Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
9:54 Webinar
Practical Tips for Accelerating MySQL workloads
Learn practical tips to provide simpler data management, higher density, and higher availability in virtualized environments.
This webinar first aired on June 14, 2023
Click to View Transcript
Cool. Well, uh, welcome, everyone for to, uh, our last, uh, breakout session, uh, on practical tips for accelerating my SQL workloads. Uh, I'm Nihal Meshi, principal solutions marketing manager here at, uh, pure storage. And I'm joined here with Andrew, Who's our principal solutions?
Uh, manager. So we'll get right into it. Um, I think what you've heard throughout our accelerate uh um, conference is around data and the fact that our world is outcome based, it's driven by data, which really is the lifeblood for organisations. And it's driving all the business processes.
And I think what you have also heard throughout this X ray conference is just the exponential growth of data, which by 2025 is going to get to 180 Zeta bytes, according to some analysts. And actually, uh, the the key thing is around the infrastructure, which is a bottleneck. Right?
Um um, we've talked about the end of the disc, Uh, and and the fact that, um, legacy storage can be holding you back. So when it comes to my sequel, what does this mean? So a quick introduction to my sequel most Popular open source database that was released in 1995. It's part of Oracle cooperation now,
and it's distributed either as a free community edition or a commercial version. So, um, from our discussions with customers that have MySQL environments, there are some key challenges that have come up, Uh, time and time and again the first one is around, Uh, with this exponential data growth, uh, the, uh, issue of data gravity and the challenges in data movement moving it from on
Prem to the cloud and having that consistent data plane. The second challenge is around performance and the fact that there have been some bottlenecks, especially when they're using legacy legacy technology that becomes becomes a challenge. The third is more around the threat of data loss from ransomware attacks or any other kind of issues that cause that data loss and then
the fourth is essentially around platform modernised. You know, we are moving to modern apps which require modern storage, whether it's, uh, you know, uh, storage that supports containerization or, uh supports a consistent data plan, whether it's, uh, on prem or in the cloud.
And so the rest of the session we're going to talk about some of the approaches that pure has taken for my SQL environments and, uh, share with you some of the practical tips and strategies. So Andrew, take it away. Thank you very much. So what value does pure storage provide in high school environments? Well, the first part of it for relational
databases, low latency is really important, especially in transactional workloads. But we're a pretty high performance box as well. So, um, it's not just about having low latency. For one instance, it's about having low latency and the ability to consolidate multiple databases into a single location. The next piece of value
is where Flash Blade comes in. So the first one I was talking about was Flash Ray. The second one is Flash Blade. Where does flash blade fit into the story? Backup and recovery is one use case, which, essentially, if you've got a very, very large environment, many hundreds of CM SQL databases and you want to back them all up in parallel.
Flash Blade is absolutely fantastic because it'll ingest that data really, really quickly. But flash is not only important for backup, recovery is where things become important because when your business services are down, you need to get that stuff quick. And finally, port Works which provides to end storage management for,
um, the really cool part about this is Port Works. Also has Port Works Data Services, which is a database platform as a service scenario, where, um instead of oh, I need to manage how I'm deploying the databases, et cetera. We obviate all of that and you essentially just click and say I want a my skill database That's config.
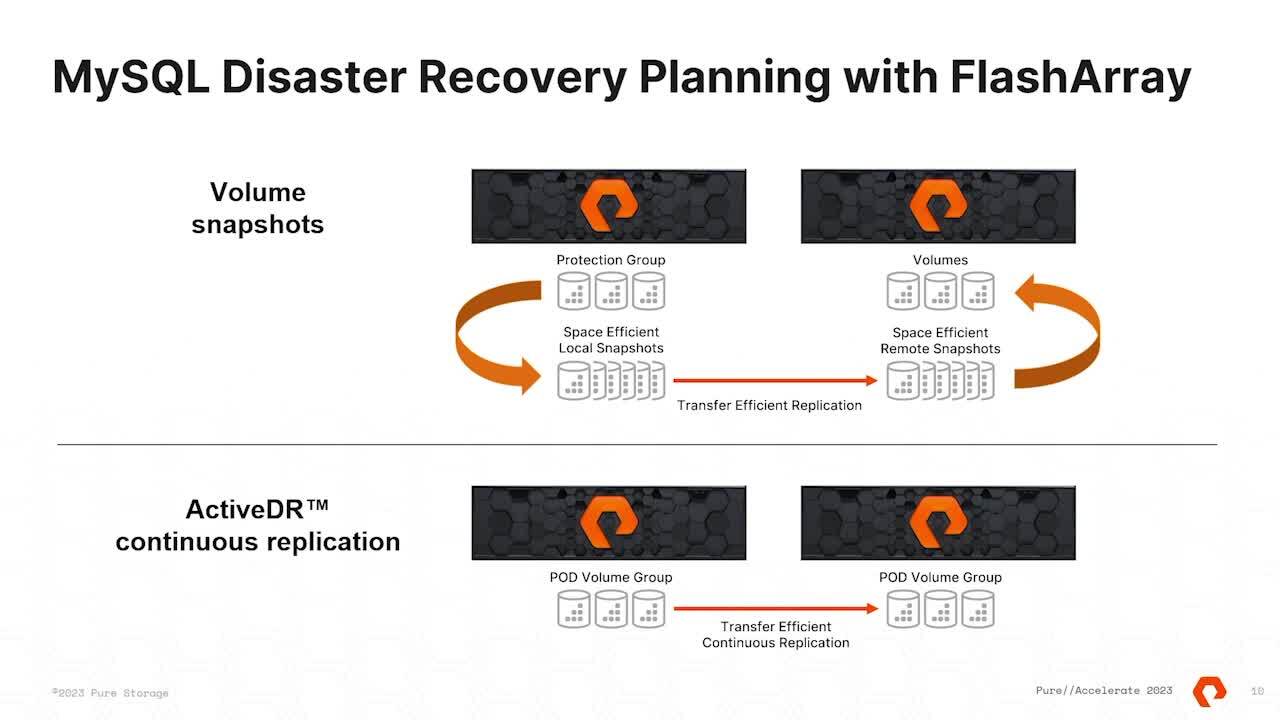
And it does it all for you so you can become a Day two operation focused instead of day one operation focused. Alright, let's talk about how we implement disaster recovery with flash. Um, the first way is with volume snapshots, volume snapshots are fantastic. Um, they are always thin and always de duped. But more importantly,
they're not gonna take up extra space because as soon as you create a snapshots, all you're really doing is pointing to existing data. Um, and in a DJ box, that's not something that takes up more space. It's just pointers to, um, that kind of stuff. The important part about a disaster recovery strategy with a snapshot is that the snapshot
does not reside on the box on where it was created. So we have the ability to transport it to a different array or offload it using cloud snap, um, or snap to NFS. But the important part that actually makes it useful for a disaster recovery scenario is where you do consistency checks on us.
That is your core difference between a streaming backup and a snapshot. Streaming backups will do consistency, check and check sums in line, whereas a snapshot won't do that. And so what you need to think about is a snapshot is complementary to the disaster recovery strategy. It is not the only part of it.
We also have active DR continuous replication. So essentially any change to the database is replicated as quickly as possible to a target location. Er, whenever changes happen, that target location is another flash ara or cloud block store instance, and it can be anywhere in the world. Um, one of the beauties of active DR is its
ability to detect when the difference between the source and the target is too large, and it essentially just takes a snapshot and copies it across, um, to re baseline it and then re synchronise as it goes. All right, let's have a chat about my school. H A How does this get implemented? There's two ways to do it.
One can be complimentary to the other. The first way is to use my score clustering. So this is like using galera Cluster um, primary secondary replication group replication, et cetera. Um, if one node goes offline, uh, you've got something intelligent in between busy taking things over, making the node that's gone offline.
If it was a primary making something else a primary and allowing rights to continue to the database there also a low balancing scenario in there in O DB cluster has all of the bits like the routing. Um, that makes everything highly available to a single end point, which is quite nice. Galera cluster. You have to implement your own load balancer so
on and so forth. But essentially, that's just using it for software. Now, where it comes to storage level availability, you've got active cluster, which is included for free with all of our products. So this is the ability to take two flash rates, um, create synchronous replication between the two of them, and then allow yourself to have right access to both of them.
So if one of these arrows goes down, you still have the ability to write to any one of the volumes where you have a lot more value out of this is where you are implementing application clustering and storage level availability for maximum availability. All right, let's see, what is the point of snapshots when you're using my SQL clustering software? Well, the first thing you need to realise is
that every single replica in that entire environment needs to be a copy of a database, which takes long if you've got 100. Well, if you've got a 10 terabyte data by scale database and you want to create a replica of it, that's gonna take a while. So shots are actually really, really valuable in this equation, because what we can do is we can take a snapshot of any one of the primaries or the
replicas that are all up to date, and we can copy them to the intended new replica, negating the need to constantly copy the the the time. What's even better is if you are inside one single flash array. D kicks in What this means is if I'm running four replicas on one array and you're not using encryption or anything, they're all going to into you.
So your overall consume space goes significantly down, which is pretty fantastic for the very, very big replicated environments. Alright, this slide is it has a bunch of QR codes on it which if you scan every any single one of them, they'll take you to some interesting end points. The first one is the biz apps portal. To accelerate your data,
we've got some fantastic resources on there telling you what pure can do for you, how pure can do it for you and how it can accelerate some of your database workloads and, more specifically, your M scale workloads. We've got some light board videos on YouTube which explain the architecture of snapshots and what they can be used for.
Um, we also have test drive, which allows you to actually use our arrays in line with your applications and experiments with them and see how easy they are to use. And finally, we've got some technical papers that describe how to implement my Q well with VM ware
Is your team responsible for developing scalable enterprise applications on MySQL databases? In these times of doing more with less, is your organization’s data infrastructure providing greater consolidation, operational efficiency, and cost reduction? Is your team measured on SLA deliveries and fast recovery of mission-critical MySQL data? Learn practical tips to provide simpler data management, higher density, and higher availability in virtualized environments.
We Also Recommend...
Personalize for Me