Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
41:22 Webinar
Optimizing Unstructured Data with Advanced Workflow Management
Learn how Pure Fusion™, Zero Move Tiering, and Rapid Replicas help manage and scale unstructured data while reducing complexity.
This webinar first aired on June 18, 2025
The first 5 minute(s) of our recorded Webinars are open; however, if you are enjoying them, we’ll ask for a little information to finish watching.
Click to View Transcript
Hello everybody, thanks for thanks for coming out. I know we're the last session between you and drinks and also Oz Perlman, so we really appreciate you coming out and spending your evening with us. Uh, so, uh, by ways of by means of introduction, I'll let Amrita go first. Hi, my name is Amrita Das, Flash Product Management.
Uh, and I'm Hari. I'm a hardware architect at Pure so I work on Flash ray and Flash Blade. So we're gonna take this session to walk you through some of the changes that have happened, you know, on, on the flash blade side over the last year and then walk you through a bunch of, uh, cool new work flows that have been developed.
So in terms of agenda, some of this might be a bit of a refresher for those of you who are in the keynote or other sessions, but we'll just touch upon a few different topics we'll talk about the, the advancements on the hardware side for SR2. And then Amrita will talk about zero move tiering, rapid replicas, and fusion, and then finally we'll tie off with something that's,
you know, an Apple style. One more thing, we'll talk about Flash plate XL, which builds upon a lot of the stuff that you know and love about Flash plate, but for a very different market. So without further ado, let's talk about flash blade SR2. So it's R2, meaning the second generation of blades.
So just for context, Flash blade has not been GA for was it about 8 years now at this point in time, um, but we are now in the 2nd incarnation of the flash blade chassis, if you will. And that's why this is R2, meaning the 2nd generation of blades within this chassis. So at this point in time we're actually delivering on our evergreen promise.
Evergreen, for those of you who are familiar with Flash array is the ability for you to perform hardware upgrades, uh, non-disruptively, of course, where we provide you new controllers that get you on to the latest generation CPUs and Nicks and memory and all of that good stuff. So it's a very similar idea on the flash blade side of the house too. We're providing you with new blades.
And those new blades come with again new new CPU, new memory, new components which boost the performance that you can get out of the chassis. But you preserve the rest of your investment. All of your drives still stay in place, the networking stay in place. Flash blades is a slightly different system than Flash arrays, so we can walk through the differences and the,
the future upgrades that will be possible at any point in time, if you have questions, feel free to stop us. Love to make this interactive. Yeah, please. Great question. So Flash Blade is really our platform for management of unstructured data, um, right? Flash Blade nally supports file and object.
We're looking at large scale out types of workloads. So this is a quick primer on some of the hardware changes we've made, and then the following changes are on the workflow, um, around workflows for managing unstructured data, and that's what Amrita will get into. OK. Um, so, quick recap, this is a slide that I
believe Rob Lee used at the keynote yesterday. SR2, the second generation of blades, a 70+% bump across the spectrum over the previous generation. So it's really a huge jump in performance. If you think about our CPUs jump maybe 10 to 15% generation over generation. So not all of this is necessarily attributable just to newer CPUs.
We're doing a tonne of work under the hood. There's a lot of intelligent hardware software co-design that I'll spend a moment talking to on my next slide. We're, we're significantly outpacing the competition. I think we look um extensively at all of the competing arrays. Scale out is a much more interesting beast than scale up because again people can get to
different performance levels with a different number of nodes. So once you start normalising either on power or number of nodes or rack units, etc. we look at all of these metrics and we're easily more than 2x of, of anybody else out there. So what's under the hood? Flash plate, for those of you who aren't
familiar with it, is a 5 rack unit chassis. The fundamental element of flash plate is, is a blade. So you see the cutout on the picture over there, that's a blade coming out of the chassis. And there's up to 4 drives that attached to the blade. Our drives are called DFMs or direct flash modules.
Most of you are probably aware, we build our own drives. That's not because we can build boards better than anybody else. It's because of this really deeply integrated hardware software co-design that lets us take advantage of all of the the good properties that Flash has to offer. By virtue of that, we support really large drives cause today uh spoke about a 300
terabyte drive that's coming out at the end of the year. Flash plates support S supports 18 to 75 and the 150 going to be enabled on S in really short order. We support 150 on the flash plate E platform today, um, just for the record. I mentioned that the hardware upgrades are non-disruptive, which means that you could pull
out a blade, you swap in the, you, you pull out your R1, swap in your R2, you move your drives from the R1 to R2 blade, and all of this happens without any sort of downtime or any hiccups to your application. They have a couple of pictures of the front and the back of the chassis, so the blade slot into the front, there is an embedded switch within the flash blade system
that's part of the IO modules that you see at the back. Again, everything about the flash blate chassis is evergreen. This generation we're launching new blades, but you can believe that in future generations we'll be looking at upgrading networking as well. So thereby preserving your investment again, everything needs to get faster in the chassis
the CPUs, it's the connectivity, but also all of the networking and interconnect capabilities. Yes, please. The IO modules do not change when you upgrade from R1 to R2. That's because we futureproofed the IO modules when we built R1. So there's access networking capability that R1 was not able to take advantage of that with R2 we will finally be able to.
Yes, the remaining 4 ports will be available, so we'll be rolling that out, uh, in the fall. OK, um, so from a workload uh perspective to your question again around unstructured workflows, um, we looked at applications. I, I told you we're 70% better across the board, but then when you look at individual applications such as AIHPC or EDA genomics,
etc. we see extremely significant boosts. So we ran a bunch of numbers, lots of tests. Happy to share the raw data with you offline or if there's any application you care about, come talk to us. But in excess of 2, 2.5 to 2.7 X uh improvements across the board. So it's a significant, significant performance bump within the same power thermal envelopes.
So how do we do, how do we do this? I mentioned that, uh, part of moving to R2 was moving to the cutting edge CPUs, moving to the, uh, new, newer generation of memories, so that definitely helps. We're also bumping up all the networking interconnect capabilities, so there's a PCI generation bump to the DFMs and internal to the chassis.
There are networking bumps. We are constantly innovating on the flash side of the house, as all of you are, uh, undoubtedly aware. So our nextgen direct flash module significantly improved performance compared to the previous generation. Again, all of this is based on commodity QLC
flash. QLC has hitherto been known as the slow type of flash. It's really hard to get performance of. We're pretty unique in the industry and being able to deliver this extremely high performance out of the cheapest type of flash that's available, which is QLC. And then finally constant purity software improvements like we're improving stuff under
the whole generation over generation optimising our software, removing unnecessary uh code paths, etc. all of which have helped propel us to the 70+% performance bump that that we're showcasing here. So with that I'll transition over to Amrita who'll talk about some of the interesting workflows that we've enabled over the last few
months. OK, um, has anyone heard of Zero Move tiering and what we've done here? OK, OK, a few folks have heard of it. Uh, so we introduced, uh, Zero Move tiering to our flash plate platform. So we were getting a lot of feedback from our customers that,
you know, only 30% of our data is hot, 70% of it is cold. And there's a lot of challenges associated with the way we tear today, right? Like there are different systems you have to manage two systems, you have to, it's a problem and you bring back data from the secondary system, the whole management aspect of it is, is a pain.
So which is why we have introduced, uh, the zero move tiering construct. As you can see, it's a single cluster and namespace. We have performance and capacity blades within a single name space. Uh, the hot data will get prioritised for compute, networking, memory, etc. We take care of all of that underneath with our
purity software, uh, so we call it dynamic resource allocation, and all of this hot coal transitions, etc. are happening via purity. So the hot to coal transition is instantaneous. Everything is in a single name space. We have multiple capabilities that uh are available.
And the data is not really moving. So as you can see, it's a single pool of storage that we have. The the red dots are the hot data that we've tried to show, and the blue dots are the cold data and the transition is instantaneous, and all of that is managed by this algorithm that we've built into purity.
So again, the things that we're offering with the ZMT are, it's a single cluster and namespace. So you have, uh, the performance blades are the S 500 blades with 37.5 TBDFMs. Then we have the capacity blades that we're offering, which is the EX chassis that is part of the system. You can have 75 TB or 150 TB DFM so that's the
archival piece of this, uh, whole system. Uh, we prioritise the data so your hot file systems will get, uh, higher performance classification, so they'll get better networking, they'll get better memory, they'll get better CPU and the cold data will not get as much, and we take care of that all internally.
So there's no data movement between blades that's needed or across systems that needed. Everything is policy based. You can also pin your file systems if you choose to, so we offer multiple options here and I'll talk about that in a minute. And we've seen that because of this there is a significant TCO reduction because it's, it's a blended platform with your capacity and your performance plates put together.
Oh yeah, sorry, yeah. Yes, the performance chassis will have the 37.5 dBDFM at least now we will, as we go along, you will see the configurations become, uh, the, the some of the rigidity that we have today will go away. You'll see more configurations as we go along. So the performance chassis we will have the
37.5 TBDFMs and the expansion chassis will have the 75s and the 150s. when you chassis. Uh, it'll depend on the metadata, right? So if we are, we will keep alerting you. It can totally run out of capacity, so we will keep alerting based on the metadata performance on the performance piece of the
chassis and the capacity piece on the expansion chassis. So we'll alert at 180, 90, and 100 at 90 we start back pressuring the rights. So you'll, you'll get all the information. OK, any other questions? OK. Um, so yeah, we've introduced two storage classes here.
We call them Speed and archive. So basically the high performance storage class, the S class as we call it internally, is, is the one that, that all the compute resources, the networking, the memory get prioritised for the S class, and then we have the cold storage class, which is the capacity optimised ones. So in December when we launched it, what we allowed you to do was pin file systems so you
can actually pin your whole file systems as hot or cold. The biggest change that we've made is that we are introducing the concept of policies now. So there are storage policies available which give you a lot of flexibility in how you can manage your workloads. So within Purity, you'll see within policies you'll see the storage class steering where you can specify the policy uh that you want to set,
so you can create a policy at a file system level. Today and we'll talk about object in a minute so you can specify the name of the file system. You can specify what your archival rules are, is it a time? Is it M time? And then specify the archival time. So beyond 30 days, I want this file to become code.
You can specify those options and the retrieval rules can be set. It could be on read or it could be only on right. Metadata ops will not make a file code. Um, will not make a file hot, right? So it's if it's a file list operation, it's not gonna, uh, it's not gonna be counted as a hot file.
So you can easily set up the policy. Once you have created the policy, you can add your file systems, uh, to this policy, and then that's it, you're good to go. So we've started off with file systems and that's what's available today. It's available with the 4.6 release.
We are adding bucket pinning. Next month. So for object we'll be able to pin buckets and then similarly we'll start offering these policies for objects as well. So you'll see that come through the course of this year, but today this is what's available. You can set a policy very easily a time,
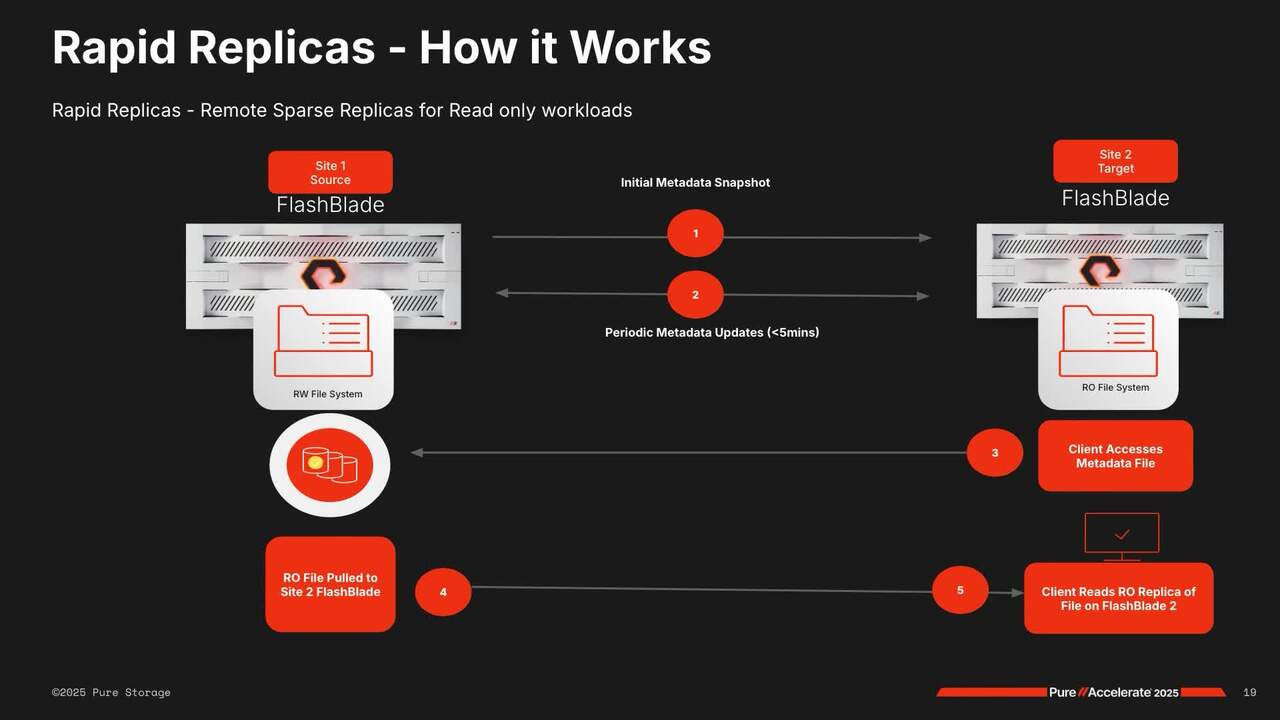
M time and the retrieval rules and that's it. You're good to go. Um, OK. The other capability that we introduced within FlashBlade was something that we call rapid replicas, so we were getting these, uh, use cases, especially for AIML training type use cases where uh the compute resources in site one are oversubscribed.
So you really wanted to go to site 2, burst to site 2, and use the compute resources in site 2, which is why, um, we introduced this concept of uh async metadata replication within Flash plate. So what this allows you to do is you can get fast on demand access to your data, which is read only on multiple sites. We support up to 5 sites today,
uh, with the NFS protocol, and we will expand to other protocols as we go along, and the file content will only be transferred when you access it, right? So it's, it is a read only copy on the other side and it'll get it'll get pulled only when you access it and we'll walk through the architecture. We're seeing a lot of customers trying to use
this for EDA workflow, so basically chip design verification. We're seeing this in AIML training, genomic pipelines. Uh, we've been talking to a bunch of fintech customers who have use cases for this in their environment as well, right? So this is something that we've been, uh, that is available within Flash play today.
Um, so this is how it will work internally. So this initially it's an async metadata replication. So Flash blade already has replication built into the platform. You can just select the metadata option while you set up your replica link within a flash blade. There'll be periodic metadata updates between
the source and the target, less than 5 minutes is what we're looking at. The client will access the metadata file and the file will get pulled to the site and the client, the site 2 can actually read the file, but it's all read only on the on site too, but this makes it very easy if you want to burst out your workloads to site 2, if you have multiple sites that you want to burst to,
etc. Yeah, go ahead. Uh, no, no. Oh sorry, uh, the question was, uh, the, the latency between the source and the target, and if they want to be, if they have to be the same flash player on both sides. No, there isn't. We do have version compatibility matrix like
what versions work and minus 2 will work so that that will be a consideration and uh again it will depend on the network pipe, etc. so it's it's, it's metadata application, so it is very fast, not latency dependent at all. I saw, yeah,
and I know you'll be talking about workflows later everything you described in the last couple of minutes is it also possible to do APIs, everything is possible through the APIs. We will also be tying this into fusion as we go along. So when in the fusion presets, you'll be able to see these options of snapshots, replication, rapid replicas, etc. show up so that you can create these presets
and that just manage your entire workflow. Uh, was there a second part to your question? Sorry, I missed it. Uh, right now we focused on the S, but we will add E to this as well, um, as we, as we go along. So it should be, yeah, the multi-site is for S, but we are gonna, it's, it's more of a qualification thing.
As soon as we qualify it, we'll just update our matrix and and make that available. Yeah. OK. Oh, sorry. So this is uh how you set it up. This is the replica link creation page that you have in the GUI. Again, everything is available by APIs as well. All you need to do is select the partial replica check box over there.
There's no licencing or nothing involved. You just upgrade to the 45X code line, and this will be available for you to start using. I mean, if, if we could pause for a moment, we, we were curious if you had any other questions or places in your ecosystem that you thought that this was rapid replicas and uh ZMT could be, could be used or interesting. These are different solutions to problems that
have existed for a while like traditionally other vendors have done tiering where you have. To manage that yourself or you have to copy stuff over so this is our way of solving these problems much more innovative is what we think. So we'd love to get feedback or any use cases where you think that this would be disconnected somehow is the caching.
You know, objects that have already been read on the other side, how one of those captures that's something where it goes online as the meta data. Uh, um, if the, sorry, if you can just. I, I didn't quite follow the question. Yeah, yeah, it will stay available over there, but it
will be older data because the, the link is gone and you're not getting the periodic updates. Yeah, and we'll also provide options to evict data, etc. uh, you will see that come in upcoming releases, so you can evict older data in case your, uh, link gets broken, etc. But yeah, it'll just not updated, but it'll
keep it there because of the policy that you've selected. Yeah, please go ahead. It's the Is the purpose of this to just save capacity on the replica side? Like, is that being, I, I, I'm confused by like what. Yeah, you don't have to do, you don't have to do a full replica,
right? And if you, if you just are using it for burst type situations, especially in the AIML training workload type scenarios, this could be very useful because you're saving on latency bandwidth, uh, networking capacity on the other side, etc. Exactly. Yeah, you can, we also provide the push API.
So if you want to use the push API, you can also push the API. You can use the push API to push data periodically. So there's a bunch of options available. Yeah, we see this applicable where you have a larger store, and then maybe you have at each of your edge sites, they're fair,
they're smaller. So, so you don't need to size them all equivalent and you just pull in the data that you need, which could be different at each of these edge sites. Yeah. Is there a plan to do certain things at subdirector level.
So if you have a large file system but you really care to have a replica of only a smaller subdirector. Yeah, we are looking into, we, we are internally calling it local junctioning till marketing comes up with a better name. So we are looking at multiple things that we can do at a subdirectorory level and what are the capabilities that we should make available at a subdirector level that that is being
looked into. But right now this is all at the file system, uh, level, uh, like the flash blade replication is. Uh, precise. This is not just for buckets. This is also. Yeah, this works right now on NFS.
We will expand it to SMB next and then look at object use cases. So that's, that's our plan. Um, The other new thing that we introduced and we've talked about the enterprise data cloud quite a lot, and the enterprise data cloud is made possible by the fusion technology uh that we have.
The new thing that's come in is Flash Blade is part of Fusion now, so you can create your fleets, you can add flash array and flash blade to the fleet. You can also create presets. So today you'll see file system creation as the first step in presets that we've taken. You'll see us add replications, snapshots, QOS, all of those capabilities will uh start showing
up. We also introduce always on QOS to flash plate, so that's already turned on by default. We've also added file system level ceilings to the flash plate, so you will see some of these presets show up within fusion as well as we go along. So, uh, a lot of work being done on the fusion part.
You will see governance is and compliance are the next use cases that we go after from a fusion perspective. So how do you wanna talk about the flash plate exa? Sure, I guess before I transition over to talking about XI, any other questions about other workflows? Amrita is our lead product manager for all of our flash grade features.
So if you have any questions at all, she's right here. That's your time. Well we'll be, we'll be around at the end. So, uh, to move, we spoke about S, we spoke about a bunch of new features that we've introduced, and now to talk briefly about XA, which is a new platform that, uh, that just went live as of yesterday, right, um.
So why did we doXA? So this pyramid is meant to to capture the HBC and AI opportunity as we see it. We've spoken about how S is a really good platform for HPC and AI, but when we look at practitioners of, uh, AI, we, we see people fitting into multiple, uh, I guess realms of this pyramid.
Traditional enterprises, commercial all fall within what we would call enterprise AI, and this is where we believe S really is the right solution for the for you and for them. Um, so this we've worked extensively on, uh, certifications with our ecosystem partners such as Nvidia where we've come out with architectures like BasePods, SuperPod, Nvidia cloud partnerships, etc.
which are all tailored towards handling AI in the enterprise. But as you go into building larger GPU clusters, so if as you go beyond a few 1000 GPUs, you're thinking 10,000, maybe 50,000 GPU clusters, that's where the traditional architectures don't necessarily scale as well. So we, we see, we saw a need for. What we're calling as the AI factory that's
comprised of HPC labs, you know, specialised GPU clouds that are in the 10s to 50 50s of thousands of GPUs, tech titans or AI natives, etc. and then finally at the tippy top of the pyramid are the, the hyperscalar such as Meta, um, and for those of you who are in the keynote, I think Charlie laid this out well where he laid out sort of our three,
approaches to solving each of these tranches. So S500 is going after the enterprise AI market. With hyper scalers we are, we are, we have various partnerships going on. We have custom development such as the one that we've announced with Meta which really tackles the problem at a very different scale where it's perhaps more of an IP sharing arrangement than necessarily building entire solutions.
So XA was aimed at this, at what we're calling as the AI factory over here, people who are building out these 10,000, 50,000 GPU clusters. Yeah, so think of it really as Flash Blade. Everything you know and love about Flash Blade being the guts of this. One of the things that Flash Blade does really well and that we're most proud of is our
superlative metadata performance. Flash Blade does really well at handling small files or large files, small objects, large objects, of course, tonnes of concurrent accesses, reads and writes all happening simultaneously. So when you're talking about. Such large clusters our thesis was that where most uh most systems that exist today fall over
is in the metadata processing because that tends to become a choke point. You can scale out the number of uh data points that you have by the data point I mean a node that's basically serving data because from the data perspective, all most of what you're trying to do is. Just read from a disc out out there, but it's the complex interconnected web of metadata processing where most systems fall
over. That's where Flash blade shines. So we kept the guts of Flash Blade S as the metadata processing unit, and we extended out by using commodity data nodes that I'll show you in on the next picture. So we, we just went live yesterday. We introduced this at GTC, which is Nvidia's flagship conference 3 months ago, and the architecture is aimed at doing
over 10 terabytes per second of performance out of a single name space. So we're thinking we're talking gargantuan numbers over here. You can handle trillions of files and extreme performance density. We're talking about 3.5 terabytes per second per rack. Right, crazy numbers.
Um, so how does it work, as I mentioned. The guts of XSA are uh the metadata core. So this will be the S 500 R2 that we just introduced yesterday um and all of the performance gains that we have that we that we enjoy from it. So the metadata core um is basically is running all of our S500 software.
What we show over here is a picture of a typical interconnect. so you have a compute cluster which could be GPUs or or say even CPU workers in the case of HPC applications. They would connect directly to our metadata course. all of the metadata requests would come over to RS 500s,
but the data requests themselves. would go over to a set of commodity what we're calling is data nodes. Think of these as standard servers so off the shelf servers they could have SSDs, uh, so we're starting out with SSDs in order to go as broad as possible in the ecosystem and over time we'll look to introduce our DFM technology into these.
Now how does, how does it all work from a software perspective? We, we, we basically use parallel NFS. So, um, if you look at competing solutions out there, the vendors who operate in this space have tended to build their own operating systems, build, build their own clients. We wanted to stay as industry standard as possible, so.
PNFS is part of the NFS V41 spec. It just works out of the box. Your standard Linux client with NFS V41 is capable of PNFS or parallel NFS. And what PNFS does is it enables the separation of metadata and data. So if you were to walk through the, the flow of the workflow of an IO, your request would come from a client. It would fall on the metadata core,
and the metadata core would then direct. The client as to where to go to fetch its data, the client was then capable of directly going to one of these nodes and then sucking the data back in, so thereby allowing us to enable an extremely thick pipe, extremely fast connection straight to the data nodes where there's minimal processing and
minimal overheads in terms of the consumption of data. So we enabled that over RDMA in order to allow for an extremely capable and efficient transport. And um our transport over to the metadata core just happens over happens over TCP. Now the last piece to tie all of this together is a thin control pipe that we show on the
extreme right. Think of that as just a thin pipe that runs between our data metadata nodes, and that's primarily just to keep uh tabs on the data nodes just to to get telemetry to see the health of the system and alert in the event of there being a hardware failure. Any questions? Yeah, great question.
So the question was, uh, are the data nodes provided by pure storage or are they other hardware uh sources? The answer is the, these are commodity off the shelf servers. So, um, we, we have. Excuse me, we have a minimum hardware spec, um, so there's a HCL for these nodes.
There are a couple of hardware server vendors that we are working with, so we'll have specific reference SKUs, but we can work with other SKUs as long as they meet the requirements that we set out for a minimum spec. So the, the next question was what's the minimum quantity of data nodes that are required? We recommend starting in the 7 to 10 data nodes
is the minimum that we recommend. Any other questions? Cool. So to go into the next level of detail, the the metadata core, as I've mentioned, this, this uses, this uses the S architecture as is. So one of, one of our strengths as a company has been our enterprise grade scale and
reliability. Like we talk, we, I feel like we don't talk enough about this. Like we could always be saying more about how simple we are to operate and how reliable our storage is. This starts from the DFM. Upwards our direct flash modules have 1/7 to 1/8 of the failure rates
of standard SSDs. So if you think about these large estates when you're talking petabytes to exabytes, there's that many fewer service calls and that many fewer escalation opportunities. So the guts of the operating system really are the metadata system. These types of systems are typically are typically uh.
Willing to excuse certain parts of their data being unavailable just because the primary metric for success in these type of workloads tends to be keeping GPUs fed because that's where 90% to 95% of the bomb goes. So our goal over here was to ensure that the OS, so the operating system, always stays alive, which is made possible via our metadata engine,
and that's why we run it on this enterprise hardened S500. As I mentioned previously, this provides really good multi-dimensional performance, so Res writes all concurrently happening on small and large files with extremely low latency. We've spoken about the fact that the data nodes use off the shelf hardware.
Uh, a couple of other things that I'd add over here, these were enabling standard SSDs. Over time, we will provide an option where this is pure storage supplied with our DFMs, but again, to broaden the ecosystem to begin with, we're. Starting with the commodity SSDs, we support industry standard Ethernet, so that's another thing to highlight. Some of these systems,
um, from competitors could be on bespoke networks such as Infiniban. We're a big believer in the power of Ethernet, the simplicity of Ethernet over here at Pure. And so this is all gonna be over Ethernet. We, and but we support the, the latest advances in Ethernet, uh, switching technologies such as Spectrum X, uh, that, uh, Nvidia recommends for these types of large architectures.
Uh, Harry, there was a question. Yes. These are Linux servers. I don't even know security in New Zealand. Yeah, great question. So if I can summarise what's the, what's the operating system that runs on the data nodes?
So the metadata core runs purity. The data nodes run, um, uh, so at the guts they run a standard Linux OS distribution, but it's a tuned OS distribution. So that's some, that's an ISO that we pure will be supplying. So we call that the data node OS and so that's something that we will supply in addition to
the metadata core and the metadata. If you like in our our committees administrator. Right. Is this all fall in support of the your completely or is there a division? Yeah, great question. So how does support work?
Uh, I will say that that is a more nuanced question because, um, so the easy answer is the metadata core is definitely under pure support because we supply the software and the hardware. When it comes to data nodes, we typically work with partners or some customers might bring their own data nodes. So the answer is it depends,
and we have a matrix that we can walk through, or rather a flow chart rather that we can walk through depending upon. Whether the partners engaged and or the customers trying to deploy this on data nodes that already exist within them and to figure out where the like where the support burden uh eventually lands, the the succinct way of saying this is that we will always take the first call,
so with I said regardless of what goes on, Pure takes the first call and then based on the, the infrastructure underneath, we'll figure out where it needs to get routed. It Also a spec. Uh, good question. So, um, the question is, do we need DPU's on the data node? Uh, the answer is no.
So, um, again, this is where we're flexible. We, we don't believe in locking into any particular standard. So Spectrum X from Nvidia does not mandate DPUs. Spectrum X is supported on. Their nicks like CX8 and newer. So if you, if you're able to procure CX8 nicks, then we will support Spectrum X off the bat. But if you don't have CX8 nicks, if it's something previous generation,
that's fine. You just won't get the Spectrum X capabilities, but the system will still work. It'll just function fine. And we'd also specify the minimum requirements of CX6, CX7, all of that will be specified in the and we'll support it. Any other questions? Cool.
All right, um, we've spoken a bunch about how good our metadata core works. I, I just wanna take a minute to go under the hood. So I've said that it works really well, but don't take my word for it, but how do we get here? It's, it goes, it comes back to the fundamental architecture. At its core, Purity is a massively distributed
transactional database. We're basically a giant key value store under the hood. And we've spent years perfecting this key value store technology, uh, and that's what enables this extremely high performance, uh, for our metadata. So the combination of this really performing key value store on top of which we have the right log structured metadata engine underneath,
um, and our direct flash really what enabled this high level of performance. So everything is distributed within Flash plate. There is no single point of failure. There's no single hotspot. Everything down from networking. So when you enter the enter the flash plate ecosystem, there is um ECMP or equal cost path routing of uh network connections to ensure that they land on as many
compute elements as possible. The processing itself is distributed across as many compute engines as as are available and finally there are a multitude of software processes that actually. Handle parallel processing of incoming streams that ensure that there is no one single hotspot in the system. If something were to go down,
those processes just spawn on other parts of this, uh, other parts of the system and on other other hardware components to take over and thereby ensuring that there is no downtime or single point of failure in the system. We've spent years optimising performance for variable block encoding, which again is a key piece of ensuring that performance works well.
It works well for small files and large files, but we're not just fixated on one on one size of axis, uh, and finally for direct flash, as I mentioned. Previously we exposed flash concurrency end to end so by hoisting the flash scheduling decisions by flash management by hoisting that out of the drives into the operating system, we're able to make globally good decisions that enable much higher reliability,
much better performance, much lower latency. This question there. Standards standards. Like I, for example, it's something. Um, so the question is, are we, are we doing something like iceberg natively? Yeah. So, uh, the answer is no, so we, we stick to
conventional protocols. So at this point, we're just NFSV41 and NFSV3, that's what we support. But it doesn't mean that. same. I. The kind of sense of environment. What, what were your thoughts about that?
Um, I'm, I'm actually not the expert on what Iceberg does relative to NFS. I'm not sure if you know more about that, but we'd be happy to take an offline conversation and then get to the experts to talk about that. Robert would probably be the right person. Thank you. I think there was another hand. The responsibility of laying out you mentioned you're using server.
Yep, yeah, that's a great question. So, um, so we do this on the metadata core because that's where we see the need for handling multiple streams concurrently most. So on, on our traditional products like S and Flash array, etc. the direct flash technology enables that performance across the board.
Today, in order in in today's launch of XA, we're using commodity SSDs to broaden the ecosystem that EXA can play in. And as I mentioned over time we'll introduce uh our DFMs and that'll bring these benefits of DFMs to the data nodes on XA as well. But that said, we see the need for this sort of max maximising parallelism most acutely at the
metadata server on the data nodes by virtue of pulling the metadata out of the data nodes, the data nodes themselves are really simple because they're basically limited to giant like get put engines and object parlances or just rewrite engines and. SSDs can do a pretty good job of that. They can do a pretty good job of just exposing giant reed pipes. It's when you get uh a little more involved
when you have a tonne of interleaving of operations that that things get um. More painful, uh, but because we control that from the metadata server, the data nodes don't tend to see a lot of that. Great. Um, so, to kind of tie all of this back together. I mentioned that XA can perform really well,
so here are our performance results. So we, we took, we started stamping out multiple data nodes. As you can see, performance grows linearly, um, up to the right it's always a good thing, right? So you see the read-write ratio stays fairly constant as you add multiple data nodes, we keep getting more and more performance going
into the multiple terabytes per second. So this proves that the architecture is truly scalable. For all of these runs, the metadata core hardly broke a sweat. Now again, that depends upon the type of application. There will be applications where that are a little more metadata heavy,
uh, uh, on these test runs we're able to get to this with one or two, chassis of S500, you know that S500 can scale into multiples of chassis, so we feel really confident that this architecture works well and can scale to tens of terabytes per second. So that was our last slide.
With the question there. How many customers are out there. It's a good question. So, so we just launched it, but are you asking about the time? Like how many customers exist out there? Like a work workload I'm putting on that. Yeah, it's a great question. I'd say that uh uh a typical customer profile for something like this at the 100 100 to 200
data node range, that would be um somebody building a big GPU cluster that's say 20,000 GPUs. So if I were to pick. If you, if you go by, uh, somebody like Nvidia's guidance, right? Nvidia guides to a high performance watermark of roughly 1 gigabyte per second of read performance per GPU,
right? So 10,000 GPUs puts you at about 10 terabytes per second, which is that 100 data node mark, um, so there are a surprisingly high number of. clouds, but I shouldn't say just say clouds, but there are surprisingly high number of clusters being built. A bunch of them are in GPU clouds, but a bunch of them are also within the enterprise.
The Q and video stock price, right?


We Also Recommend...
Personalize for Me