Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
42:05 Webinar
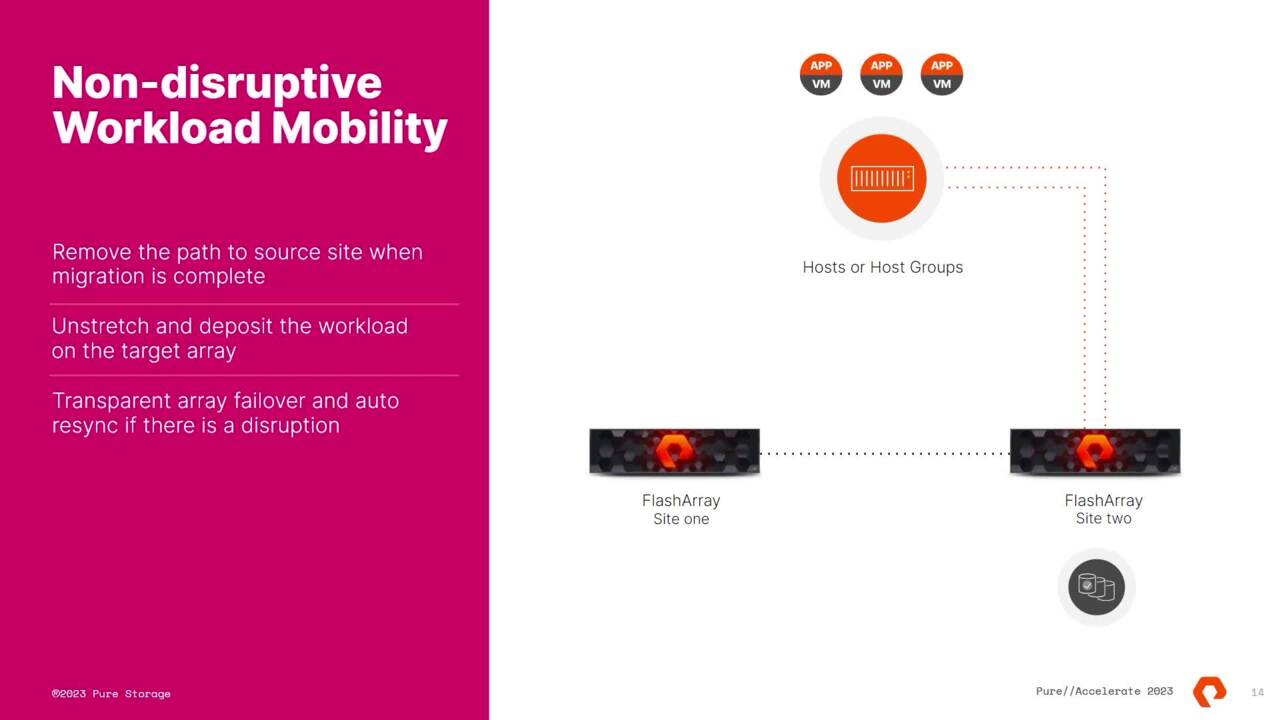
Non-disruptive, Fleet-wide Rebalancing Is Here with ActiveWorkload
In this session, learn how to make migrating workloads across your fleet of FlashArray devices straightforward, fast, and non-disruptive.
This webinar first aired on June 14, 2023
Click to View Transcript
All right guys, welcome. We're going to talk about a new, a new feature called active workload. And if you know active cluster, then you already know active workload because active workload is active cluster on steroids. The big limitation with active cluster was one array connection and active workload is
literally the exact same thing, but you can have five concurrent array connections. There's some more special details to that we'll talk about here in a minute. Our, our missing man is Vin. Um and he might be here momentarily. He's the product manager who helped kind of spearhead this project to put it together. Um Ben and I shaved my head for 30 years and then I have a beard and then COVID messed with
my head too and then I had to grow my hair out because I was watching the Vikings with my kids and they insisted on it and then I grew a beard too. So anyway, Ben and Vin, that's too bad. I shared that and that's recorded. All right. So, so what is active work load? And, and what are we using it for?
Hey, Vin, right on. Hey, your, your timing is Perfect. I'm sorry everyone is Vin so is gonna go over the high level of what exactly active workload provides and then, and then we're gonna, that, that's true. That's right.
Alrighty. He's gonna ignore everybody. It's a big conference room. Have a big, so I couldn't find my way yet. That sounds all right. So thanks Ben for the pro A work Lord. I just want to share our story with all of you and how you're coming to play.
When uh I talk to customers, I usually ask them what their problems are, what problems they're facing and how can we make their life simplified and better talking to customers who have multiple storage products. One of the challenges that they shared with us was a usual workflow that they have, which is when they get a new flashing or they have different tiers of flashing,
they tend to find a scenario specific volumes and work as volumes between those flashes based on our survey, 60% of the customers said that the primary use case is induction of a new slasher. Ok, let's say have two or three or maybe 10 X and then suddenly get ac you know, uh nice and hard steel.
They are placing it in the data center and now they want to actually populate it for it being useful. How they go about doing that in a nondestructive way to the is what we try to solve with that. So, a Walter is built on our stretched clustering technology which is also used with a cluster, but that's for high availability. And this,
we focus here for water. So this functionality allows customers to move workloads between different tiers of arras from X to XL or Excel to X and then X to C without causing any disruption to the post and to the applications that are, that's what you'll see here. And the functionality is available from 640
onwards. It is also a journey for us because it's kind of a massive undertaking in terms of how we deliver this functionality. So we came out initially with supporting how to do this between cross tiers, so you can do ecstasy. Then another request came up that well, I am an active cluster
and how many or few water? OK. So the request came in that I am an active customer customer. And because this functionality also uses synchronous replication. If I'm doing active cluster on the array, how do I connect my production array to a third array and then move my workloads.
So we took that into account and then we said, OK, that would mean that without changing anything within your active cluster configuration, you cannot connect to not one, not two, but up to four other R A and use that connectivity between four other ways to your workloads to the arrest and to those arrests by while you're doing that, there was a customer request that.
All right. So you did solve the problem of worker mobility. You solved the problem of customers will have an active customer already in their environment on that. But I'm AFC customer or fiber channel customer. I don't use IB. So how do you, how do I do that?
So that's where we had to expand our mesh capability and not just support IB customers and IP connections but also with uh FCC. So you can also create a mesh uh approve two area right now or for FC uh for FC. So those are some things that are rolling out slowly as we hear back from the customers, get more feedback on how they and what are the.
Ok. So it's not perfect in down so that you would expect everything there because I know there's a lot more work I uh personally to make it more effective and more streamlined, but it has been a good job and our customers are using uh one of the key advantages that I find uh with some of the customers using the work is the MSP providers who really want to offer storage to their clients without
letting them know that anything is changing uh on the storage and the provider project. Uh They can use this now to actually move workloads from whichever deal they were storing their implants data on to whatever news stories they feel is most apt for. So that has helped M SPS A lot that has helped a lot of customers uh already and I'm working with uh with them to make it uh to make the
future more robust. So if you guys are interested in this, if you find this useful, then please talk to me uh with that. Ben is now going to go in much more detail of what the functionality is, how to use it. And if we have time, we will see if he can do a demo as well. Thanks Ben.
Um All right. So thanks again for the introduction. And uh I know it's hard to find. Actually, I got down here and I was out of breath for a little bit myself. Um All right. So, so what is active workload? Um And I wanted to think of a few metaphors for active workload and the first metaphor I thought of and the best metaphor is Tetris.
You guys ever play Tetris? Everyone played Tetris, right? So the concept of Tetris is that you take the spirit shapes and you most efficiently try to get them into a container. And if you know Tetris, then you know exactly what active workload is, attempt to do, which is the ability for you to efficiently move workloads into a container.
So you get the maximum use of that space, but I can't say Tetris, I can't, I take out all the um references to Tetris because legal ruined it as legal will do. So. Um instead I had to turn to the garage and my garage is a mess. I don't know if you guys, I might get, this is like a new thing I'm into now. Garages because I realize like that's where all
my toys are. So garages are special, special place for me. It's almost like my temple and um my garage is a mess. And uh I found that it was very, very challenging situation to take everything in your garage and organize it according to what you want to do with it and how you want it. Um And to do it in a way that's very efficient. And I thought,
hey, this is a lot like active work load just on a um on a probably just as expensive scale actually. Now I think about it. Um So there was like, or, and then there's V motion and I like V motion because V motion is, is like the next step or our first technological metaphor and that V motion kind of does the same thing. So when I was a systems administrator,
we'd have, you know, resources being taken up by V MS and you'd want to be able to move a VM to available resources or at least be able to efficiently deploy applications. And V MS and you do that with V motion. V motion is pretty magical what I like about V motion. I like everything about V motion. But one of the coolest things about it is, you don't even need anything,
right? Like ideally you put it in your own little network, high speed network so you can v motion more quickly between your servers. But that's all you got to do. So that brings us to active workload. And I mean, I'm trying to draw this connection between my garage and active workload.
But active workload is the exact same thing. But you remember like, you know how it is with storage, like you're locked in. It's like as soon as the workload is on a on an array, that's it for years, like it doesn't move. And if that application becomes super demanding and exceeds the capabilities of the ray, then it's like a whole show to get that workload
moved off, you have to shut everything down, you have to have a maintenance window, they have to work with multiple departments. Um And then eventually at some point, you can finally bring up that application again on on the new system. So active workload obviously eliminates the entire process. It allows you to kind of look at your fleet of
arrays and almost almost point and click and flick workloads over to available um hardware platforms, right? So if you're running out of capacity, flick it over to array with capacity, um you're running out of performance capacity, flick it over to array with available overhead, you have an old array um put in your new array. All right. So that's that's what it is, that's what the
intention is. That's what the design goal is. And so here's a few uh been touched on the number of the use cases. And um and so now we'll illustrate some of those use cases so that we have an array just sitting there. And by the way that, that drove me crazy when I was a systems administrator in the data center, like there would be really high end resources
available for whatever reason, some department had a budget. So they wanted some high end piece of hardware in there and then it goes um completely underutilized. Um And so you can have an array of reaching capacity, you can have an array with performance capacity, you can move. The XL 1 70 is a monster.
So I this is doing performance testing on the XL 1 70 we actually have a white paper out on that and no matter how many applications we loaded on it, we put oracle on there. My sequel on their sequel on their exchange, we kept loading it, loading and loading and loading it. I couldn't get like see over a millisecond. It's pretty amazing.
So with active workload, if you bought an XL 1 70 or an XL 1 30 you could readily move what you need to, to that available capacity or performance mentioned uh the MSP which I don't know what that is or what that stands for, but I get the concept which is that you are basically hosting customers on storage platforms. And I think the power here is that you can non disruptively do things.
So if you have customers that need more capacity, you can non disruptively move those customers workloads over to another array. And this example here we're taking capacity workloads and moving them over to um ac array from a uh X or performance based array. So just to, yeah, the use case was also not just capacity performance. So the provider identified that I accept
that, you know, three years, but I identified workloads of customers who are really using. So I was really, really, but they're still sitting on it, consuming capacity on it, which is a much more performing. And the MSP themselves had to bear that cost while keeping the sales price
of the store same for their employees. So they came up with this curious way that OK, can I nondestructive move? Not so demanding the workers to see which can be owned by sea so that my cost for offering that capacity of storage through my user goes down,
but my contract with the is still the same price. So you know, at the because so uh like margin Tetris. Yeah, that's interesting because now we're talking about a business way of optimizing then instead of just capacity performance. Yeah, I'm a system. So I go capacity performance,
by the way, what's MSP stand for? I keep manage service provider. Oh, ok. So, all right, thanks everyone. Thank you. Ok. So another example here I got Sergeant Mark to here, as you remember, he was kind of replaced by Sergeant Riggs in the Great Lethal Weapon movie.
But um, in this case, you can get young hipper more viral arrays and then you can move your workloads from your old arrays to the new Hipper erase. Thanks for smiling at the viral thing. I thought that was pretty funny when I All right. So um obviously hardware life cycle is a key benefit here because now you can do this non disruptively.
Another use case would be cross fleet pure mobility where you can just basically do whatever you want. And like we've said, a couple of times you're not locked in and you don't have to sit there with that workload for years even when you know, it would be better off for our users if you were able to do that. And I like this one Penta mobility advantage. I don't think anyone has that ability to claim
Penta mobility advantages. Um This slide is actually kind of a lie because it shows six arrays. And then even that I keep thinking you can connect five arrays, you connect five arrays. So the slide represents five arrays that you can connect to, but it's five in total. So I got one array too many here.
Um But yeah, you can connect up the five arrays and then you can do concurrent essentially data migrations or workload migrations uh away or two. And you're not even geography limited here. So you can go as far as you want geographically. The limitation being your standard active cluster limitation that it can't exceed 11 milliseconds of latency.
And by the way, I don't know if you guys know but 11 milliseconds of latency is very specifically a spinal tap homage. OK. So how does active cluster work? This is the part I always like talking to because I did, didn't I? 00 sorry, thanks man. OK. So um but it is active cluster technology.
So I might mess this up a couple of times and use active work with active cluster interchangeably because they use the same mechanics underneath. Now. Um I'm not a sales guy. Uh So forgive me for saying this but like I'm a huge pure Kool aid drinker because every single time one of those engineers like what the guy I was talking about earlier who did stand up
comedy and drums on the side, every time I talked to them about why they did it like give me I want the technical justification for this decision. That technical justification would always leave me completely like spell bound. Like I would just be like, yeah, I don't know why other people don't do it that way. Um Because it's novel, it's clever and it's effective and that's what we do here with this
stretching stretching technology. So what's underneath the back end of all of this that makes it possible is multi pa and I think that's so cool. There's no proprietary crap. There's no black box. Um There's no um sand virtualization. There's no 200 steps that you have to take to be able to get it in the base configuration
that you can start to use. It is just multi pa now there's, there's some with multi path too, I'll talk about. But when you are just using a multi pa you're using tried and true technology everyone's familiar with and everyone knows it. So what this means is, and this is the caveat to use active cluster and or active workload,
you will have to have multiple paths from your host to your storage race. So if I say I want to move my workload from array A to array B, my host that hosts that workload, it has to be connected to both of those arrays and that's it. And I think that's super cool. Like why wouldn't other people leverage multi? I mean, I'm glad they did it, but that is definitely the way to go.
I mean, it's rock solid and that's how you do it non disruptively too. OK. So let's go into a little bit more details here. So this is your standard data center configuration, your host or host groups in a flash array, you got multiple paths between your host and your storage array. That's like this is, you know, like your bread and butter.
So what we're gonna do to get active work load up and running is you deploy your second array. This is your new, this is Sergeant rigs your new or sexier array, the array with available capacity, whatever it is, all you do is you go in that you can use command line two. It's a couple of mouse clicks. You just need the management address of that other array and then you connect them.
And now that array, the source array is aware of the second array one other detail. By the way, you have to prove that you can't connect that array. So you authenticate by getting a key from that second array. So that's two steps. You need the management IP get the connection key and then you can connect the erase.
So when the rays are connected, um we're gonna stretch our data from array one to array two or from the source to the destination array. And all you do here is you create a pod and then you move the volumes in that pod and then you stretch it to your remote array. Yeah, at the volume is or any strategy, do you wanna move your, your workload to that other array?
Yeah. Well, you would have to disconnect it and stretch it and then rest stretch it to the new, sorry. But if that was the array you want, then this is all done for you already and we'll get into uh implementation here in a minute. This is just the nerdy back end details here for how it works. And this is what's cool.
So, so the multi path trick is that what we do is we spoof we spoof the volume. So every volume has a serial number. So when you're connected here, like your typical data center deployment, these volumes have a certain, a certain serial number and that's how multi pa works. That's how we know we have one storage volume versus multiple storage volumes,
right? So multi pa intervenes and says these are all the same storage volume because they have identical serial numbers. So when you stretch it to the the destination array, all we do now is spoof this is the most black box we get, we spoof those serial numbers to the host something right there. Yeah. So um so that's it like that's the magic slick.
So now for active workload to move your your um workload over to the other site, all you do is you just deconstruct the source site, remove those paths or Unz those connections and then you oops, we're missing a transition here. But effectively that yeah, I mean, then the workload is running off of site too. You don't have to keep that array connection up there.
Obviously, if you wanted to move that again or if you had more work to do, you can leave that connection there or make multiple connections now from your destination array to other arrays. Yes, sir. Where let's say that's a VM. Mhm. So they're still, I think so if I followed that. Right.
Well, so what's the idea of what you, because I wouldn't drop that? I wouldn't drop that primary pa let say I got, you know, it's got 50. You mean this, this primary path right here? That's just your replication network. Oh Yeah, you don't. Yeah, this is just the nice.
Yeah, this is just for like presentations sake, but you can keep everything up there. The funny thing is, is like when we talk about multi pa and creating physical pathways to your arrays, like those paths are already ran. And so if you're in a fiber channel network, this is effectively just Unz from here and then rezoning over there, which is cool, you can leave his own. Yeah. Yeah.
Yeah. You have, you have a lot of flexibility here because all, all we need is you just need to be able to have those arrays connected and then connected to the same host. So the host just has to see both arrays, you can leave it however you want, you can add other arrays and other paths too and start to do like uh you could, what's that called again? Where you go and sequence from one bunny
hopping or whatever. I mean you can move Daisy chain. Thanks. There's a Yeah. Daisy chain, I guess. But you, you can pick, there's a number of top that you could utilize whatever best suits you what you're trying to accomplish. Um, so, yeah, you can leave all that stuff up.
Yeah, exactly. So the bottom line for active workload is that you disconnect from that side and then deposit the workload over on this, the destination arrange. Yeah. Yeah. Right. That's right. Yeah. And you can, um, you, you can use one pod, you can use up to six pods.
Uh you can have up to 1500 stretch volumes. So you can sort of organize it or, or do, do it. However you see fit Dahe starved in an sra spot and run every VM on this one volume and then you move one VM to another array. So you scratch it, you end up with an X produce. Uh basically, yeah, that's right, actually. Yeah.
Thank you. Yeah. Well, it depends. So, um we support up to 11 milliseconds of latency. So it, that's right. Your, your, your latency now is gonna be whatever your uh connection is. Um And then plus some odds and ends. So if you have like a 0.5 millisecond of latency locally and your win is one millisecond,
then you're at least 1.5 milliseconds of combined latency. Now, the purpose of course, though is temporary, right? Like we just want to move that workload over for active cluster. It's different because active cluster we're looking at high availability with an RPO zero. Yes, you have to sync too.
So when you first stretch this or you stretch that pod over, it's gonna baseline all the data and then it's gonna sync up and then when all the data is mirrored, that's when you can. So there's, yeah, make sure the right way. I've got a question and uh situation. Um So whenever you're doing this, there's only one existing copy of the data moving around
all of the, you have, you start with the data on one array and you want to move it over to the other array. We are in a um I, I work for a state agency. We're a community cloud. We actually need to physically move racks because we need more electricity because we keep getting six a six. Well, 5.5
still here. But um but I physically need to remove to a rap. So right now I'm having to do the juggling thing, right? All right. Stand up this be motion these here, these here, these here, shut this off, move that move that there this here like I've got a spreadsheet to be here. Can I effectively use this to just say,
go with? Yeah, you could. So I, so the question is, is, is how complicated do I have to make this? Versus can I just literally carve out entire workloads and then send them to the other array? Does that sound about right. You, you can um in, in that case, I'm not quite sure how you might approach that,
but it, yeah, it definitely simplifies it because you no longer have to necessarily worry about host resources and storage resources together because you kind of keep them together, right? So you're moving everything at one time. So the hosts are connected to both arrays. So we're not talking about even V motioning it like you can keep it all on that same server and then move the workload over.
Now, if you want to move V motion over to another piece of host hardware too, you can do that too, but that's a separate layer and that's optional. Yeah. Yeah. Yeah, exactly. OK. So a little bit about the details of how to, how to do this. Um So it is just like setting a active cluster.
I mean, it is the same caveats and the same limitations. For example, we're not geographically limited, we're latency limited. Um You do have to have an active cluster refer to it as a uniform configuration, meaning that the hosts have to be connected to both sides of the replication network. So that is a given or default for active workload to work.
Um And all you do is start with step one literally from the quick start guide for active cluster if you wanted to and you connect those arrays. And in the demo video, I have the time stamps written down. We can, I can show you guys what it looks like from the gooey. If you're curious, I think one of the problems of talking to this like V motion,
like when V motion first came out, you're like, what? And you're like, you, you non disruptively move a host to another, like a VM from one host to another host. Like it's actually kind of hard to conceptualize when it's new. I find that looking at the gooey at least helps to a certain degree.
And obviously, if you could get time in on an array and do it, um that helps you understand it better. Um But uh anyway, going back to essentially a quick start guide you connect, you create your pod and you stretch it and then you uns stretch it and deposit those workloads. So we're moving from, you know, we got workloads all on flash array A and then we
stretched pods over to three other arrays and then we unstressed to get them off of flash array A and that's conceptually all there is to it. So it is that easy. But the gotcha of course, is that all those hosts have to have multi path on them and they almost always do anyway, and you have to have physical connections from those hosts to the
arrays which may or may not actually be difficult. The um ideally and more commonly, particularly for fiber channel environments is that everything's already ran anyway. And then all the connectivity is controlled from a fiber channel switch where you just zone it out or zone it in, in which case it's super easy.
So it's kind of funny because I, it, it's like, yeah, it is that easy. And I don't know if you guys are like me, but I always think, well, there's got to be, got here. There's gotta be like I was alluding to before there has to be some bizarre sand virtualization or some sort of required intervening device or what have you. But no,
and that's why I'm such a big fan that our approach which is just manipulating multi pa and spoofing multi pa connections. Yes, sir. Is there any way to do this with an existing active cluster pot bringing in a further? Oh, well, sort of no.
If you were saying, can I add three arrays to a pod? The answer is no. So, so each pod can only have two arrays. So if you want, so you'd have to do a Daisy chain. If you wanted to move it over multiple arrays, you'd have to do it one at a time. Oh, well. Um That's an interesting use case.
And I don't think that they, they wouldn't have to um would they have to, oh, would be in an unprotected side? I, I have heard about that. So that's not uh I think you could, you clone out a volume and then you could stretch it over
to a destination volume and you can do a kind of a cut over since you have most of the data over there, it would sync up much quicker. I mean, there's like things that you could do that would be a novel approach is that if nothing else would minimize the loss of RPO zero or, you know, minimize the recent times.
That's right. Yeah, that's I'm saying you can, you can snapshot that pot and clone it out and then just ship it over there and then you'll have most of your data there. Now you won't have the latest data. Yeah. Yeah. Which is pretty slick bill for reputation.
Get to do in that was I because it's a no go to Great Earth productive replication for us of operations. So, so I think this doesn't use cases already. But what I have heard is customers are using active using it for.
So they are gathering a chair to their own clients. Uh This is they want to make sure that the has a is maintained widely when the to be the strategy to help us. Ok. Well, which is a good segway to this slide here with uh the no actual licensing to use active workload. Like again, I, I mean, I told you as a Kool aid
drinker, like the fact that we don't license anything I absolutely love and the fact that customers at one time bought our race had no active cluster, no RPO zero. Now they do and there's no licensing fees. I mean, the, the, the takeaway from that is that we're continually improving things. I'm only putting that out because I believe I heard, uh,
talks of, of being able to put three rays in a pod at some point in the future. No, when you hug us, that's another use case. I have heard about it and we would want to address it in the future, but I don't know that it ever happened. Ok. Well, then I'll just downgrade my point which is that it's continually being developed and improvements are always being introduced.
I mean, you can do all this with, with fiber channel as well, right? Because we start off with IP and then we support of fiber channel and they have a great deal of flexibility. You can use two different protocols. And anyway, yes bill.
Um Yeah. So multi pa so again, we're going to that kind of like the caveat of multi pa the multi path is different for different operating systems. So, um it's been a while for me, but if I recall, if you tried to zone everything that you wanted to uh Microsoft, um OS you would run into performance problems or some sort of issue because it chokes on all the available pathways.
So it would just be depended upon those O Os S or applications. And um I mean, for, for my own lab I just stick to four paths per host, um, per habit. So, if I want more, um, if I want more paths then I actually retire a couple just for my own administrative overhead. Um, but it just varies and it depends. Yeah.
Raise up. Yes. Yeah. Right. At least. But that's fine. So, yeah. Well, and that's why I'm saying the, yeah, the volume has all the paths and, and that's the trick because we spoof the volume,
serial number up to multiple paths. But the bottom line is, is as far as multi path goes is that every Os is gonna have its own quarks and limitations, you're gonna have to. Yeah, I mean, I, I generally don't like VM Ware is very robust about it and, and I think Microsoft has gotten much better about it.
So I just plow on and do what I need to do unless I start running in the problems. And then the first thing I look at is, oh, how many paths does this? You had many paths that would transmission matter? It, it, it would sit there and it would basically do a health check and it would kind of toss itself, but they kind of fixed that I think in 2012 or two.
But you always have to be a little bit weary with Microsoft when they release updates to. Uh but those kind of issues don't come back because we've seen them come back in the because when we were running three race, they by nature run a lot of paths scale. Uh Microsoft is the operating system really. And what it is is like uh
if you have a dirty pathway to with multi pa, like if you have a bad fiber channel physical connection, it wreaks havoc on the performance for that host. So like I'm, I'm not a big proponent of just putting as many host connections as you want to a host. That's why I kinda like to limit it because if you're like on around robin uh multi path policy and you have one bad fiber channel
connection, a lot of people don't know this, but a fiber channel error can quiet the connection for up to 12 seconds. It's a big performance hit. And uh so if you have round robin and you have one of those paths do that, then it causes all kinds of issues for the host. So I like to keep my paths limited to just what I need for whatever purpose I'm using it for. But then again,
I'm just like, I just have a lab and I'm just trying to do stuff like put together decks and talk to people about stuff like I'm not under pressure to have to keep everything fully functional up all the time. Viewer side. The and that will be, yeah. Least Q is that the least Q depth one? That's a great,
that's a terrific option. We need the contention, especially flash blade and flash array because that all comes through the same comic. Interesting. Um, Kevin and RT. Oh, yeah.
Ok, thanks. Sorry. These are great questions. Um All right. So, uh, this is the demo. Um, and I, I can't stand hearing my own voice in the demo, so I'm probably gonna be wincing a little bit, but let me, um, let me get right to the time stamps and then I can show you the steps themselves and
what it's gonna look like. Um And as I said, if you know anything about active cluster, you've ever implemented active cluster, this is all gonna look very familiar. Let me go full screen here and I don't even need sound. But um these are the general steps that you will take to uh get everything
up and running and that first step to connect the arrays, it's super straightforward. So you can, oh I have no video controls. OK. Hang on here guys. Well, that's, yeah, mentioned for the years of the power to get them to arrange plus the
OK. Uh Can you repeat that question? Oh Thanks man. Yeah. Oh That's right. Yes. Yeah, that's right. Yes. So um we are, what about the, so the question I think is that um Yeah, so that is something which is like I was saying,
Jeremy, tell us about you. Is there then given law was very establishing and lovely. OK. Is that a good thing or that very important. So would you want to establish it by yourself or would you want? Right. The first, the first, right. OK. Yeah.
So that's what I thought. That's what I'm guessing. So I'm pretty confident that we have a solution for that the coming months and that will allow you that you might see. Yeah, the, the support thing is sort of a holdover from when we introduce active cluster because there's a number of variables with replication network and host connections.
And when you open that case up with support, they walk through all those steps and make sure that they do all the sanity checking to make sure that you're clear for take off. It'll be nice when you guys can do it particularly for active workload since it is non critical and you don't care about RPO zero. That's actually one of the nice things too because if you are doing a workload migration and you drop your connection,
it's the same recovery process as active cluster. Yeah, brand new. But setting up that request. In other words, you have to call to export Council water network today. Yes. So basically, so you'll just have a sync is the option and you'll say like device no, for a AYC, you can do it yourself right
now. Yeah. Active cluster is a special one because we got to check the replication networks. So and and I'll just show you real quick. So with a, a sync you go to the protection groups and you just define your target. So we'll just get right back here to show you at least the visual.
And step one is to connect the arrays. And in this example, we have the arrays connected or we're gonna connect the arrays. So we gotta get the connection key from the remote array like I alluded to before go back to the connect Ara dialog box paste that in, put in the management um or choose sync replication and put in the management IP.
So this is just step, one is super straightforward and simple and now you have your array connection. So then the second step that we gotta do is we got to create that pod and the pod is sort of like a metadata framework that we created that allows us to find when data is essentially stressed stre uh stretched.
So here we're gonna move this, this workload or this volume into this pod and this pod is not stretched. And by stretching it, we effectively add another array to it. And then what we're gonna do is we're gonna just take that data in that volume and I'll stretch it out between two different arrays. So here um the resolution is OK, you can see that we're resync and then this is that part
where you're gonna have to wait a little bit for that baselining of data. And once that, that baselining completes you have mirrored data now, on both sides and this is where you can disconnect and start the process, end up depositing the workload um on that remote array. So on this side, this is more or less some of the details where you also have to make sure
that you connect the host on both sides. And then I will just fast forward here because we're running out of time to the final step which to unstressed the workload. So here I have an error because I didn't disconnect the host on the other side. So it blocks you from making mistakes, right? So it wants you to do everything according to
uh what is the cleanest possible, connect and disconnect state for the host and you can't hear it. But in the background, I'm talking through this. So we're gonna go over to the other array. We're gonna click on that volume. I'm gonna disconnect it from that source array and then we'll go back over to the remote array and un stretch it.
And now that data you can see down here in the bottom that the data has transitioned from a mirrored, right? Workload to a local, right? Workload. Yeah. So there's, there's a few steps but the steps are literally that straightforward connect stretch and then on stretch.
OK? And they, they got you being the back end, you have to make sure you have your host connected, worry about the mediator and all. Um You don't have to worry about the mediator, it's there, it's still operational. Yeah, it's still being used. But other, but you don't have to worry about it.
Um, being accessible. For example, you don't have to have like the secondary interfaces configured um, and two different management switches. Ideally, so you can break from our best practices. Big time for. It'll drive you crazy. Yeah. Right. Exactly. Yeah. So we, so it's not mission critical and,
and if it breaks then you just have to restart that, that workload, migration. That's it.
Has migrating workloads across arrays cut into your personal time? In this session, learn how to make migrating workloads across your fleet of FlashArray devices straightforward, fast, and non-disruptive. That's right—zero downtime, with no impact on your business services, your users, or your outside life.

Test Drive FlashArray
Experience how Everpure dramatically simplifies block and file in a self service environment.
We Also Recommend...
Personalize for Me