Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
49:43 Webinar
Accelerate HPC End-to-end Software and Hardware Design Pipelines
Learn how disaggregated storage with high performance and capacity-optimized options can enhance the performance of RTL source code and binaries and still keep costs down.
This webinar first aired on June 14, 2023
The first 5 minute(s) of our recorded Webinars are open; however, if you are enjoying them, we’ll ask for a little information to finish watching.
Click to View Transcript
Well, thank you everybody for coming for one of the last sessions of the day. We have a lot more sessions tomorrow, but four o'clock, we're glad you're here. I'm Calvin. Uh This is my uh colleague and what we're going to be talking about today are HPC as well as software developer workloads and how pure can help you with that and what some of the challenges are around that.
So uh just to get started HPC workload, workloads have specific needs and like clearly the most obvious is you need high performance compute and therefore high performance storage and networking. But that is absolutely not the only thing you need, right? All of these workloads need to be able to scale from a performance as well as a capacity perspective, have flexibility and being able to
do that. These are critical workloads. So you have to have the data protection that goes along with the high performance workload and and and infrastructure. Um lots and lots of files, millions of files. So you have to be able to deal with that in a very parallel way, high performance way.
Um And often times a lot of these workloads end up in silos of data like different applications and, and being able to share and, and have unified storage across that is a big benefit. So we'll talk a bit about that. The other thing is around the exponential data growth. So depending on where you're at in your life cycle, you may need more or less compute and
being able to flex up. Uh maybe in a cloud like way is definitely something that is uh a high requirement for a lot of HPC workloads. Uh So let's talk about some of these trends. A lot of times these workloads are very specific and so you might have isolated applications um and many of them. So in with these different data silos comes complexity when you're trying to scale as well
as s system complexity. When you have multiple applications, a lot of that is being transformed into a more like economically viable flavor that when you're able to consolidate and deal with many workloads with a single platform. And that's what we're here to talk to you guys about today with a unified shared storage data solution.
Prakash is going to talk about some of the benefits of what pure brings to HPC workloads. All right. Um So before we get into the benefits of what PR can actually offer, let me just uh rewind a little bit on the previous 22 previous slides. First of all, I see uh a lot of people in this room. How much associated are you with your HPC environment today?
Uh How closely are you plugged in if you can consider or you think about your HPC workload? What is the first thing that comes to your mind in your day to day job? It is connecting with HPC workload for your business applications that you're running or even for the infrastructure part that actually stays in your data centers or even moving to
cloud? What is the first thing that comes to? Do you think the HPC workload is slowly moving to cloud in your environment or it's still sitting in the data center data center? OK, great. Now in the data center today is is the compute that you're running. Is it got a massive scale already? Or your computer is obviously under control but
your storage or the capacity for your data, that is another challenge that you're noticing in your data center. What would you actually relate? What is both like you are also the scaling the number of computers that you have in the compute form and also the storage that is supporting all your data that has been generated during your application uh workflow. Is it all,
does it scale independently or they're all tied to each other? That that's the question independently. So I think the dis aggregation of computer and storage is very, very important because data has gravity as you start to scale with number of applications as well as the number of workloads that you're running, the projects that you're running in
the in the top layer, you are going to be generating a lot of data. Now, in this presentation, I have only, I'm talking about one of the HPC workloads which is called semiconductor design now because today A I and semiconductors are exploding everywhere. So and both of them are HPC workloads by the way, because if you look into A I workloads, they are HPC,
the amount of data that has been ingested and the amount of training and machine learning that happens from the data that has been accumulated. The same thing happens in in in semiconductors because there is new data that is generated. So for an A I, you already have a stream of data coming in real time or you already have the data that you would like to build some intelligence on top of that or you can go out
and look into a semiconductor industry where you can actually have may maybe starting with a project at a very small data size. But as the project starts to progress in the next coming weeks and months, the size of data kind of explodes, it really goes very, very high because it generates into a high file count environment. Why am I talking all of these things? First thing we have already seen industry
services coming out when you talk about HP number one, they talk about performance. Now you tell me is your storage capable of handling my parallel or synchronous or what do you call the concurrent I OS that I'm sending from my application level is your storage capable of handling it. Number one performance,
number two cost. So cost is another thing which is really hurting customers. The thing that we don't want, I literally came down from an A PG trip where I met a bunch of HPC customers over there and they go, yeah, we've been using GP FS for a very, very long time. We want to move away from in.
We would like to use Ethernet, but I, we take your value of what do you call whatever you're saying, saying that your performance will be better. We'll be testing it out. What about cost? Now when you look into those cost factors, the first thing comes into mind, customer says, how would I actually relate performance per rack space?
Because you all agree. This is all going to be inside your data center right now if I were to buy more storage, how do I be more green? That is what you saw in the previous slide. It's all about economics and green technology. That is where P storage comes in apart from the performance because I don't have any performance slides, we can take it offline if you're more interested to know what performance
numbers look like. I have got some sample testing which we have already done from benchmarking tools like specs storage 2020. We are doing stack M three is an ongoing process for financial high performance computing data. We are also doing 500 dot org which is another benchmarking tool for high performance. So a lot of these things are work in progress.
We will be able to share all of the data moving forward under NDA but stack three will be audited. So if anybody from the financial sector in the room who would like to know what we are doing with stack M three, that will be audited and will be public. We decide to publish or not publicly, but it will be audited by the stack committee.
OK. So going back to the next slide. So what exactly um what exactly uh purist providing pure is providing first of all the acceleration, the speed, the performance that we talked about right now, the job development. So there are certain workloads which are going to be cutting in horizontally in your entire HPC workflow.
Number one software development, you talk about any new business today, there will be some amount of software development in some capacity that is not changing. Actually it is getting bigger and bigger over the year because you talk about A I, you talk about, talk about analytics. There would be end users or data scientists who would be actually writing applications either
containerizing it or it could be running in a modular form in some way and they will be a version control management, either a GIT or a perform depending on the of industry that you are looking into. But there will be a software version control management tool that has been used. There would be a binary package manager like AJ four got factory that has been used because you have got your source code,
you are compiling it, you have got to package it. It's a binary, that's the binary. Is that what you're going to be using it? So you got to store and manage the binary. So that is where the software development ecosystem comes in. The tools that you'll be using. And pure storage has got some really compelling value to provide to customers who are using per
and J factor which I will be covering later in this presentation. Now, the argument would be what about get we are getting there. We did some initial testing on our first generation platform, did not really good score, did not score too much brownie points on that one. I would admit. But I think with the new technology and new
platform, we are getting better and we will be seeing much better results. I'm expecting, I'm completely hopeful because we know exactly where we failed in our first generation platform. So with the new generation platform and the changes in the hardware and the speed that we have, we have got, we will be making a big difference and we will be having those results by the end of this year.
So this is an ongoing process as to start to validate a lot of these things moving forward. Then the other thing that I was asking about cloud now I say cloud, but there's a term called flexible hybrid cloud. The reason why I call hybrid cloud because a lot of customers do not want to move entirely into public cloud. And specifically, we are more commercial in
nature. I'll talk about semiconductors right now in semiconductors. They will say I have got my intellectual property. I I don't want to go into cloud because there is a legal frame that I have to go through my legal process process, which will not allow me to move my data into cloud.
So I cannot go purely into cloud. Number one, number two, I don't know where my data will end up. When you go into cloud, I be sitting somewhere in the US or could be sitting somewhere in some other region. Ge ge ge ge geographical region. So it is very difficult to identify the location of the locality of the data.
So the data serenity is very, very big is a big question about when you're running a business in the cloud. So what we are providing is a way to actually move your data to a Colo which can connect to the cloud provider. And that is where multi cloud comes in. You are saying, OK, I've got affiliation with a WS I work with a Azure.
You work with Google Cloud. Doesn't matter. We could be sitting in an Equinox location where we can connect to any of the cloud vendors depending upon what agreement you have with the cloud provider. You absolutely. Data is available that is called data just in a cloud adjacent. You are getting your data.
And the big part is this is a hardware setting. You don't have to own the gear. You'll be thinking, ok, I have to buy the gear, move it to the. Now we do everything for you. All you need to do is to say you have to pay as you consume. You probably would have heard about our Evergreen technology,
right? Evergreen subscription model, we apply that in the cloud. We have got customers who are getting ready to run PO CS to move into that flexible cloud hybrid cloud model. Then obviously the RO I the DRR, I literally got a customer who is buying, we're going through a POC and once the POC was great and we got some great numbers and they
obviously did not disclose the competition they were testing on, but they were very happy with the numbers. Then they go, what is the DRR, what is the data reduction ratio? And I had to go scan into some of the production system from our other customers, obviously anonymize them, not going to call them out the names and provide them this is a
standard or an average DRR that we are noticing. And again, it depends upon what kind of a workload you're running, what data set. I just can't put a finger on it saying that you are going to get 2 to 1 all the time. No, but on an average, I could say it is two is to one. Now on our older platform, the first generation flash blade because this is all about HPC
unstructured data. So flash comes into the picture big time, right? So it's not that we cannot use flash array or flash array files, but it's just that the scalability that is needed for the HPC workload flash fits in really well, right? So that's when we actually come and say where is the data reduction?
So in the newer platforms, you can get a better data reduction compared to the first generation. So when these add up to the overall cost, that actually makes a lot of sense. And considering the fact that our form factor is a five view, the flash played s compared to any of our competition today, depending on they're going a single chassis or a multi chassis,
you are still going to be saving a lot of room from a performance for a rack space capacity. So that is another reason why I think we are going to be a much of a favorite in high performance computing. The fact that it is not the scalability, not the disaggregated of compute versus storage, which are very important points. But the cost from a business owner perspective, how do you actually drive lower cost?
It is not the startup cost but also the running cost. The RO I and then finally, what do you call integrations and observable? Because everybody was every storage vendor has their own way of actually monitoring and reporting stuff. We have pr one which is great, fantastic. But all of our competition also have their own
way of actually monitoring reporting. A lot of our customers are asking for us. Ok, give us a standard API where I can plug it into a Prometheus or a graph or equal to something like that, which is going to be one single pane of management. And I don't have to go through a learning curve understanding what your offering is. So that is, that's where we also provide an open API which can actually connect from the
flash array and flash play directly into Prometheus. And that's where you can put your design, your graph or dashboards accordingly based on what you requirements are. We do have sample dashboards as well as um permit settings like alerts and all of that in our github location. You can absolutely consume that and you can actually customize it based on your requirement.
But there is a good starting point that you can have with all of the dashboards, we are having already available in our github location. Now let's look into the flow. As I said, this presentation will focus primarily on the semiconductor side. And if you look at the flow on the top, what do you notice here and look at the color coding, the yellow and the red,
the yellow is where the software pipelines are, right? And I said the software pipelines is indigenous to any kind of a vertical or an H BC workload that you're running. This is completely plugged into whatever workload you're doing. Software development is a core component just like A I is making, making more is becoming more and more mainstream today.
Exactly the same thing. Analytics A I software development are the three major areas which actually kind of connects to bigger pipeline. So when you say pipeline before it has now become into an assembly line, that's where I think use the term assembly line because you have got so many different data pipelines that connect to each other to form an assembly line for for a desire outcome.
So if you look at this one and we have got some of our portfolios here, the flash array, flash blade and a flash blade E, right? And when you do the flash array and a flash blade s that is a positioning for performance speed right now, why do I have a flash array? Because I was talking about flash plate is a good fit because when you're running a a software development workload like a force that
has its own database. Now, when you're having a proposed database, that is completely uh what do you call laten sensitive when you're doing a latent sensitive and their way their entire application works, the locking mechanism, the sequence of locks they actually apply when you are making a change to particular database files is sequence in nature is serial.
Actually, when you're doing like one data file is locked in, there are a few other uh processes waiting for that in the queue until that lock is released, you cannot get access and update that particular file. So what happens is when you're doing it over NFS, that takes a very long time and the latency really shoots up so it impacts your overall delivery pipeline.
So you just cannot put NFS or a flash pit for every solution. So that is where we go hybrid. We put the database, the logs, the checkpoints, the journal logs all on flash array, you put the depot and user work areas on flash plate. So that gives you not only the latency capability for the database from perspective,
but it also gives you the ability to scale the user work areas that you're actually going. And for example, if you have got only one depot, probably a flash array, putting everything on a flash array would be a good fit. But if you do have multiple repos, I have got talking to gaming companies or you are talking about all silicon manufacturers. They have got different depots where pro force
is used as a mono repo. That means it's going into one big umbrella under which it is managing multiple repos. In that case, what happens is you need to scale and I've got a lot of customers who are saying, OK, we cannot do any more blocks. We got to move into something more shared infrastructure like NFS because that will give us the ability to scale not the scalability
from an end user perspective for creating work areas but also managing multiple repos at the same time. So that is all about the software part of it. That's the yellow. Now, what you see on the right hand side is all about hardware pipeline. That means you are now designing chips. You have got your analog and digital chips that you're manufacturing,
you're designing the blueprint that you're creating, then you're moving out to a tape out phase where you're actually putting the pushing out the blueprint into manufacturing like a foundry and then final manufacturing happens. So this is AAA compressed version. There are so many sub subdivisions of the process. It is at a high level just to give you an idea of what this entire pipeline looks like.
Now, if you can think about the amount of connections or the or the storage that you need to have on the data, data layer, we could be all standardizing into one standard platform for this all this work flows that you have got your software development for your databases running on a flash array which is obviously purity and then you have got flash blade S which is going providing you the rest of your workload running on it.
Now then you start off your project, your project gets the entire life cycle. Your entire infrastructure is available for the project to complete in a timely manner. Once that is done, what do you do with the data? That is where the data moves to a warm tier like a flash blade. E because that is where you're, you're housing your completed project for a certain amount of
time before you completely move it off to a frozen state, like to a tape or somewhere into cloud. And that is exactly what the life cycle of data is going to be from the start of a project to a warm phase, which is an intermediate phase. And then finally, you just wrap it up for your long term retention and for your compliance and all of
that stuff into tape or into cloud depending on where you would like to. Sometimes people just leave it on desk because I've got a lot of semiconductor companies six months down the road, they would like to go back and say, hey, they, they released this um chip ended up in a bug. There are a lot of news out there with chips have been released and they ended up having
bugs. So they would like to go back to the kind of blueprint that created back in time and they don't want to move the data back again. So if you're sitting on an E, you can access that right away. It supports all the protocols, you probably know all the details about E which has got a very same similar construct is just not as scalable and fast as an S but it provides you
the same protocol capability that you need. And so if you want to have a temporary access for some of the data that you would like to revisit, you can just directly access that for money. So it's all about improving the RO I and decreasing time to the results. The reason why I'm saying time to result, we have literally seen like recently, there was a POC that were completed right here in the Bay
Area um where they ran the POC for almost three months for almost a quarter. And what they did was they did in two phases. The first phase was they ran certain industry strand benchmarking tools to figure out how we are performing. That was the first test we passed that we went to the next one where the customers actually put the real data on it.
So what they said, they obviously didn't disclose the names that they were testing against. So our competition was able to complete seven bills in four hours we completed 15 bills in four hours. So the time to complete those bills if it's 15 of them, imagine the amount of time that we are not only saving from a from a delivery timeline
perspective, but the Ed A or the chip design license tools cost are so high, you are literally saving or optimizing those cost because now you can actually start a new project which used to take 30 weeks. Now you're reducing that to 20 weeks and in the additional 10 weeks that you got you saved, you can start another project. So we are not directly impacting the reducing the cost of license,
but we are optimizing the license cost because by the speed in which we are performing and there is another, you know, what do you call feature, which I'll be talking about later in this presentation that also helps in trying to reduce the overhead on the storage side. I'll talk about that in a moment here. Now, if you look at this entire pipeline right from the source source code,
right on the left hand side, you do the compiles, create your binary packages and go through all your hardware pipelines, simulations, verifications, tape out regressions all of that stuff. When you finally roll out your blueprint and goes to manufacturing, you look at this entire pipeline and they could be sitting on various different platforms. And again, the performance ones,
obviously the flash array and the flash plate for supporting the kind of um what do you call applications you're running? And then the E is an extension to your project. Once the project is over, how do you move the data over to the E so that it can be available as a warm tier or for long term retention? So look at the different nature like what, what what um Calvin was alluding towards in the
beginning of the presentation was is all about integrating workflows instead of data silos, we're integrating workflows together on a standard data platform which gives you the ability because you don't have to move data frequently. You can just have your data volumes over there. There will be other data management capabilities like data production or you want to move it over to an E for long term retention
because that is a capacity tier, it's not a performance tier. So you move from a performance to your capacity tier. That's where your life of your project ends. And then probably it can move to a tier later on if you were to have that in your environment. So now let's look into the part of it where the performance software part comes in.
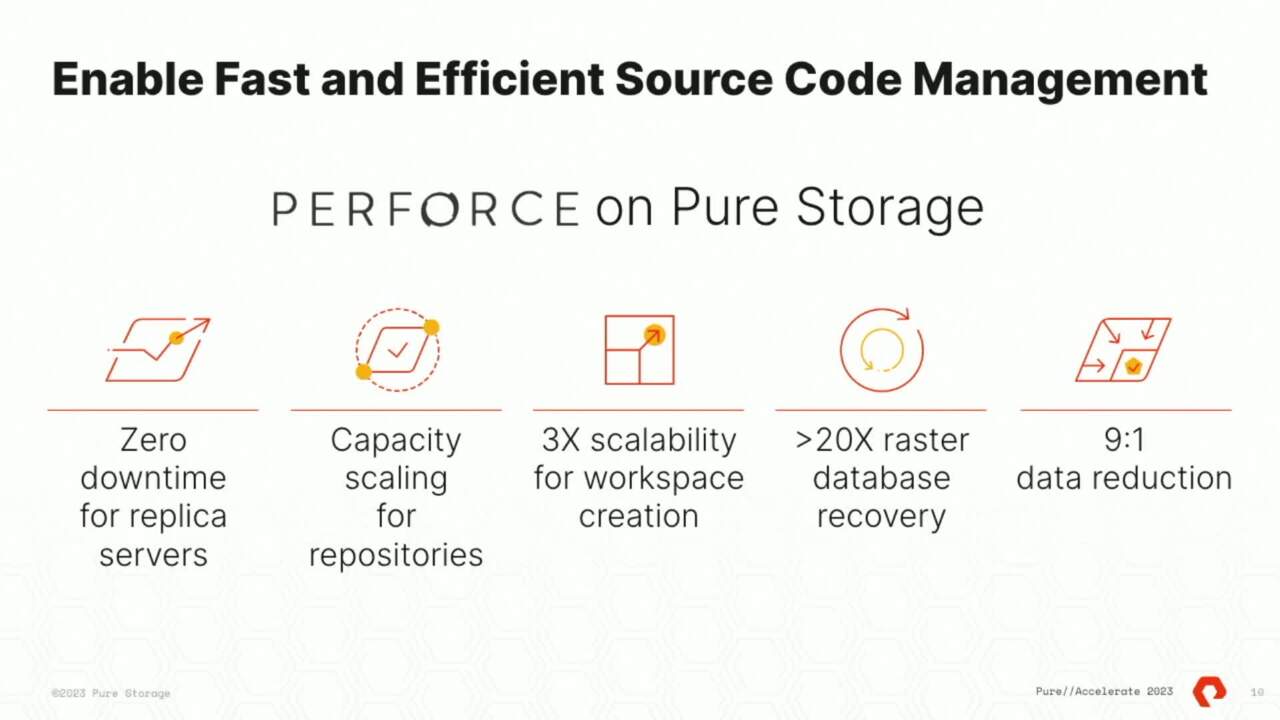
So first of all, what does pure storage provide? First of all, it's zero downtime for replica servers if you anybody in the room uses force in their environment, anyone? All right. So architecture has got some database as well as a replica servers that is basically for load balancing for a high number of reads and rights
coming in. So the ability to actually create those replica servers in a non pr environment is definitely going to be a little bit of a downtime when you're creating those. And that is exactly what actually if you read the documentation that provide that we don't have any down time because we are using cloning capability on flash array to actually clone those instances instantly.
And there is hardly any down time at all. There's zero time down time for that capacity of scaling for repositories. That is where the flash plate comes in. As I was talking about giving an example of repositories, you manage one repository or multiple repositories. Everything could be sitting on a flash plate and there is a shared infrastructure shared mounted of NFS and your clients would be having
access to that directly. Then three XK scalability for workspace creation. That's again flash plate. Now, for example, I was doing some scale test recently on our on our um S 500 which is the top of the line um flash. And I was comparing that with our first
generation. So what we noticed is in the first generation, supposing I were to create 15 work carriers per host per user and I would have like 50 users. So 15 times 50. So I would actually start to break the flash plate or slow down the process when I hit about three users for four users with 15 work areas uh per user.
But when I did that on S 500 I was able to scale much, much higher. So that gives me the flexibility to scale the workload as we start to go with a higher number of users. The other one is the faster data recovery. And that is what we are going to be including later in the presentation because the data recovery is very important.
The reason because um whenever you are actually having a disaster for data recovery, that takes a long time. So if you were to take such a long time for data recovery, how do we actually fit in in the timeline for the delivery process? So that slows down the overall delivery process.
We have got up to 20 X and I have got data to show you that and then about day nine is to one. Actually, it is 24 east to one that's a little old. It's 24 is to one data reduction on flash array because you know flash array, which is where the database is residing has got compression and ded Dulic. So we were able to get about 24 to 1 on a product data.
So that is a huge savings right there. So this is the architecture I was talking about. If you were to look at the, you have got all the major components that are lat and sensitive sitting on a flash array. You have got your database, you have got your journal logs, logs and checkpoints, setting all in flash array.
And here you've got the depot which is the repository and all the work area P four WS stands for workspace. So all of that is located here on the flash plate, but this is the architecture we recommend. Now as I was mentioning customers as well, I don't have that kind of number of depots. I don't have that many number of users. Can I just not use flash array?
Absolutely. You can do that where nothing is stopping you that but when you start to scale, you have to look beyond flash array from a block based us. Thank you very much. So these are some of the numbers I would like to show you here and just to let you know, we were up to 62% faster compared to our NVME, which is the local disk like that is the
customers will always start with the local disk or NVME based storage and says if we start with it in VME, how far we can get? We got a 62% faster and we got 20% faster on flash play. First, there are different operations. We did, we did four sync, sync means you're checking out code and then you're doing a lot of file system operations. Like you are editing the files,
you are making changes to the files, you're submitting those changes, all of that. So just only the sync operations took about 62% faster. And with the submit and update operations was 2020% faster on a flashlight. Now, let's look into the other part. Now the first graph has no replica servers. There is just one commit server when I talk
about replica servers, that means I am actually doing a more load balancing of the IO traffic comes in. Now, that is an offering from Perforce. Perforce. Does that? Now I'm introducing three per four servers, which is replica servers. Technically, then I'm actually doubling. You see the 62% remains the same.
Almost the P four signal that doesn't change. The biggest change is the operations. Now you have got three servers to actually handle your IO operations that actually changes doubles up because I'm adding three replica servers or add servers to the configuration and then the percentage of improvement kind of doubles up. So that is exactly what an indication that how well we can scale as you start to add more
number of servers. This scale also can show on the storage itself. That means how fast we can deliver to those I requests. Now, what is the summary for this basically is the source can be snapshot it. So where are we creating the replicas of the edges? I was mentioning about cloning capability that is a snapshot based technology and flash array.
And that's the reason why you can spin up multiple edge servers very quickly without taking additional space because of cloning and no additional reason. So if you do not use pure storage, we force in the documentation says you have to do it on our sync because that is the down time that we're talking about. So you are building those replica servers as you need for the load balancing that you need
in your environment. If you run it on flash, right? That is completely instantaneous and back up and restore for PP four D. That is a database is quickly using snapshot utility. And I will talk about that in a moment here. And then what is the other thing that we're going to get is the space efficiency.
It's all about 24 is to one data reduction. That's enormous. 24 is to one is the amount of database that you can have. You're gonna have multiple instances of force running. And I have got customers who are actually running more than one instance of reports today in their environment and we actually can deliver that.
Imagine imagine the amount of space savings we can possibly have. And obviously the better management because here you are using, as I said, we will be having this API or an open, open API capability to integrate with any of your um Promes and for monitoring and reporting. So that becomes a single pain of class for your manageability.
Now, for so when I was interviewing customers. I said, ok, uh What happens when you actually have a disaster in the middle of the week? How frequently do you actually take a backup of your data? Because think about this, what is the database? A database is nothing but an index which gives you pointers to the physical location of the version files that you're storing,
right? If you lose your index of your book, then you don't know which page to go to, right? So if the database is gone, you don't have any way of accessing the files that you would like to recover or you want to check out for your own software development, right? So, and I asked them, how frequently do we,
oh, we only do it once a week and then I go, what do you happen? What happens when you, when you actually have a disaster in the middle of the week? Oh, we have general logs. We can replay just like an oracle. We have got redo logs, they've got journal logs. We can replay. But how far do you go in time? Oh, it could be just for 24 hours.
But what happens because you took the snapshot in the Sunday night. So you, oh yeah, there will be data loss. No, no doubt about it because our database is so freaking big. We can't take a snapshot that frequently because that takes a long time. So we put that on a flash plate using snapshot technology is dropped 10 times x faster.
And I'll tell you exactly what technology we are using and we are dropping the restore time from 30 X time. That means we were able to recover and restore the same data set, which took on the traditional force command. 38 minutes took less than one minute for us on the flash array. So that is how we are making that big difference from an adoption perspective because
this is where you save time. So just to get your knowledge about the technology, if you see here, your database is running on a flash plate, what we're doing here is we're creating a protection group called backup folder on a flash blade, which is obviously NFS based. And what we're doing is we are taking a snapshot in that protection group for the
database. If you see the pro force database, that is a DB one and DB two, this is an offline. So this is by default perforce provides the ability to create two database entries in the initial set up. So production is the database one offline is where you can actually take your backups. What we're trying to do is if you go, what do you call the route that their native command?
It takes about in the previous slide. If you see here, it took about 55 minutes to take a snapshot on the checkpoint that's called checkpoint 55 minutes. And we took five minutes. Why? What we did was we took a snapshot of the database, a clash consistent snapshot. What do you do with it?
We did is we quest the database. We rotated the general logs and flush everything to the back and storage. There's a flash and we took a snapshot there. Now what happens is that snapshot is got not only pointers to the metadata but also data, not the standard snapshot that you have only pointed to the metadata, but this is metadata and data. So when you do have a problem with the database,
just to recover that all you need to do is to recover from that snapshot. That is under one minute. As I said, the snapshot has both data and metadata. So that is such instantaneous that you can actually recover from that failure very quickly. And that is the reason why we have something called snap two NFS technology.
It has been provided by flash air for a very long time. So this will still have it is a one time configuration in the environment and you're good to go. So any time you have a disruption for your database, you can recover from your snapshot instantly. So what did we learn from that? So first of all,
we got about 10 X faster. Um And so this this is about accelerating user work area. So that is all we talked about is the flash. Uh what do you call proposed database that we saw. Now when you're starting to scale the number of users, what exactly we are going to be looking at that is where the scale comes in because you
have got 100 users today tomorrow. A few years later, you have got about 500 users, but your database size is also growing. Your number of repositories are also growing. That is where we saw the scalability from a Flasher and flash plate. But how do you handle that many number of developers that are actually accessing that?
Because they will be every time doing A P four sync to check out the car, the source code and making sure they have it already in the work area before they can start computing that on boarding process takes a long time. So what we're trying to do is we are trying to make it run faster with 2.6 is to one data reduction on the flash plate. Keep in mind all the user work area that we are
creating is all sitting on a flash plate. If you go back to the this slide over here from the architecture right here, you see all the performed work spaces sitting on a flash. So that reduction is a 2 to 2.6 is to one from a space reduction perspective. So that is where the cost reduction comes in because we can accommodate more number of users. Um When you're actually scaling the number of developers in your in your space and eliminate
stress from the four servers because we have something called a rapid file tool kit P copy operation which copies the data files from the source repository to the user work carrier and registers that work carrier to the proposed database. Completely. On a flashlight to flash perspective, you do not have to stress the storage servers at all. There is no data going back back and forth from the proposed servers.
Everything is going on handled by the flash. So that that is a a tool that we are offering free of cost. This tool can be configured on, on a Linux box, either a red hat or an ubuntu box. And you can literally use that capability. We can copy the file server without having any traffic going to your perform server. Everything is handled at the the flashlight
level. All right, the other tool is talk about J frog artifact, the J frog artifact. Anybody who is using J Frog in their environment, anybody knows about that. So they are actually a binary package manager. So what we are capable of doing is when you are doing the source code, you modify all the code changes, you build or compile your source code.
Now when you do the compilation and you finally go and put that in the packaging and put that the packages into a binary package manager, that's where the JG artifact comes in. So they are one of the most industry, most popular industry standard binary package managers that are actually available today. And we have been partnering with J Frog for a few from the last few years.
But recently they released something called direct cloud uh download feature. What that means is you can actually push a package into our factory. So writing that doesn't matter, you can write as much number of packages directly in parallel, doesn't matter the problem. Most of the businesses are actually having is their face is downloading the packages when it takes a lot of time to download large packages
like your C packages and all of that, that hurts the business because you can't really move on fast enough. And when you're doing an H BC workload, a lot of them are in C packages which are huge and when your download speed is slow, it really hurts the developers or the end users who are actually using them to move fast enough. So what we have done is we have now configuring an S3 bucket on a flash blade and putting,
pushing all of the packages residing in an S3 bucket and flash blade. And whenever you're trying to download the package, you are not going through the artifact stack, you're downloading it directly from the flash play bucket. That's the feature that J provided. They actually had that feature available in Amazon S3 in the cloud.
They did not have it for on premise they just released it for 7.41 version and older later. So that is where you can actually download that slot more faster. And because it is all flash for us and the bucket is sitting on an all flash platform, it is a four X faster. That's the biggest advantage, 75% reduction because you are now downloading directly from the flashlight.
You're not going through the entire server stack anymore. You are writing it to it. Yes, absolutely. But you are reading it when you're downloading, that means you're reading that package. When you're downloading it, you're directly doing it from the flashlight. So you do not touch any of your J frog servers at all.
Then what happens is you do not have to add more number of servers because as because in the traditional way of doing things is OK. I ran out of capacity. I would like to add more capacity because when you're writing more and more packages, you need to store them. So as you start to scale, what are you going to do?
You're going to add more servers to it because now it is all sitting on flash play, you can scale it because we have thin provision. You can scale as much as you want on the storage on the capacity perspective. So your number of servers needed for the entire setup is reduced considerably. And all your capacity has been now been done on a flash then comes the data cast size.
So whenever you're doing a read, it also does to try to cast them. If you configure the cash on a flash plate because it is over NFS, you not only get a data reduction on the cast size, but also it is free to stretch and grow at because you don't have because normally I think they provide about 150 gig of cash that is at tunable. You can actually grow the size of the cash.
But if the cash is sitting on a flash plate, you literally stretch that anyway, you like because it's all thin provision on the flash plate. So if you have large packages, you do not have to open up. Oh, I ran out of cash space. I need to open up a ticket. None of that thing is done because everything is all going to be handled by the end user.
You need more space. It's all sitting on a flash plate. You can absolutely get it. And then finally, you are done with all of these things you want to replicate or you want to archive it in the cloud. A lot of the customers actually move it over. We have got a replication to AWS S3. You can move all of your old binaries because
we have got something called a recycling of objects. So you enable that on a flash plate, you just move those objects back into Aws through a replication mechanism. So if this is to do a comparison, we did it on a public cloud obviously that is uh aws and S3 and it went from a local SSD. So we did it on flash plate and then we got the
final new feature which is a direct cloud storage download and that was able to give four X faster because as I was saying, this was directly downloading it from the flash plate S3 bucket. And just to give you a diagram here, if you see the users on the right hand side, putting a user download request, it goes through the entire stat to identify where the package resides,
but it gives you a redirection capability. So it is OK. I know where to get it and it finds a location and necessary bucket right there. And you see the direct cloud storage download feature number four, that is where it is getting directly downloaded from the bucket from the on the flash plate. So you do not really have to go through the entire stats.
That means you do not have to make an entire uh stack operation from the flash plate to the artifact stack and back to the end user, you can directly go from there. So what that means is you are stressing less on the J server. That means there are less amount of operations and there's a flash is being offloaded. All of the these operations have been offered to flash plate for the reads that has been
asked. And that's where the major challenge is. The end users are always restricted with the download speeds. And we are actually AJ Frog Arti factory um user at pure storage. And this is actually our story. This is our story and we are a reference to this because this is what we've been using for
our engineers. All right, we talked about software development. Now we look into the hardware side of it. So the biggest challenge I was talking about is performance. If you look at this, we did a performance obviously in no way is now sorry. Our first generation is obviously end of sale right now.
But we do see you have those comparisons is 15 blade, 30 blade, 10 blade s 210 blade s 500. These things are going to change in the future when I have multi chassis numbers available, which will be coming very soon. But as of now, I do have the previous generation and the new generation comparison and there were multiple
different testing we did. And if you see the linearity as you start to add more number of chassis or sorry, more number of blades and change from the first generation to the new generation. It is a linear line moving upwards. And what it means to the end user is like when you're having that amount of speed,
I can actually reduce my turnaround time by 50% what I used to complete in 30 minutes, I can finish it by 15 minutes. And that is a direct comparison why I say direct comparison because we use this benchmarking tools for a certain set of initiators or hosts that we are testing. All we did was changing the end points and kept the load constant.
So when we were running these loads at scale on the different platforms, we really noticed that the newer platforms are completing the jobs a lot more faster, almost cutting 50%. That's a huge enabler for our end users because that is what they are looking for from a speed perspective. How does it translate?
Because when I say performance is better or speed is high, what does it mean to me? So that's where the 50% reduction makes a big, big difference. And that is what our customers are noticing too. That's the example I told you about um the bills that we did from seven bills in four hours to 15 bills in four hours.
That's a two X improvement, right? And the same thing is the regressions when you're doing tape outs that also reduced to 15% for a 50% reason. When you're doing regressions, you are actually recycling a lot of your data, you're deleting a lot of data.
Now we have this capability called fast remove. Anybody know about this feature and flashlight fast remove will literally use this and customers use it. They said it is so fast R dash RF takes forever to finish for the volume of data that they will be deleting the number of files. They just do this at the background by doing the fast move feature and then immediately they
can start another regression in the front end. So that is where they're actually seeing a huge reduction in the time it takes for running the multiple regression tests they will be running because every design will have a set of regression tests, they will have to comply to complete successfully before they can actually tape out. And that's the reason why it is very important
that they finish those things a lot more faster because their deadline is how are they are responsible for the deadline of the tape out if that extends any time further, they are liable or they are being accountable for that. And that's a very, very important from a business perspective. Yeah, we do this great speed and speed and everything.
But how does it actually help the end user? That's very important. And if you just were to map this from a latency to IR perspective, now keep in mind in HPC, there are various different types of HPC workloads. One is IOP based which is small files, high metadata and there is bandwidth base you a large files, not many of them, a few of them, but there are large files that you are
constantly doing parallel operations at the on the same file back and forth. So if you were to look at a latency to IOP curve and a comparison between the different generation, the first generation and the next generation, you will clearly see the amount of number of I ops we have been getting. And this is again, a single chassis, multi chassis will have a different number than single chassis.
And then we've got a two X improvement 2.2 X and 30 75% more. And then when you do a latency throughput, again, the same benefit, we see about three X improvement from our first generation to the S 500. And between the S 200 the S 405 100 we get about 40% improvement in the bandwidth. And again, every iteration of purity that we are releasing,
we are optimizing the performance. So you will be seeing much better numbers as we move forward. Now, this is another slide which I was trying to talk about is we do have an ability to make the schedulers smart enough. So they would know if there is a storage resource available for the jobs that they're submitting. And that is where it is important for us to
know that you are optimizing your ed license cost. Because if whenever you are using a particular job or submitting a job in the queue, there is a license that is stacked to that particular operation. So if your storage is already saturated and your jobs are going to run slow or fail, and that is going to be detrimental on the overall, not only the cost for that business
for the project, but also for the overall delivery timeline. Because if you are failing the job, but the jobs are running slower and you have to resubmit the jobs all over again. So by running this simple API command from the scheduler, you can determine whether you can actually um optimize your storage resource effectively. So that is a huge benefit.
And this is something our customer is running today in production. And this particular piece of food that you see here has been provided by our customer. So this is something which is really making the schedule a lot more smarter because now it's becoming storage of air. So just to summarize the entire day of life, the cycle from a fast platform,
which is s for all the entire workflow that you see. Um the post challenges that you noticed because after the project is obviously done, your data is sitting idle there. What happens to that. So how do I uh until before we launched e that was the biggest challenge which we had a lot of our customers asking, hey, I can't be using my flash for our idle project sitting over there
and forever we have to move those over and you don't have another tier of storage, which I can move otherwise unless I have to go to another competitor of yours. But now we have an answer for that. And this is where the entire life cycle looks like from an S to an E to another tape, which is called call data, right?
This is where the entire life cycle looks like when you are from a performance tier to an archive tier to finally take. So we do have an ability of moving data today by direct by directional uh replication. But that is at the file system level. What happens if you would like to choose to move certain directory or files? We have a host space called rapid file tool kit,
which I mentioned about a solution and reports that is also capable of moving data independent files or directories that you choose to do that. Um We get about a gig of a speed between an E between S and E or E and S depending upon which direction you are moving the files. But one gig of speed, we can literally see that and we're hitting that consistently either way.
So just to give you an overview is more about moving your active projects to to a warmer tier where you can have less frequency of use and then obviously move data after a project completion and archiving it, either you archive it in all flash or you move it to cloud or a tape depending on what your business requirements are. And just to summarize this, we, we have the entire portfolio today to support all the
different HPC workload requirements today depending because, as I said, in the beginning, we, we for this presentation, we're focusing on the semiconductor side. But again, it depends what kind of an HPC workload is we have that ability to today today. In the keynotes, you probably have heard about fa files, you can actually have a smaller size because if you
don't want a bigger size like FF pe, you can obviously go with an FA E which has got a file support too. So we have a much more different capacity available right now so that can cater different needs for H BC workloads. All right. I think I've run all the time, but I'm open for any questions.
HPC workloads, including software development and semiconductor design (EDA), are challenged to meet razor-thin margins and shrink product pipeline cycles. Learn how disaggregated storage with high performance and capacity-optimized options can enhance the performance of RTL source code and binaries and still keep costs down. See how development tools, such as Perforce and JFrog Artifactory, can gain a significant performance and efficiency boost.
We Also Recommend...
Personalize for Me