickets that are flagged for peer. They take a look at it. They've got the record of what we put into the record. They look at it and say, OK, they look and say,
OK, it's a pure problem. We go ahead and fix it if it's not a pure problem, but they know the application say as oracle, they can put it back in the TS A net. It's flagged as oracle and then oracle will pick up the call and they will read the notes and be able to exercise the call from there. Now, 95% of support issues from what I've seen in the last 5 to 7 years, it's pretty obvious who the support organization is.
Right. Hard Drive has failed at Cisco. If it's a storage array that's got an issue, it's pure and so forth, right? It's almost 5% corner cases where it's really undetermined where ts a net and the ability to track these support calls really helps out. Now you may be thinking, ok, John, that's great. But I want one throat to choke.
I want one person to call. That's gonna be the one that's gonna do the research and respond back to me what's happening with my issue. Cisco solution support can do that for you extra layer of support that we provide where you call us that whole process. I spoke of these different companies, we monitor that and we can call you back each day and say,
OK, yeah, the call is being looked at by this organization. Here's the response now it's going to this next organization and they can give you constantly updated on what's happening with your support calls no matter where the support call may go, right? So we can take that management pain away from you if you'd like. One other aspect is that this is a meeting in
the channel model with our channel partners. They have great installation services and great support services for flash stack, right? They've been there and done that so many times with the hundreds of customers that they've installed at in major countries like the US, obviously that they have a great support organization in place, they can give you support to the system. And then of course,
pure and CISCO are the backstop, right, the safety net if you will. So if it really gets beyond the support capabilities of the local channel partner, they can always come back to us and we'll help them. Ok. So you're always in good hands from a support standpoint. Now, IDC recently looked at converged infrastructures and they picked flash stack ha
ha big surprise as one of their top choices. And you see the couple of quotes I pulled out of the report and it says, look if you're looking for a converged infrastructure that has higher performance where they've reduced a lot of the complexity for you. There is a nod to sustainability and that helps to make, make your meet your sustainability challenges and so forth and it's really designed for the
future so they can incorporate newer technologies as they may arrive in the future. You have to look at flash stack and that's what the report for IDC basically says. Again, if you have an I DC subscription, go out and take a look at it, it's posted now and I think you'll find it very interesting reading. So what have you learned today? Well, obviously,
flashback is simple. It's simple in design. It's simple to implement with Cisco validated designs. It's managed through Cisco inners site which has those device connectors into vmware and pure. As we talked about each element can scale independently of each other. And it hosts a wide range of applications right,
it is sustainable, right. I've talked about a couple of the elements of how we manage sustainability in the flashback design and others that have done full reports on how well flash tack versus others in the marketplace meet from a sustainability standpoint and obviously secure. I talked back to tra but insight also has the ability to deliver patches automatically to you before you encounter problems.
And also there are certain elements of the hardware aspect. You know, Intel has secure core as a feature within the latest processors. We've exercised secure core, we've written white papers on it, the latest one being in the VD space by the way. And so whatever features our hardware partners come out with,
we exercise and test to provide that extra layer of security to you. So flash check at the end of the day really is simple, sustainable and secure. And what I'd like for you to do now is pull out your cell phones and schedule a meeting within your own companies. You're gonna do a couple of things and I'm only gonna talk about the fact you came to Vegas and you came to this,
this presentation on flash tack. OK? And then you come up with a list of some of the infrastructure within your data center that's a bit long in the tooth that maybe you'd like to replace. It's getting a bit old, takes up a lot of power, a lot of space in your data center, come with that up with that list.
And then as you leave here today, go by the zone. We've got the three quarter mockup of an X series chassis. We've got some experts there. They can talk to you all about it and about three steps away from our booth literally are the flash arrays for flash stack. And they've got experts there. I can tell you talk to you all about uh peers
investment into technology, reducing power usage and maintaining the performances we've heard about in the keynotes. OK? And then lastly is that, you know, you're probably wondering what size of bread box is this? How big of a check do I have to get to write or do the pay as you go model? That's where we can help you.
Since you attended today, you all get a free sizing a flash deck, right? Take advantage of it. Tell us what kind of workload you want to run, which growth rates are and our experts will sit down with you and say, OK, you need a system that looks like this. It's one X series chassis four compute nodes and two arrays or what have you.
We can give you a very accurate sizing based on all the Cisco validated designs that we've done. OK. So lastly, you know, there's a journey to take from this point forward to help you meet your goals into the future. Help reduce the power in your data. Centers, the space give you the performance. You need a flexible design. We're here to take that journey with you.
We Also Recommend...
Personalize for Me