Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
46:42 Webinar
Infrastructure and Platform teams - UNITE!
Come join us and learn how the Portworx portfolio builds upon many of the same concepts and enterprise-grade features that you are accustomed to - and become a hero for your application and platform teams that need high availability, disaster recovery, data protection, app migration, and more!
This webinar first aired on June 14, 2023
Click to View Transcript
All right. Uh Thanks for joining us today. Uh My name is Raj Tucker. I represent uh works. Uh And uh my role is specifically uh product marketing. Uh Our team here today is gonna talk to you about how infrastructure teams and platform engineering teams can unite to really drive app modernization.
And uh I'd like to introduce uh my co presenters, Tim Darnell. Uh Please say hello. Uh Timm is our tech marketing leader for Port Works and we have also have our esteemed partner uh Michael from uh Red Hat. Uh clearly, you know, they are the leaders in uh and in the ecosystem and driving uh app modernization for all enterprises.
And we're very glad that uh Michael and his old team of have, excuse me, actually joined us uh in all of the sessions here at the conference. And with that, uh let me kick this talk off. Uh And, and just uh you know, welcome all of you uh to this talk track. So um one thing that I'd like to start with is uh with a quick show of hands here,
you know, do, do you folks have in your organization's app development teams. Could you just raise your hand if that's true? Thank you. Um Could, could a few of you all just talk about how many developers are there in your organizations? Just a quick estimate of a number?
Thousands, hundreds, any others? 10 developers, how, how big is your overall company and employee size? Few hundreds. So a large percentage of all organizations have started to have app developers. It's not limited to,
you know, buying a software from service providers anymore or software providers anymore. You are all part of this journey. Uh that platform engineering has begun in your organization. So today, what we'll talk about is how can platform teams and infrastructure teams, whether you're part of a compute infrastructure team or a storage infrastructure team,
which most of you are here uh for uh how can you work together with platform engineering teams to really drive into this app modernization journey, no matter if you're in the first phase of it or if you're in a much more advanced stage, these two teams really need to partner together to make sure that developers are productive. They are really, you know, serving application needs and and really bringing your customers
the modern experiences that they need. So you can become as a company more competitive and out compete in the market. So we went through intros the point of all of this is, you know, app modernization is not, not a, it's not a fad, it's here to stay. We've been talking about containers and cotis
apps for a while. And now enterprises are really deploying these apps at scale and in production, really bringing real time changes every week to your mobile apps. And you know, all the web front ends and all the experiences that your customers have to interact with your products and consume your products or get support on your products, right?
Uh So what I want to talk about next is this really good contrast. Uh And you know, Tim stock track is gonna really go deeper into this. But the world that all of us have been used to for the last two decades was what is on the left side, right? It was very much uh you know, infrastructure teams, you know, led the charge and provided services to anybody who needed
infrastructure access. If you ran an SAP application for your organization, you needed some infrastructure and it could be virtualized if you wanted to run databases. Uh They were also virtualized, right? Because really what you needed was a standard way of making sure that your applications are running and meeting all business requirements,
right? Whether it was uh continuity of those apps, whether it was resiliency needed in those applications, your infrastructure and really your virtual machines delivered to those application needs. And that's the world that we're all used to. And, and you know what we're saying now is that, that's not the world that we will be in,
in the next few decades, companies have actually already started to innovate and, and move to the right to be app centric. And what does that mean? Right. Uh what it means is that, you know, if you, I'll just pick the example of a Geico, right? How have you consumed insurance and, and dealt
with every interface of, you know, reporting a claim or, you know, reporting a car accident or, you know, getting your claim processed has now been modernized micro services are driving these experiences in that Geico App experience or, or the Geico website, right? You have bots kind of pinging you for getting you on a better insurance plan telling you, hey, you've been missing something.
All of these experiences are really built to serve customers better, quicker and faster. And that's where your developers are really driving every single day and every single week, right? And is really the driver of that automation to bring these new features to market uh in all industries, right?
And that's where the role of platform engineering comes into play. So you have developers who are building these features, they obviously need access to the right infrastructure, right? And uh both platform and uh infrastructure teams have to kind of work together to serve their developers, right? And and really bring developers uh the
experience they need, but also at the same time based on the needs of the application and and your enterprise or your small company or SMB the application still needs to be observed because there are just so many features being built by developers in a single quarter or a single year that all of those require monitoring, they require the ability to scale, they require the same compliance and you know, data protection needs and also a high
availability which delivers that awesome customer experience that these apps are delivering to your customers. So uh has a lot of, you know, beautiful things about its architecture, it's very portable, it's it's also multi cloud ready. Uh But at the same time, you have to have uh platforms that you can trust so you can bring
enterprise great features to COTIS apps and and really bring that business continuity, high availability uh and also uh data protection at scale. So I don't, I won't go too much into this talk track because I don't want to steal Tim's thunder, but Tim will really draw very good parallels of, you know, what the VM world meant for yours that you all are used to and,
and you know, still very much driving as an Infra team, but the parallel to the is an Abric world and what that means for you going forward. OK. But before I do that, you know, you all talked about how many developers are part of your organizations. We've also heard from analysts uh that you know, the developer population by end of 2024 alone
in enterprises is going to reach 29 million and uh enterprise apps that are supporting this digital transformation. There are about 500 million of them uh that will be built just by the end of 2023. These are obviously apps that are reported. I'm sure many others are also being built in test de uh these are just production apps.
So this just gives you an idea for that, that future that we're about to embark on. So why can't you give self service to developers so they can build that next gen app quickly, right. That's really the problem that the port works team and the red hat team is trying to solve every single day. Uh Before I hand it off to Tim.
Could I get a quick show of hands for anyone here who has not heard about po works? All right, I have one hand. So I'll just reiterate that, you know, we have continued to build port works after being acquired by Pr storage. Uh And essentially now the port works platform not only serves uh your storage automation needs uh using port works enterprise.
Uh That's why PR had acquired port works, but we've also expanded the capabilities of the platforms by bringing two other services to the market in that platform. One is all the modern databases that customers are building the developers are using for these apps posts, Cassandra caf and ma few require a single pane of glass for these databases to be managed. That's what's port works data services is on
top of that to meet business continuity requirements for all these applications. We also have port works backup and disaster recovery services. This essentially is the definition and and uh foundation of the port works platform which works with openshift customers, uh the true market leader uh in the space for enterprises, but also with other cloud uh and and upstream providers.
Uh that, that sort of compete with our architecture is, is truly ready for any COTIS deployments and it can be deployed in any cloud of your choice, including hybrid deployments, which most of our customers choose. So I'll sort of wrap there and hand it over to Tim so you can hear from the expert over to you time. Thanks.
There you go. Ok. Uh My name is Tim Darnell, as Raj said, um Just to let you all know, I've, I've not always been a marketer. Uh I actually spent most of my career as a uh storage engineer, uh virtualization, admin product owner for converged infrastructure architectures. Um So I just started Kubernetes maybe six years ago.
Uh So kind of started again where we all came from. Um And Cuber's is a really interesting journey. Uh You know, there's, there's a lot of things in the infrastructure centric world. Um We should all be familiar with something like this right where we're sitting over here, we've got all these developers asking for infrastructure, asking,
you know, for all of their needs that our teams provide um entering tickets and sitting there thinking, hey, this, this shouldn't take. So dang long, right. Um You know, all I'm asking for is a VM and that's what's in their minds. They don't understand. Hey, you know, you've got compute,
you've got network, you've got storage. Uh you know, you've got to set up data protection for all of that infrastructure in a production environment. You may have to clone that infrastructure uh for your DEV test and Q A environments. Um You know, this, this became really inefficient really fast as we had the number of
developers that we have to support scale out and you're not getting funded on your infrastructure teams to have the corresponding staff, right? So Werner famously told us that DEV ops will sol up all of this, right? Um BS, right. Uh He wanted developers to be able to understand
infrastructure and be the infrastructure experts. How many of these do you think this is reality? You have some unicorn developers, sir? Because what I've, what I, what I saw is I worked with customers after I came to the vendor space about 10 years ago.
Uh is developers don't care about infrastructure, they're hired to write code, they don't know how to set up AC P, they can't troubleshoot a path selection policy in VMWARE that creates cognitive load for those developers, right? When you have to contact switch constantly. We all know that you become more inefficient and that's what Werner was asking developers to do,
right? Uh Sometimes you'll have shadow ops. So you might have some of those unicorn developers that can sit there and help your junior developers with infrastructure problems. But again, that drives inefficiency, right? Because now you have two resources that should be developing applications, writing code who were troubleshooting infrastructure issues
just doesn't scale, right? Uh At times, you'll see developers come up with really interesting ways to get around some of these issues and create those duct tape scripts uh or tools you might have a team of SREs that uh you know, have, have this library of scripts and that, that can work fine um if you're on one cloud.
So let's say they've developed a bunch of stuff for AWS to get around some of these issues. Uh Then you need to go to Google or you need to deploy on Prem, right? Um Those tools in that duct tape tooling have to then be modified to support those new clouds again inefficient, right? Because now you're solving the same problem
multiple times as you go across all these different platforms. OK? So platform engineering gets born and it's really not a whole lot different than what we've done in the past two decades. It's just a different name, right? But what it does do is enable that developer self service. I mean, how many of you have used V in all of
your virtual infrastructure for self service for your developers, right? Um So this isn't a new concept. What it does is it really paves that golden path for your developers to have less friction as they deploy across multiple clouds, multiple platforms. Kubernetes adds a little bit of complexity here. You'll see this image here.
This is the CNCF landscape of all of the tools and projects that your developers have to choose from to write their applications. It's not just like vsphere, right? It's not just a set of uh objects in AWS or constructs in AWS that you can use. There's 20 different container network plugins that you could use in Kubernetes.
How does your developer know what they need to choose what they need to run and what gives them that flexibility and consistency across all these different platforms that your organization uses public cloud on premise infrastructure, right? So platform engineering really gives you that capability to cur curate that set of tools and platforms
uh projects that you, that your developers can use to deploy and maintain their code and their applications for your infrastructure now that brings us to internal development platforms. So these are things like V I used to be in vsphere, right? Uh where platform engineering can take a subset of tools projects
uh and really create for development at scale a set of infrastructure tools that they can self service use without bugging the infrastructure or the platform engineering team just to go deploy or maintain a set of infrastructure. OK. So there's several benefits that we get from using ID PS, right? You have things like infrastructure
orchestration, environment and deployment management. You can write scripts to configure your apps. However you want, whenever you deploy them to a specific platform, you've got role based access control to prevent your developers from breaking things or taking infrastructure down whenever they need to deploy. So it gives us that standardization of your
platform for your code to be deployed on no matter if you're running in Google or Azure Aws or on prem. And it really reduces that cognitive load for your developers who aren't unicorns right to where they can function and do their job that they were hired to. So this is what the application centric model really looks like compared to our
infrastructure centric model, right? We have a ton of developers using a curated platform that platform engineering has helped put together and tool. And we still need the infrastructure engineering expertise from infrastructure because platform engineering teams, you may have some people that were infrastructure experts on there,
but you've also got developers and a platform engineering team. Um but you still need all of this expertise that we've built over the years to provide the resiliency, high availability performance of that underlying infrastructure that's being provided up to the platform engineering team to provide down to the ID P for the developers. OK.
So that was a quick recap in terms of platform engineering, infrastructure engineering. The next thing I want to talk about is enterprise storage features and Cuber Netti, right? Um A lot of us are all VM Ware uh or have grown up in the VM Ware ecosystem. Uh VM Ware and shared storage gave us a lot of enterprise storage features that enabled a
lot of the benefits that we see uh from VM Ware, right? We had a consistent storage layer with V San. Um No longer did we need only enterprise storage arrays to give us availability because V San provided us things like failure to tolerate where we could have multiple replicas of our V MD KS across all of these hyper converged nodes.
We had DRS which lets which let us really take advantage of properly utilizing all of our resources and hitting that 60 to 80% utilization on all the nodes across our cluster. It gave us data and application portability with V motion and storage V motion, right? No longer did we uh need to back up and restore a VM? We could just move it live, we could also move
its storage location live with storage view motion. Uh The abstraction layer of vmfs was great because no matter what backing storage we gave VM Ware, we had the same consistent features because of VMS and that abstraction layer of a data store in ESX, right, storage infrastructure was, you know, really enabled using S A VA I and storage
policy based management. Because now we could surface all of those capabilities from a backing storage perspective. And if we had that set up and we realized we could tell the developers, hey, if you need a application to be replicated, choose this policy for your V MD K and now you don't have to go bug the storage admin and say,
hey, can you make sure this is replicated? It was just all done for them. So very early uh beginnings of an ID P like experience there in VM Ware, disaster recovery was huge. Um When I was working at Hitachi, we, we uh we're one of the first partners to do Srm and V MS C with VM Ware and being able to have that asynchronous disaster recovery
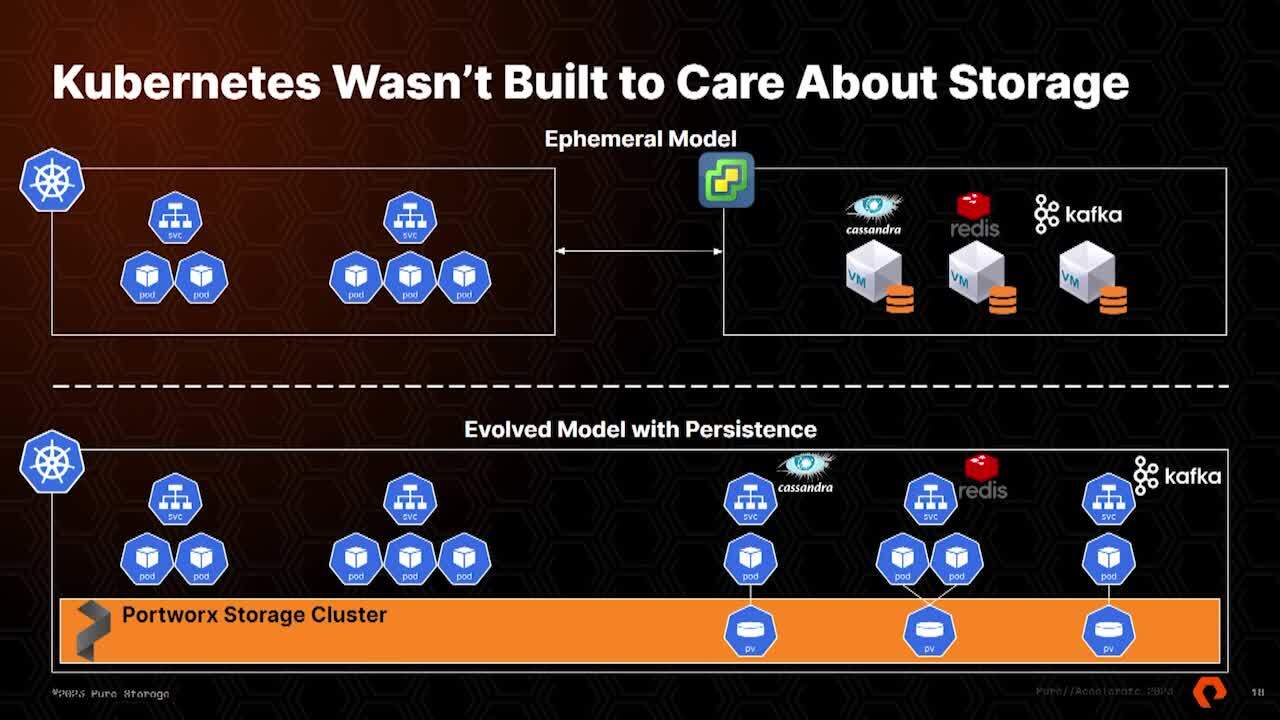
anywhere across the globe. Uh or provide companies the capabilities to do that Metro Dr where they had zero RPO was a real game changer, right? So Kubernetes obviously was not built to really care about storage. Um You know, Google said, hey, you should only be running ephemeral workloads here.
Uh How many of your applications use ephemeral storage only? Yeah, that's the reality, right? I mean, every enterprise app has persistence at some layer. So what you would see is you would see companies deploying in Cuber netti ephemeral pods and then they'd still maintain virtual machines or bare metal
for their database layer, their data services layer. How efficient is this top model? From an infrastructure perspective of troubleshooting maintenance downtime, it gets exponentially more complex as you have more and more of these supporting persistent stacks just to service persistent data needs for your applications. Right?
So that's really why port works was created. Is it it gives us A I like to call it a evolved model of of TTI right? That gives us that persistence where we can now have a lot of the same features from a storage perspective that we had in vmware or with a bare metal attached to an enterprise storage array. But we can run that all in one stack now.
So instead of maintaining multiple stacks, troubleshooting, having multiple skill sets all over the place, we can now run all of that inside Kubernetes and get rid of those straggler virtual machines that are providing that persistence layer for your modernized apps. OK? This really comes into play when we look at
multi cloud because a lot of uh a lot of the native storage that you get from a public cloud, you're not going to have feature parity, right? And so as you as a platform team or a or a infrastructure engineering team is looking at all the requirements that you have for the storage for your persistent apps, you might have one or two that
matches across the public cloud. Um You might have some that match in the public cloud that actually match your on Prem, right? How do you do replication between an Azure disc and an EBS volume? You don't, right.
How do you, how do you make sure that a snapshot that you take here can be restored and applied over there? You might be able to duct tape it, right? Like we talked about with the tooling earlier. Uh But what you really need is that consistent storage layer across all of these clouds and all of these locations, regardless of where you're running.
And that's really what poor works gives you. OK. So similar slide to what we talked about with VM Ware earlier. Uh same benefits and features, you know, we have the consistent storage layer that's provided by the port work storage cluster. Uh In terms of availability, we have replication factors in port works which are
very similar to the V SAN failures to tolerate. We'll create replicas of those persistent volumes for you and spread them out across your worker nodes. Uh We can even co locate them on a specific note if you'd like and you need data locality for those volumes uh via volume placement services, resource utilization. Um Our control plane is very small,
we consume eight CPU and eight gigs of ram maximum uh per worker node. Whereas some of the other solutions out there will exponentially consume more resources, the more persistent volumes we provide. So that leaves you less resources for your application workloads. Uh Would you like it if ESX I started chewing up more and more CP and memory based on
how many V MS you deployed? No. Right. So having that consistent footprint for your control plane is important. Uh We give you application portability via our stork kubernetes scheduler plug in. So Stork actually is the key piece that makes kubernetes storage aware. OK. So if we have three worker nodes uh in our
cluster, we've got a pod running on node zero, node zero dies. Kubernetes by itself wouldn't know where the other replicas of that volume live. So what stork does is it makes it intelligent and kubernetes can now know where the other replicas are, so it can instantly reschedule that pod and come back up in a short amount of time. OK?
Uh We have things like capacity management autopilot. Um And this is all automated. So you know how many of you have woken up at night with a filled disc on a VM? And it's stunned, right? And you've got to expand a data store or you've got to expand a disk autopilot gives you the capability to write rules to say if this
disk fails to 80% grow it by 10 G I and go in and extend the underlying file system. No manual intervention. You've just grown both your disk and the file system and you're still sleeping right? Uh Cloud drives is a really nice feature because you know, as we prep infrastructure to be stood up, um you might have to manually provision
backing storage to the worker nodes. Cloud drives is a feature where we can reach out to the API on the platform that you're running on and automatically provision specific drive types for you for each worker node. Uh When you create your your port work storage cluster and associated storage pool. OK. Um You can also use the cloud drives in
conjunction with autopilot to where if your pool or data store is reaching capacity, you can write a rule to provision additional cloud drives up to your worker nodes and actually extend that pool uh in terms of disaster recovery. And these are the last two, I'll, I'll talk to, you can come talk to us at the booth if you want any more information on these features.
But disaster recovery, we support as sync Dr just like Srm. So a 15 minute RPO anywhere across the globe, we also support synchronous disaster recovery with poor work sync Dr. Uh The requirements are almost exactly the same as a VM ware metro storage cluster. You just need that 10 milliseconds of network latency between your sites.
So if you can, if you're running V MS E today, there's no problem in deploying synchronous Dr Kubernetes using port works as well. OK. The backup piece is pretty important here because uh how many of you use like or for your virtual infrastructure right. It's very commonplace, two vendors, two products.
Um We have our own backup product and port works backup that will not only back up your cnet's persistent volumes, but also all of the cnet's objects that are associated with that application. So it's not just a volume back up and restore. Uh It's more of a Kubernetes application backup and restore that supports backing up your
persistent data. OK? Run into this situation quite a bit with customers who are uh kind of in the middle of modernizing their application stacks from monolithic to modern. OK. They could have 80% of the pieces and services of their application uh modernized and containerized running
on kubernetes. But they still have that like straggler handful of V MS that they can't quite get fully into the modern stack KVM uh runs on bare metal Linux and gives us the capability to run virtual machines on Linux side by side with KTIS port works can act as that shared storage for those Q co two discs
that KVM uses as well. OK. So this gives you the the same benefits in terms of availability resiliency uh that we provide for container based persistent volumes, but also for Cube Vert based virtual machines that you might not have been able to modernize yet. And again, that reduces that churn for you of maintaining multiple infrastructure stacks,
troubleshooting between those infrastructure stacks. We're not going to ask you to migrate all of your 10,000 V MS onto Cober, right? But this is a really good way to uh as you're, as you're modernizing those applications. If you do have a handful of stuff that's still VM based to be able to run it on that single infrastructure stack.
OK. And we're doing a lot of work with uh with Red hat using their open shift virtualization, which is Cobert based. Uh And they've got a really nice migration tool kit where you go register your Vsphere cluster or your V center, you do some storage mapping, you do a network map and it will automatically migrate those V MS from V center into your kubernetes cluster or
into your open shift cluster. Uh And you're up and running as a Cooper BM. OK. So uh I'm gonna hand this over to Michael and he's going to talk to you a little bit about the kind of next steps uh in terms of infrastructure platform and uh and using get ups. Thanks Jim.
OK. Yes. So before I get into what we've been doing around, get up, get up patterns, I just wanted to kind of like frame, frame up, what was already said, right? So kind of talked to us a little bit about this is a path for a app modernization. And Tim took us through the tools that it, that it takes to get us there.
And this last slide that he just presented around uh virtualization Q or open shift virtualization, I think is a real key component to that app modernization strategy because you will still have applications that are not ready to be containerized. So what do you do with those? How do you get that into a similar framework so that your developers don't have to be dealing with multiple tools,
multiple uh infrastructure sets in order to do their work, right? And so with uh openshift virtualization, uh the theory behind it is that instead of, you know, taking this strategy and saying, hey, you have to get everything over into a cloud native application uh platform today, you start developing a cloud native apps within a
infrastructure and you have sitting side by side with that Vert where openshift virtualization, where you're running these applications, you can re hosts those applications uh on day one, have them running side by side ref factor those uh applications over time. Uh you can re hosts uh or you can um rebuild those applications and
start to uh start to build in additional services that are outside of those virtual machines. And then over time when or if it makes sense, you rebuild those applications into a cloud native application and retire the old application. So it's really about a journey as opposed to, hey, let's go, let's go out here and just do this day one.
It's about a journey of allowing people to take advantage of the infrastructure when they, when they need to, when it makes sense for their uh operations. Uh Another thing that I just, I want to bring up and to kind of like frame frame this. And uh I, you know, I kind of like the the slide that Timm had up there, I think was slide 13 where he had all of these different projects that,
that are part of CNCF part of the Kubernetes infrastructure. So Kubernetes is a great orchestration tool for, for containers. But why is Red hat open shift so important, right? Why is it the market leader for KTIS platforms? It's really because of that slide 13, I'm not gonna jump back to it but all of those
additional services are required for for to really be real and valuable for developers to abstract the infrastructure and be able to give them the services, the platform services for operations, folks, developer services, the application services that we build upon all of these things are all of these components and for red open shift.
What that means is we take uh we take a number of these projects and we pull them in so that we have that service layer on top on top of Kubernetes, it's hardened, it's integrated, it's tested and it's product. OK. So you have that framework that is fully supported and that's why that's valuable to developers and operations uh people.
Now, if you take it one step further, there are a lot of additional services and services that we get, you know, think, think of things like observ um the ability to uh to do security uh and uh things like vaults for uh secrets operations and as well persistent storage so that you have the ability to, to do staple applications in these uh in this infrastructure.
All of these components are come out of our partner ecosystem team. Uh We do have some tools as well that we develop uh internally like uh advanced cluster management, advanced cluster security. But we do also have uh a full uh a full compliment of best in breed uh solutions that we work with our partner ecosystem team on. OK. So all of these things are built to work with
red had open shift and we test them uh but they're not product like open shift is product with all the integration points. So that's where these ops patterns really come into uh into effect and help folks. What we do is we build configuration as code with get S and, and we deploy it all as a single code layer which is then maintained over time in AC I
pipeline. So if you think of it this way, typically, uh if you're deploying uh an open shift, you have an open shift deployment, you're bringing in additional components from partners, you have to take your time to install those configure them for the platform that you're running on, et cetera. We build this all in as code, we maintain that
over time. So that as different versions change, we are aware of any gots that might happen and we fix those as part of the pattern. This makes it highly reproducible. It makes makes it extensible out to from uh an on prem deployment out to the edge out to the cloud so that you have that ability to scale those, those deployments as you need them.
And it really helps you as you're looking at going from a proof of concept into production and accelerating that time frame that uh that you have to operate at scale. Uh It is based on tested use case. So any time that we're developing one of these patterns, it's uh based on an actual deployment, it's not just something that we dreamed up in, in a lab, we have lots of those by the way.
But when we get to the patterns that these are tested as use cases that are actually deployed uh out at customer sites. So we that it's actually usable and being used. And of course, it's open for collaboration. The patterns are meant to take you to about 80 90% of the deployment and then you fork it and you use that pattern to make it uh more repeatable for your own individual uh uh deployments.
If you go to red dot ht slash patterns, you can see number of the patterns that we've developed out there. Some of them are community patterns, some of them are actually validated patterns. The one that we've developed with uh in conjunction with uh port works is based on our multi cloud get ops pattern. So the multi cloud gets pattern was developed
to bring in things like cluster, multi, multi cluster management security, uh security tools uh as well as our registry, our global registry and gets. Um but if you look at that multi cloud get ups pattern, you look at the demo that's placed on that. It's ephemeral. What we did with works is that we took it that next step to add in the persistent storage
layer. So and, and really, it's uh it's around these business drivers of having a unified management across multiple environments, dynamic infrastructure, security and continuous delivery with the C I CD pipeline with um with uh open shift pipelines and uh open shift get ups. So that is the basis of the framework and then with port works,
we brought in the data services. So you have a persistent uh data service layer so that you can uh have some um staple applications running there. So if you go to red dot ht slash port works dash pattern, that's where you can get a view of that pattern. You can take that pattern, you can deploy it uh using the validated patterns operator within openshift
and uh or you can fork that pattern and, and um do some additional development on it for your individual environments. Uh really the value here is to make it faster for customers to go from POC to uh to an actual production deployment uh for our service providers for our system integrators, it really helps them. We've, we've found that they've adopted a lot
of these patterns in their labs so that they can then go out to their practice managers, their practice managers can then take these patterns and then uh modify them for their actual uh specific client client needs. So those are by doing this uh um by, by creating this gets pattern, it really extends that ability to the partner community uh of having a fully
functional deployment. So, uh with that, I'm gonna pass it back to uh Tim to take us on. Awesome, thanks. Thank you, Michael. So, uh again, you know, just a quick reminder here port works really gives you that uh capability to have that persistent storage layer, regardless of the cnet's platform that
you're running on. Uh And regardless of where you're running that, right? Um Just some recaps and some takeaways here, right? Uh Nothing we're doing here is really new. This is all infrastructure. It may be in a different place.
Uh It may be using different tools, but at its core, what it is is its infrastructure engineering and providing services to developers, right? It's, it's no different than the old days. So I really want to just drive home and embrace new ways of doing old things, right. Um the industry is going to move forward with
or without us. We still need all of the knowledge and expertise that we've built as it ops over the past few decades to improve that experience for everybody moving forward. Right. Uh We do have some really good breakout sessions in this room upcoming today.
Uh The next one is a Kubernetes admin 101 given by another technical marketer that's on my team, Bovin. It's a really good session. Uh No more dinosaur DB A s, right? That's a, that's a great session for those of you who, you know, have DB A S that are struggling going from those SQL BASED databases to some of the modern
streaming databases or services, some of the no SQL databases, right? And then we've got a really fun session of Port works, food services. We ran this yesterday. I don't know if any of you attended this yesterday, but if you didn't come, come here at 343 o'clock.
Uh it's a role playing session given by our technical marketers and some of our cloud native architects to kind of go through a real world example of an organization and the benefits that they get using Port works. OK? You can scan this QR code, there's a bunch of resources that we have in terms of uh demo videos, instructional videos and
there's a really good blog series linked up here. Uh That kind of walks us through where we've been with virtual infrastructure and legacy infrastructure, what Kubernetes gives us uh and really goes in depth a little bit more on those tables that I showed you earlier uh in terms of the features and benefits and how those map from VM Ware to port works and how we're really similar there.
OK. Uh Come visit us in our booth. If you have any other questions, there will be uh technical resources there all day long. Uh Also we have a partner called Effectual that's just outside of the expo floor. Uh They're really good at getting customers started with Kubernetes, kind of uh figuring out how to get started with,
with cloud native. So make sure you drop by effectual uh have a quick conversation with them. And uh yeah, thanks everybody for coming. I really appreciate you spending the time with us today.
Are you a traditional infrastructure admin getting hammered by requests from application modernization or platform teams? Feel lost not knowing how to provide enterprise-grade features on Kubernetes? Come join us and learn how the Portworx portfolio builds upon many of the same concepts and enterprise-grade features that you are accustomed to - and become a hero for your application and platform teams that need high availability, disaster recovery, data protection, app migration, and more!

Free Trial of Portworx
No hardware, no setup, no cost—no problem. Try the leading Kubernetes Storage and Data Protection platform according to GigaOm Research.
We Also Recommend...
Personalize for Me