Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Dismiss
The Everpure Advantage
Thrive through volatility
Stop absorbing volatility. With efficiency and predictability built in, you stay in control.
47:48 Webinar
DirectFlash Deep Dive
Get an up-close look at Everpure DirectFlash and find out why this technology differentiates Pure from the rest of the industry.
This webinar first aired on June 14, 2023
Click to View Transcript
Um I see a few more people coming in but we'll go ahead and get started. I hope, you know where you are and you came for a reason. So we're going to talk about direct flash. Um My name is Pete Kirkpatrick. I'm the chief architect for platforms and we have Harry here as well with my mic turned off. Hi, Harry.
Uh I work on uh platform architecture at pure and both of us have been working on this technology for a long time. So we're gonna take you into it. Not as long as her. That's exactly right. This is Grace Hopper um Fire. So there's a bit of Photoshop going on here.
She used to do a demonstration of what a nanosecond looks like and for electronics people, nanosecond has a distance. And so, but we called our board. This is one of our DF MS, just the board inside and we called it Hopper in her honor. So I thought it was kind of cool to show them together even though um unfortunately,
she has passed and that's not real. It's not a I though it's good old fashioned Photoshop. OK. So I said we've been at this for, for a long time, this is a kind of a 10 year view. And, you know, from the beginning when it was just kind of a concept,
we had a lot of other things going on at pure and we thought this concept was cool, but we actually decided not to jump on it immediately. And our founder cause has been quoted as saying, you know, we should have jumped on it right away, but we really did a good job of all the things we did do. And I kind of like this pace of being able to
say, you know, there's a lot of technology that we have concepts in the hopper and we're always evaluating what's important and what's going to bring value. And I think we did a good job of creating the value but the arrays that this went into. So in 2017, when we actually launched direct flash technology and the product was the flash array X that went into a product that was designed back in this time frame and then it
went in seamlessly and it was available with non disruptive upgrades just like everything else we do. And so having these things coming and thinking ahead to how they're going to fit into Evergreen and a portfolio that's always evolving forward and backward compatible. It takes a strategy that spans this kind of time frame.
So that was kind of in the beginning pretty quickly after that, everybody knows you need a shelf. And so this was the, the first shelf that we made and the cool thing there was that included uh NVME over NVME over Rocky. And so that was really new back then. This was a little bit of a stretch and it was a little bit weird.
And now I think everybody understands how NVME over fabrics is a, is a key protocol, key part of the infrastructure. But that got us started on some of the protocols journey as well. Um So then uh the next thing we did, you kind of see the drives across the top and the platforms they enabled across the bottom.
So flash AC was able to, to have QLC and back then that was a bit weird. And so some of these things when we did them were a bit cutting edge. Fortunately now they seem like obvious choices. Um So we were the first to do QLC in the enterprise. Um We brought our history of quality and innovation to, to bring that to market in a way that didn't have compromise.
We didn't have to say you're going to accept a higher failure rate or anything like that, we can bring it with, with good quality. And we're continuing to do that. Um 2021 there, the, the innovation was to include the NV RAM functionality that's in every one of our arrays, but to include it in the drive.
So in flash ray XL, it was no longer a need for a dedicated NV Ram, which can be uh another component to fail. It can be a bandwidth bottleneck. All sorts of problems arise from having a dedicated NV Ram. And so that was a good innovation there. A lot of these things came and enabled some new product.
But our overall strategy is generally to then collapse everything again and say, you know what ad F MD was a special thing back in 2021. Now, everything we do is AD F MD. And so we can keep the architecture evolving with all of these new capabilities. And then of course, today we were able to announce the 1st 75 terabyte drive in the
industry. We have one of them sitting over here, some of you may have seen it, some of you may have seen Shaq holding this thing, which was kind of cool. Um He's probably not used to dealing with stuff like this, but it was uh he's a friendly guy. And so we've been able to do all of this 10
years in this exact form factor, everything's been form factor compatible, you can swap things in and out. And so that's also been a nice advantage and some of the claims you've seen us make about how big they'll get this won't change. So this is one of the ways we can keep that consistent through the portfolio and much longer than 10 years worth of time. So there you have it,
it's real. Um these drives are enabling the newest products which are both flash blade and flash ray, E, of course, E for efficiency. And today I think both of us will really talk about efficiency because the core of this technology is efficiency and it turns into things like performance, reliability, power saving,
things like that. But let's keep that in mind as a theme as we go through a lot of the details. OK, same kind of products. But here I wanted to arrange them in a little bit of a way that you could understand that that flexibility we've created. So most of you will know that we have two main platforms, they each have variants.
But the flash array is our scale up block and file platform. And Flash blade is our scale out file and object platform. Those are two fundamentally different architectures. But the more you look into these designs and architectures, the more you'll find in common between them, the obvious differences are you know, the the the scale up versus scale out and,
and some of the feature set. But underneath we want a very consistent experience, we want a consistent view of of how they operate. And now with flash flash blade s we have a unified set of components including direct flash that go into these as a customer. You may not really care about that. But underneath what's happening is,
our engineering team is focused on a smaller set of things to worry about fixed bugs. The field is finding those bugs in a smaller set of units. And so that really turns into quality for, that's why you should care as a customer. And at the same time, our operations can be efficient and so sparing and all of these things can be in common.
When we show it on this view, it's kind of a two D 3D view depending on how you look at it. But I optimize, I try to highlight how we can optimize for different technical aspects using the same direct flash technology. So on the top, you have our our latency optimized cases on the right, you have flash blade where we're really chasing really high throughput in our scale out system
and that's going to continue to grow. And then at the bottom, you have our family of more cost and capacity optimized systems. Each of these are kind of, you know, there's a few specs up there. Those are really trying to highlight that's what these systems are really good at. So it's not the same consistency of specs across everything.
But if you're worried about um you know, power efficiency, you should be down here somewhere. If you're worried about latency, you should be up there. And if you're worried about throughput, again, we can cover this entire space with the same core flash architecture and leverage that commonality through the rest of the portfolio. So today, uh again, this is one of our newest generations of drives.
Um This is a hopper. Um We have both QLC and TLC versions. So we're refreshing the whole product line and these are some of the highlights. Um biggest drives, you know, people talk about these kind of scale drives for us. These are just going to be production mainstream everyday things.
And so we don't mess around with big claims. This is all very real energy efficiency and we're going to come back to this again. But that has become critical. It's always been important and in a lot of environments, it's become absolutely critical. If you want to put a new data center in Ireland these days, it better have zero power because there's no power left in Ireland for data centers.
That's an extreme case where you're really up against the wall. But it's true everywhere just in terms of carbon environmental concerns, everything else that's associated with it. It's really important to be able to deliver more performance, more capacity, everything you need out of storage, but to do it with a smaller energy
footprint. And then of course time marches on, right. So we always need bigger capacity. And I mentioned the distributed NV ram capability from the last generation where we use that only in certain products and now where it's in every product, we decided that's one area where we wanted to increase the capacity of the MV Ram as well as
its performance. And so again, these are the highlights but it's illustrative of kind of what we've been doing in the, in the latest generation, everything is improving. OK. So what we, that, that's all very high level stuff. That's kind of why we're here and how it fits
in. But we really wanted to give you a better view about how this works and really what are the benefits that derive from this architecture. And so fundamentally direct flash is different than the traditional SSD architecture that you've seen elsewhere in the industry. The basics of direct flash are that we've separated what's normally included in,
in the SSD. And we've taken a lot of that functionality out of the SSD and elevated it to software. Um Sometimes people talk about the, the desire to offload things and in this case, it's actually the opposite and a lot of benefits come out of this. Um the drives themselves uh direct is for directly mapped.
And what that means is it's, it's physically addressed by software. So software wants to do an IO software knows the block, the dye the page exactly which bit of NAD those bits are going to land on and then it addresses it a priority um that enables us to eliminate a ton of the infrastructure that's in the SSD. A lot of the functionality that comes along
with it. Harry is going to expand on some of this. So I won't give you the whole story. But those eliminating those functionalities lead to these drives being vastly more reliable than regular, regular SSD. And of course much, much more reliable than a hard drive.
So the simplicity that comes from this, the simplicity of the module level turns into a serious amount of reliability, not having a lot of that infrastructure, not having a huge dependency on D ram is going to allow us to achieve the road map that you may have seen that shows that we're going to get to very, very large modules as well.
Those things go together, you can't have very large modules. If you don't have very high reliability, you can't have a big blast radius unless it's reliable. So those things are going to go together to allow us to scale the lack of garbage collection that's going on with directly mapped, there's no garbage, so there's no garbage collection down in the drive.
So software knows exactly what to expect in terms of performance at every moment that turns into higher performance in several ways. Again, Harry is going to expand on that. But these are kind of the high line benefits that we're going to dive into in the rest of the talk. And then again, efficiency, to me, all of this is efficiency. Every one of these things either derives from
efficiency or creates more efficiency in the product or in the infrastructure. Um But here we're talking about specifically a drive that we make with this, this many NAN chips turns out to be 75 terabytes. I should, I should try a different analogy because nobody else is going to be able to produce this. There's too much dependence on D ram for
anybody else to make this drive of 75 terabytes. So you won't see it, say 30 terabyte drive for example, which does exist in the market, a 30 terabyte SSD with a traditional architecture requires about 32 gigabytes of D ram to hold the indirection table or the map. We don't have that. And so we're able to expose all of the flash,
not only make it bigger, but then expose all of the flash inside to give you more bits basically. And then energy efficiency we mentioned and we'll dive more into more bits with lower power just turns into energy efficiency. And we want to just keep extending that as we go down through our road map. So from here, I'm gonna hand it over to Harry and uh he'll tell you a little bit more about
how the internals work. Cool. Thanks Pete. So hopefully what you've taken from the talk so far is that direct flash really is a fundamental ethos, right? All of our products are built upon this architecture. So I know we've spent a lot of time talking about energy efficiency. Like the keynote, we spoke a ton about the
large capacities et cetera. But it's beyond just the flash ray E and flash blade E, it's what enables these high levels of performance like direct flash is the reason that we're able to ship all QLC at extremely high throughput on some of our systems like flash plate. S previously QLC had been thought of as this
really hard to use media which was really slow. But it's because of direct flash that we're able to make, take full advantage of all of the parallelism that the ND has to offer without requiring any other type of decoupling media like bespoke media like SCM or et cetera in the middle. So Pete ran over a bunch of the uh bunch of the key features that direct flash enables, right? It, it gives us density,
it gives us performance efficiency, reliability. So let's walk through each of these in turn. So from a from a density perspective, direct flash differs from SSD in two key factors. One is breaking ad ram barrier as Pete alluded to a a traditional SSD um requires a ton of Dr Am. Uh it requires a ton of DRM to map between logical addresses that it received from the
operating system to physical addresses locally. And this is because operating systems send out uh data in four kilobyte chunks. So those chunks internally to an SSD need to get mapped to a geometry that's more amenable to ND. Now, NAN has written the granule of what's called as a page. Now, the page might be 16 kilobytes or 32
kilobytes depending upon the implementation. So there has to be some sort of a decoupling buffer that maps these four kilobyte chunks to these larger chunks. And that in SSD parlance is called as an indirection unit. So there's an amount of DRM that has to be spent towards this indirection unit.
And as Pete mentioned, that's roughly a gigabyte for every terabyte. So 16 terabyte drive would have 16 gigabytes of DRM. Now, if you've been following commodity pricing, you'll note that NAN has declined in price over the last 10 years, but D Ram has roughly remained flat. You know, it's within a certain zone and hasn't changed much.
So as you project forwards, you, you, your bomb cost, your bill of material cost is increasingly getting anchored down by this uh cost of D Ram, which is an, which is an inhibiting factor in building larger and larger drives because that doesn't scale, right? Can you imagine 64 gigabytes of DRM on an SSD? That's almost as much D ram as a server has.
Um So there's no way that that flies, right? So that's a fundamental reason as to why S SDS don't really scale commercially when, when we're talking about large capacity, a second piece has to do with over provisioning within the SSD. So I mentioned that S sds uh get, get rights that are smaller than the pages at which they have to program. So obviously, you need a small area where you
can set aside those rights and you can combine them into larger chunks that then get written into a flash native type of uh in a flash native size. Um And that is referred to as over provisioning, that over provisioning can be as large as 20% of the drive. So for the same number of bits down on an SSD, the same number of chips, uh A traditional SSD could have as much as 20% lower capacity than
AD FM that we build. So if you contrast the picture of the SSD on the left with what we do on the right. As Pete's mentioned, our purity operating system manages all of the land across the system. So we're making globally aware decisions as far as scheduling, we're making globally aware decisions as far as mapping,
we're taking data that lives together from common provenance. We're packaging that together and we're writing it out efficiently in flash native formats. So because of that, we have no mapping tables on the drives and we have no over provisioning of the land. So all the bits are made accessible to the end application. So this is a fundamental reason as to why we're
able to scale to these large drives. Because if you think about it, I mean, yes, our drive is a is, is an amazing engineering marvel, but the hardware piece itself is not the magic like anybody can build a PC B and slap a bunch of drives on it. It's really the combing of the hardware and software that we co designed together. It's the fact that we have direct flash built
into our operating system which allows us to take advantage of all of the bits that are made available. It doesn't anchor us down with additional D ram costs. And as you'll soon see, that's what enables reliability and performance, et cetera. OK. So this capacity advantage directly um manifests in the, in the scale of the larger drives that we're building.
So we've announced 75 terabyte QLC drives and 36 terabyte um TLC drives. And as you can see going further out, um our, well, our ambitions are perfectly clear. We're looking to double that capacity and double it again. So over the next 2 to 3 years, you'll be seeing us come out with as large as 300 bytes of on a single drive. So on some of our systems like flash array or
Excel or flash plate, s, we're talking as much as 12 petabytes within a single box, which is five rack units. Let's think about that. A rack could have of the order of 50 to 60 petabytes and a single box has as much as 12 petabytes. And all of this is made possible because of our investments in direct flash technology.
I know the, well, I guess before we jump to this point. One more point that I wanted to make on the previous slide is that these capacity um enhancements directly map to energy efficiency as well. So the larger of the drive that we're able to build, the more energy efficient we're able to get because you don't invest additional power in building a drive,
so you're able to deliver many more terabytes for the same wattage. All right. So let's talk about performance. We mentioned previously that there is over provisioning within the drive. So there's a buffer that's set aside where these small rights get combined and then they eventually get written out to more flash native formats.
So that in SSD parlance is referred to as right amplification. Now, the land itself has a finite endurance or a finite number of times that you can write to it before it breaks down. If you look at the evolution of flash, we went from SLC, which is one bit per cell all the way up to QLC more recently,
which is four bits per cell. So we've quadrupled the density, we've quadrupled the number of bits that we can store within a single, within the same real estate. On the flip side, the endurance uh properties have declined by an order of 100. So while, while previously on SLC, you could write to SL say 100,000 times or so,
you're lucky if you get 1000 rights on QLC scientifically put the crapps of the land is scaling much faster than the rate of increase in density, right. So there's obviously much more work that needs to go into making these systems function and function well, and that directly correlates with right amplification.
Now, if you, if you have a drive with over provisioning and you're constantly overwriting stuff in the background, you're chewing away um these, these cycles which cannot be made available to the application More than that, you're also doing a bunch of background work which ends up colliding with front end operations. So that becomes a scheduling nightmare.
It's very common on traditional S sds for reads to stall out because they're, they're blocked at a non chip because there's some background operation that's happening and the user application has no insight into this. So because of our P OS and our investments in direct flash, our right amplification is significantly lower than what you would get out with traditional S
sds and that provides us a direct correlation to increasing our performance. We made the point previously about energy efficiency. So this is an analog to our capacity scaling slide. You can see that as we go further out as we look at going from 75 to 1 53 hundreds, the gap between what purity can enable via, via direct flash versus traditional SSD based all
flash arrays or even hard drives keeps expanding. So also note the hard drive line looks like it's flat, but it actually isn't hard drive manufacturers are adding capacity to drives. It's just at a much, much slower cadence than we're looking at, which is why the line looks flat. It's all relative,
right? But we're looking at doubling, whereas they're looking at adding two terabytes every couple of years or so, which for an order of magnitude, that's like less than it's probably 5 to 10% of the drive. Right. So we think we're somewhere over here, we're 2 to 5 X better than competing all flash solutions and the gap is just set to expand.
So think about this for a fixed power budget, the amount of capacity you're going to be able to add to your data center is increasing exponentially. And when you go to 75 to 1 50 for about roughly the similar power on you're getting twice the density and then you double again once we go to the larger DF MS. So this is a key tenet to our improving our environmental efficiency and providing the the
ability to have more infrastructure in a smaller footprint. And let let's next talk about reliability. So Pete made the point that direct flash modules are much more reliable than uh traditional S sds. And it's a combination of multiple factors. And one of it is simplicity because we have a single, we have a single operator for the flash, which is our purity OS we're able to explicitly
manage the functions performed by the drive, the order in which they're performed. We're also performing fewer functions as you saw previously. Like we have much less right amplification. So we're subjecting the drive to much less we for a given application bandwidth puts far less stress on the drive. In addition to all of that, we've also invested heavily in telemetry.
So our drivers are constantly phoning back and giving us valuable information on how the land is behaving, how NAND is aging. What sort of lower level details that we need to worry about? Such as what voltage levels should we be reading these cells at? How frequently should we be refreshing them, et cetera, which allows us to adapt to ever changing conditions.
This is really, really hard to do if you're just slapping together a bunch of S sds because it's often hard enough for the systems aggregator to figure out what and whose S SDS they put together what firmer they're running, figure out what firmer upgrades are available, map that to drive to uh systems that they're managing and, and get those up to sync. Whereas since everything is under the purity
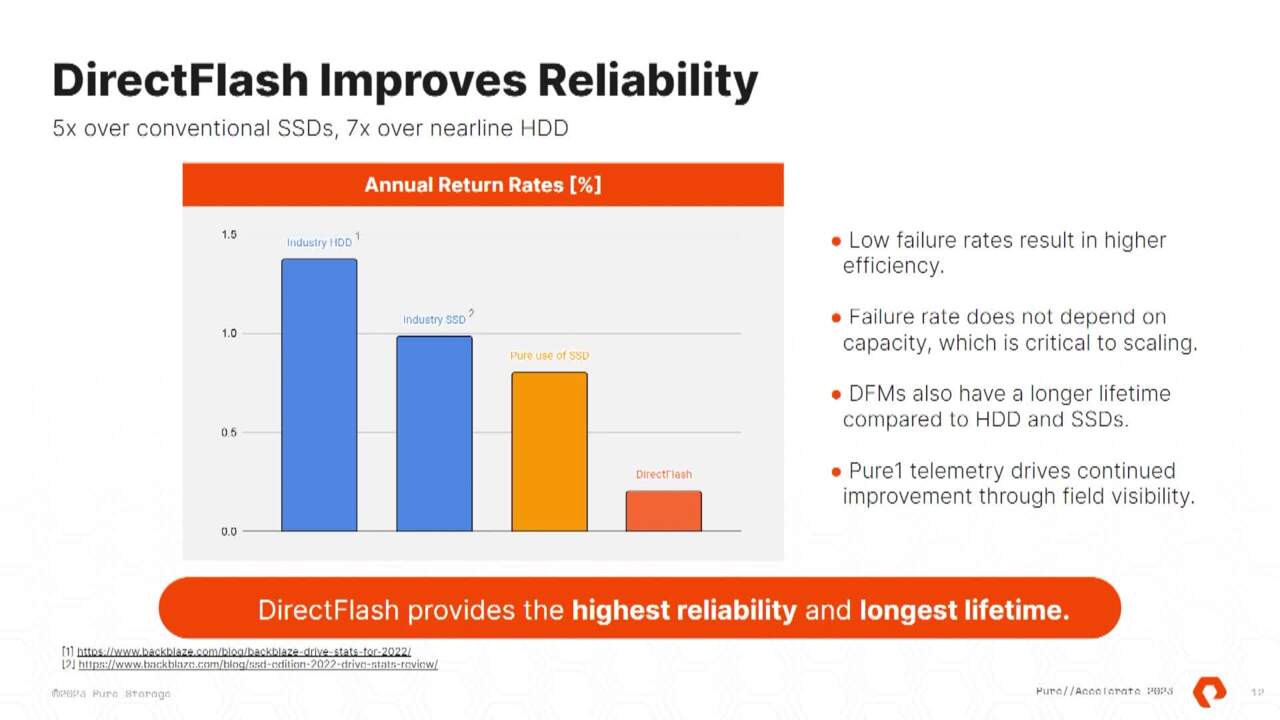
umbrella, since we're always collecting telemetry, we're always aware of what drives are and what systems and what sort of firmer they need to be running and, and we're able to take proactive measures if any are required. So the co the confluence of all of these allow us to significantly drop our failure rates relative to the industry, which is why while the industry,
hard drives and SDS are hovering at the 1 to 1.5% you'll see that we're down in the 0.15 to 0.2%. The other thing to note is that failure rates don't scale with capacity because we don't return and drive if you fail a cell, right? We we our purity operating system is is able to build around no level failures. So the only events that would cause a uh return
would be fundamental component level failures such as the the PC I link is broken or a capacitor is broken, et cetera. And those don't scale linear with capacity. So this is a fundamental enabling factor in our ability to build these large drives. Pete mentioned the point of blast radios, right?
So the larger the drive you build, obviously we want to be cognizant of what happens in the event of a failure. And these technologies and our investment in smart erasure codes and and and system level monitoring are what allow us to build these really, really large systems. So I'll give it back to Pete to collect all of this together.
Oops, sorry, try to be a little bit. The trend is clear. This is this is the same chart you saw before, but in blue now I included the the hard drive road map as well. And so if you think about where we've been a few years ago.
Nobody can remember this long ago, like three or four years, right. But at that time, you know, we were comparable in size, you know, we were a little bit bigger but we, you know, we were comparable in size to the biggest hard drive, something like this, you know, within the same. It's, it's notable because that's kind of a
tipping point right after that tipping point, things will get better and better and better. Now, if you fast forward to now, we're really looking like we're ahead in the game. This is our 75 terabyte drive, but the future is just going to start to look ridiculous. So the way that physically manifests in systems is extreme density,
extreme power efficiency, again, efficiency in kind of every possible way. So there's a lot of factors that go into this. This is just the capacity. Basically, every aspect of what folks care about with storage has been better with S sds, especially we think with direct flash except cost. So the last 15 years of history has been, yeah, we really would like to replace such and such
workload where I use hard drives today, but I can't afford to. Well, 15 years ago, there were some very exotic high performance workloads that people could afford to. And in fact, if they made that change, they could enhance their business and get more transactions done or have better response times whatever it is, that's been true. Every month for the last 15 years,
there's been one new workload that justified and kind of crossed over to become better on flash than it was on hard drives. And when people talk, so when people talk about the crossover, it's a little weird, right? Because it happens every day. What we're talking about here is the last crossover, these comparisons that we'll make,
these are the densest, these are what are called near line drives, right? They're the, they're 7200 R PM, they're the densest thing you can get and they are still used in hyper scale and a bit of enterprise. Again, the last reason that always makes that crossover happen is cost. And so we've declared publicly now that we're going to match the costs and we've even thrown
out some numbers that we're going to match the acquisition cost of hard drive based systems with our E series. Ok. So that means at the starting point, you want to buy a petabyte, you're gonna pay the same cost or, or better with flash. Ok, great. As soon as you turn it on, you start to win from that point.
And so in, in terms of TCO or total cost of ownership, you're gonna spend less money on real estate and space, you're going to spend less money on energy and be able to make claims about how you're more energy efficient, which both matter depending on what your role is and you're going to go and visit that system much, much less often in terms of repairing it if you think about. So, what, what I did there is I had same
comparison that Harry made seven X lower failure rate compared to hard drives. But at the same time, we're three times bigger or maybe we're 10 times bigger. So just with today's comparison when we're three times bigger, but seven times lower failure rate, you could multiply those two, that system will have over 20 times fewer failures of 20 times fewer visits by a human
that has to go swap parts out. So in terms of operational simplicity, this is a game changer, um you can get what you want from the storage without the care and feeding that it might take from, from frequent visits and frequent repairs. I think something we didn't mention, but not only is the failure rate lower on an ongoing
basis, but the lifetime is also double. So we'll put out that we expect these drives to last 10 years. I actually expect most drives to last much longer than that. But claiming any types of electronics lasts longer than 10 years is maybe a fool's errand. So I'm just going to go ahead and say 10 years, everybody knows that hard drives don't last
longer than five years. And in fact, I think we were kind of kind in the comparison on the, on the failure rate because that's the failure rate while it's healthy, which is the first kind of four years of life. The definition of becoming unhealthy in a population is when that failure rate starts to climb in year five. And by year six, it's a,
it's a liability to have those units running in the data center. So I separated, I, I like to be kind. So I separated those two things out. I said when the things are healthy, we have a seven times lower failure rate. But oh by the way, we're also gonna, you know, you refresh that entirely and buy all new capacity. We're going to last twice as long.
Those factors in terms of operational simplicity and overhead are are really big and some of you operate really large environments and you know, this even better than we do. And a lot of times when we talk about this last crossover tier where cost is kind of the last thing to fall. A common refrain is, well, we don't care about
performance in this tier. And that is usually in the past, what drove people across these transitions was I can afford it because I need the performance, I can afford it because I need the performance over and over and over throughout those those years and all those different workloads. Well, that's why I like to focus on the cost as soon as we achieve cost parity,
acquisition cost parity and we have better TCO Well, now you have no argument but by the way what you're going to get basically for free at that point is extremely higher performance. And so even if that's, it's not an excuse, it's literally like we've optimized systems over a long time to say, you know what, some data doesn't need to be super hot. Some data needs to sit in an archive or be accessed very rarely.
We think it's time to move that kind of workload to flash. But by the way, if you do not want to access that data, if you want to do analytics on your offline data, if you want to do uh data integrity checks on your archive, if you want to scrub uh old snapshots or older uh older data for viruses that weren't known when they were put away,
you can access that data and make it useful in ways that wasn't possible when the whole system architecture was, we'll never touch this data. So whether you want to look at it is, I'd like to have that performance capability and now the cost is affordable or finally, it's affordable. So there's no reason not to do it. And you have this new capability, you could look at it either way.
But we believe that that crossover is, is a slam dunk for anybody in the enterprise. I'll leave a little bit of window because we do know that for some people, if you buy 100 exabytes of hard drive, anybody in the audience buy 100 exabytes of hard drives a year people do and those people can still get it a little bit cheaper. So we have our work to do for the next couple of years to chase those down,
which is actually kind of exciting. But if you're not at that scale, we think the time is right now and you should never buy a hard drive again. Take advantage of all these other great benefits and rid yourself of that old technology. So I think that's what we had for today. Um But we do,
we're about on time. We have, we have time for questions, questions, anything goes really. Uh And after the session, feel free to come up and see the drive if you'd like um a couple of things, one of the first things was all our drive and then you proceeded to give 20 minutes on how we don't have in the relationship of man
here. OK. So I'll, I'll back up on it a little bit. So the, the DF MD that technology is that there's an in, in integrated NV Ram. So where we used to have modules that were dedicated to NB Ram. And if I step back, even from that in a, in a flash system,
especially a data reducing flash system, you want performance out of the front end. So we want as soon as we get a right, we want to store the right durably and acknowledge it as soon as we can, that's the function of the NV ram is to, to be that buffer, to give us a fast response time, you get your acknowledgement as soon as possible. But in the background, we do a lot of
processing on that data. We we organize it, we look for compression opportunities, data, uh ded Dulic location in other integrity checks. We do a lot of processing on that data. It's precious, right? And that can take some time. So we need to decouple the fast response time and the buffer that enables us to do all that
processing and that's the NB ramp function. So all DF MD says is we've, we've now integrated that function into the drive. It's still a separate function than manned storage. So you can think of ad F MD as it's one unit with two jobs. One is to provide a little bit of fast space for the,
for the NB ram. And the other is to present the large space for, for durable storage in man. So you might actually access that drive twice to do it, right? But any operation in the system is actually spread across lots of drives. And so we'll do maybe a mirror to do hit
several NV rams with that data, hold it there while we do all of our other processing, we do some parody and you know, erasure coding and then write the the data out to the NAN portion, then we can free it from the NB ram portion. Is that making sense? Absolutely. Yeah. Yeah, let's talk after we'll be happy to, curiously
TLC number didn't change to 2016, 2026 on it. Well, personally speaking, I don't like to show my strategy in the public, but this graph has been out there. And so I'm like, OK, we're gonna own it now. We haven't made any public claims about TLC. So I just didn't increase it.
So it's, it's more of a non statement than anything. But at the same time, high capacity, pressure has moved to QC. And what? And TLC, as far as I can tell will have a role for the long term. It certainly is a core part of it. Today. We provide both and you've seen it in the
product line where if you want something with very low latency that's transactional, you probably should use TLC. And so we still have that, but the pressure, there is more, there's more pressure on IO per capacity. And so if you want to double the capacity, you also have to double the performance.
And that's, that's, that's not the way our systems scale. They tend to be capacity bound in other ways or sorry, performance bound in other ways. Let's go to the back you about what is point where you're gonna saturate. Yeah, point now or a piece. Yep. Thank you.
Um And uh well, currently and in and everything in the past has been based on GEN three. And in some select cases, we're actually right at the bandwidth bottleneck for GEN three. So the new drives that we, we, we gave the highlights for and this is one of them, those are GEN four drives, anything that's very close on GEN three actually looks very, very comfortable on GEN four.
And we don't really see the need. GEN five is really for. I'm a gamer and I have one SSD and it's really intensely accessed by itself. Most arrays that have say 10 drives are often we might even have close to 100 drives, the performance pressure moves from that interface to somewhere else. And so we're not super eager for GEN five, it will come eventually,
but we're not constrained by it today. Mhm Absolutely. So both of us work a lot on the robustness, the integrity of the arrays. And so even though it's fun to talk about performance and all the features and everything else, data durability, the avoidance of data loss is absolutely number one
priority. So we got to get that out there, even though it might not be the most fun for everybody, it's absolutely our first priority. Um So you're probably not going to trust me just because I said it. But we, we take this road map very seriously. And we say there's a lot of reason, you know, it's more than can we build it.
Can we keep the system integrity up as we scale and make really what we want to do is break the notion that there's some capacity limit that's safe or some blast radius that's going to be safe. We want to extend that and it's on us to prove that to the public and to you because we're going out really a lot faster into that realm than everybody else. So your old rule of thumb that some certain
capacity was the only safe limit. It's going to have to go out the window to take advantage of this. So fundamentally, the low failure rate is one thing that we rely on. And Harry mentioned that it doesn't scale the failure rate that we observe in our fleet doesn't go up as we get bigger and bigger modules, it's architecturally very low.
Um But still we're getting bigger and bigger and so that's going to get worse over time. So we also look at aspects like is there different encoding schemes that can keep rebuild times low? Um I don't want to let the cat out of the bag early, but we've got a plan for everything we showed you here that will keep it robust, keep it durable and keep rebuild times down as we
go through those. Um Well, scrubbing the man would be another example where if, if we do this things the same way we do today, we won't keep up. And so we kind of have a plan for all those features that kind of tracks with that capacity road map, we mostly keep it behind the site.
And maybe one thing I'd add to that is as a customer facing event. Like you don't really see the impact of a rebuild happening in the background because there's enough processing to ensure that both, both both processing and redundancy through our erasure coding schemes that it's not like customers are going to see the effect of an outage. So it might take a while and obviously 300
terabytes are going to take longer to rebuild than a 48 terabyte drive. But it should be happening in the background and everything Pete said, there will be enough durability, there will be enough performance to ensure that the customer experience is not impacted well. But that's fact that we factor that aggressively, I must say into our durability calculations.
So that's absolutely something we look at when we decide what erasure code schemes to employ. I agree with the gentleman's question because it's on the flash blade grow the flash blade. There's a certain point where your architecture says, oh wait, you bagged one more blade. Now, I'm going to account for another group of parody.
So adding that one blade, you actually shrink ask that blake is allocated to. I think that's 75 1 50. You're like, OK. Does the system see that it has this gigantic drive in it in behind the scenes? It says I'm not gonna do three, I say that that's actually how it works. But we try to do what you pointed out is one
very specific, you know, this blade to that blade count. But in, in, in a broader sense, we want to go to, we want to stay efficient. So we go to broader stripes. If we increase parity, we want, we want to kind of shift gears as the system gets bigger so that you can get more and more efficient and stay robust as it scales.
And, and I think what you'll also find is that with the larger drives that we probably start adding additional parodies sort of earlier on like with smaller drive packs. And the impact of adding that additional parody is more than cubic in its benefit towards durability, right? So it, it gives us a lot of cover to perform these other optimizations for performance or producing rebuilds,
et cetera. Uh So what the comment you made about the change? The F MC. Yeah. Thank you. That is the reason already seen that's got a Cota magically found more storage. So like I was literally, I got two.
One is uh and one months ago is well, you're welcome to. So it, it's funny because there's sometimes we have this internal debate, like should we be giving you five terabytes for free instead of making you buy it? We we always work on efficiency and we, what we try to do is back port that as much as possible.
We like to give you, we want you to be happy. We like to give you kind of stuff for free that way. So moving forward, we'll say architecturally this new approach is going to be more efficient. If it can be done in software, you're gonna get it for free and, you know, I can't promise it'll apply back 10 years.
But you found a case where you, you got a bit, but it's probably not from the DF MD because we aren't shipping. I mean, those are the new ones that we're shipping. So it's from some software improvements we've made, we're, we're constantly in there looking for efficiency and sometimes it means, hey, there was a little bit of reserve space that we found out never gets touched.
And so let's just give that back or we improve compression or delic. You see that's happened over the years too coming after. That's right. And we try to keep this relatively short and consumable, but sometimes we spend time talking about our monitoring capabilities. So it's pretty awesome.
We have trillions of flash blocks in the field, most of them phone home every 30 seconds. And so first you're thinking, well, that's too much data. Um, usually we get that in the form of statistics. If something goes wrong, we get a ton of information about what went wrong when things are going right.
We get statistics about how great things are, but that's a huge fleet. And with that scale, it allows you to say, hey, look, this something's trending the wrong way. In your case, we said look something's trending in the right way that enables us to, to make that kind of update and give it to everybody for free. And so that's a positive way that you got lucky that way if it's,
if it's a bad trend, usually what it enables us to do is say, what are all the other arrays out in the world that have a similar set of character. It might just be everything. Every, every, every bit of hardware is susceptible. We're going to do a fix in the next release and distribute it. If it's, if it's a more unique than that,
if it depends on your workload and the temperature, whatever, all these other factors we can go and proactively identify, hey, there's a small set of arrays or customers that are at risk and go really target the, the correction actions for that too. We're working, keep working on this.
Well, we're at time but we can hang out. Sure anybody else. Anything else you can.
Get an up-close look at Everpure DirectFlash® and find out why this technology differentiates Everpure from the rest of the industry. You’ll hear from the Everpure engineering team as they take you through the economic, power, performance, and density advantages of this pioneering flash management solution.
We Also Recommend...
Personalize for Me