Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
41:34 Webinar
Gaining Advantage with Analytics and AI
In this session, learn how data-centric applications use storage, how pipeline stages have varied demands, and how you can use storage to your advantage.
This webinar first aired on June 14, 2023
Click to View Transcript
Welcome everyone, the doors are shut. So I suspect that means it's time for us to get started. Um Glad you chose this session to participate in. We are talking today about gaining advantage with analytics and A I. So first thing, everybody in the right place. Yes.
All right. Very good. Um I am Jan off camp and I will be spending the next 40 45 minutes with this fine group of folks and I am joined by my colleague, Mela Klasky. So what are we going to talk about today? Um Interesting times, right? Everybody keeps talking about an economic
downturn and budgets are really tight, et cetera. And so because of that reason, I'm thrilled to see so many people here, but where there's a challenge, there's also an opportunity and we believe at pure storage that we can help you with the opportunity that is before you. I'm going to talk a little bit about that up front and then I'm going to turn it over to
Milov to talk about some of the things that you want to remain mindful of as you're planning for your infrastructure in this space. This space, of course, analytics and A I and then we'll close it out this morning by talking about some of the customers who have actually taken this journey with us and what it is that they were able to accomplish.
So I'm going to jump right in. It's a down economy, economic headwinds. This isn't news. We've all faced challenges up to this point and it's very likely that we will continue to face more challenges. And what that means is that customers like yourselves are very careful about where they
want to make their investments, where they want to spend their money. There are two papers that are referenced here in the lower left hand corner and contributors to this paper suggest that even in this downturn that the volume of data will continue to grow, they go so far as to say that it will likely accelerate in this downturn. And I suspect that that has a lot to do with
organizations that are interested in leveraging all the data that they can collect to advance their competitive position, more store. Excuse me, more data means more storage. You all know us as pure storage. And when you think about storage, you want to make sure because this will be your supporting architecture that you are selecting
a platform that is differentiated. It's not your traditional 10 year old storage. This is a platform that is designed for modern applications in this space. So you want to make sure that it's flexible, that it supports your requirements today, but it will support you as you move forward unified, you want to make sure that
it supports block and file, file and block. And oftentimes we find that performance is top of mind as we look to accelerate things in this space, as we look to stay on top of all the demands that are being placed upon us. So that's, that's good for the storage market. And I really already, I was gonna ask a question, I really already gave the answer away.
But the idea is when business leaders are thinking about where they want to invest, they're focused on things that are going to give them a quick return on their investment, they want to focus on things that are going to help them advance the business in these times. And so the answer probably obvious at this stage of the game that area of focus is with analytics and A I, both they are, there are many that feel that they are essential at this
point in time. And if you look at the quote on the right from Forbes, it talks about the idea that analytics and A I were number one followed by cyber security and automation. Does that surprise anybody? Maybe no, we realize that what you're
able to do is relative to your maturity in this space. And there are probably people in this room that are just beginning their journey in this space and there are probably folks that are fairly well advanced. The takeaway from this is that when the further to the up and to the right that you are the greater your competitive advantage because you can do more with the data that you're
collecting. They are actually companies that build reports around an organization's level of maturity. They take a look at the data that's available to the customer, what they're collecting and what they're doing with that data to see if they are indeed making progress. These reports by folks, you would expect folks
like Gartner I DC and so on. But regardless of who the author is, the prevailing thought is that the further to the right and the higher up you are, the higher your competitive advantage over a year ago, pure hired ESG to do a paper for us. And the idea was to capture the impact on a business when you are up into that right?
In the maturity model, what could it mean for you and I will share with you, I'll share with you some of the results that they delivered to us. So I will start with 2.5 X. They are 2.5 times more likely to outpace competition. And it's because customer, excuse me, organizations are focusing on things such as
customer experience, customer satisfaction. They're not only trying to maintain their existing base, but they're trying to attract customers away from other companies from their competition. I'm going to tie it together with infrastructure because that will support this effort in your organization.
And you want to make sure that as things change, the infrastructure that you put together can support that you want it to have a dynamic nature. 350% is a pretty big number. What on earth could that mean? Well, lots of things going on sales and marketing initiatives to identify new opportunities and organizations are looking to create higher levels of
efficiencies and they both come together and present it here as revenue per employee. And the report findings were that in some cases, 350% more. If you think about that, it's kind of staggering. It's like holy Moly and then lastly, innovation, businesses that
innovate are more likely to succeed. And what, what the report shared with us is that these businesses, these organizations that are innovative are two times more likely to identify new opportunities. They're 2.5 times more likely to deliver product and services to the market faster than their competition.
And operational efficiency always plays in and they are three times more effective in that space all coming together to create the percentage that you see here. And when you're selecting a platform, you want to make sure that that platform not only supports these requirements, but that this platform and your provider has the same business goals that you do to make sure that you're successful and
to deliver to you those solutions with the different procurement offerings that align with your business model. So what's it really boiled down to? I don't think this probably surprises anybody but it's about volume is, you know, all the time we're asked to do more, right? And you think about the variety and you think
about the different data sources, all kinds of different ones, velocity, I often talk to people and they share with me that they are challenged to keep up with the pace of the business that there is a demand for more and more data to be included. And time to insight is something we can't do fast enough veracity, data quality
should be a top concern. We want to make sure that we're analyzing data, we're analyzing the right data, the most current data to give us the best results. And it really all comes together in the in the form of value by executing on all these areas. You can deliver value that provides efficiencies, new opportunities and long story short helps move that business forward.
So before I turn it over to Merola, I have one more thing I want to leave you with. And that is when you're thinking about storage again, a big part of the supporting infrastructure, some things to keep in mind, these can be very complex. We're going to talk about this in the form of data pipelines, lots of moving pieces and parts.
And so anything you can do to deliver a higher level of simplicity lends itself to that overarching theme. What can we take out of the equation for you? So you want to make sure it's simple to deploy, it's simple to manage. You don't have to worry about tuning things all the time and high availability. Well, that's table stakes.
Nobody in this room, I'm sure is worried about cost. Um Actually, you know, every, every one of us is absolutely worried about costs. And so it's our belief that you want to make sure that you have the ability to make sure that you are always technically current through subscription services such as pure offers. It includes all your upgrades, but it even goes so far as to deliver you flex to deliver
to you flexible procurement offerings. Again, your provider aligns with your own business requirements said earlier that performance mattered when you're thinking about your infrastructure, oftentimes these use cases, these workloads are incredibly demanding and you want to make sure that your provider can deliver in this area again and that it scales with the needs of your business.
So I am going to turn it over to me to talk about some of those key considerations and then I'll come back to bring us home. Thanks John, go over here. So I'm not interfering with the speaker. So as Jan mentioned, my name is Sky, I'm Global Practice Lead for Analytics and A I and Pr and I wanted to kind of
switch directions. Jan did an awesome job explaining kind of why this matters and why it's really important. I want to talk a little bit about kind of the what and how um to do that. I wanna switch over and talk about some fundamental characteristics of storage and storage io in the context of analytics and A I I think because there are so many different
applications involved in analytics. And A I, how many of you have seen that like mad chart with like the 1000 logos of all the different things that are in analytics and A I, there's just so many things in play and lots of applications analytic A I pipelines are complex. There's usually, you know, dozens of them deployed in production at fairly large
organizations. Um I wanted to see if we could distill down a way of looking at all of them from the perspective of storage because you know, we do storage and that's what I'd like to talk about next. So the first bucket of fundamentals to look at is data integrity and that has, you know, let me just sort of build it all out.
Now, I look at that as persistence, durability, failures and then completion and consistencies that are, you know, sort of related um persistence is really just do you need the data to stick around? Right? Like sometimes you do, sometimes you don't uh we use persistence for data that is going to be reliably kept around.
And the term that shows up a lot these days is ephemeral. So data that can be temporary doesn't really need to be persisted is ephemeral data. You see that a lot in cloud applications, you see that a lot in containerized applications where kind of by default, the data is ephemeral. And when you need a state full application that has persistent data, you got to do something special.
So that's persistence. The next one is durability. How does this application need its data to be protected? And what are the different situations that it needs to protect the data from? Right? Like is the data durable in terms of handling
component failures, right? Like if a SSD or disc drive fails, what happens to that data? Sometimes you care, sometimes you care less um for a lot of analytic applications, there's cashing and I'll talk a little bit about that in the future. But you know, if you are implementing storage for cash,
sometimes something like grade zero makes a lot of sense. So it's not durable, but it makes sense in the context of your application and what you need. So durability can mean component durability. It could mean you know, server durability. It could mean things like you know, rack durability and even data center durability. If you're talking hyper scale
that gets us into failures just because your data is durable doesn't mean that it's always going to be reliably accessible, you need to be able to, you know, persist your data and you need to know that it's safe and you need to be able to retrieve your data when your application needs it. So a lot of times the failure handling goes past just the ability of the data into
accessibility. And what happens in terms of the rest of the infrastructure of the networks, connecting the notes together the power to your data center and to your acts, all of that is part of failure handling and something you might need to take into consideration as you look at the applications in your pipelines. And finally, there is this notion of around completion and consistency.
So you know, I I wanted to find terms that were broad but had meaning. So consistency or completion is really just when do you need the application to know that the data is stored safely, right? Like is the application stream essentially synchronous. So as soon as you won't issue another IO so you know that the previous IO completed successfully or is it asynchronous?
Are you OK? Issuing, let's say 128 I OS and letting the system handle managing the completion and your application can handle all of that, right? For some analytic applications, I would say for most of them, the asynchronous completion is the standard way to do it. But there are certain times in metadata and certain cases where you do want that
synchronous behavior and then consistency. Many of these applications are built in a distributed way where the different copies of the data are in different places. So when your application gets an acknowledgement that the data is stored safely, does that mean that every copy of that data is now consistent or you know one of them is, and it's up to the application to remember which one and the rest will eventually become
consistent with that copy. So these days like this used to be a more, more of a thing. These days, most storage systems out there even in the cloud are starting to become immediately consistent, but it's something to keep in mind, right? So think of these as lenses through which you could look at your applications,
you could look at the set of applications in your pipeline and understand how they interrelate and what they need from the underlines the storage systems. OK? I'm talking a lot and I've consumed a lot of coffee. So I might be talking really fast and I don't even know it. And so um the next bucket of characteristics
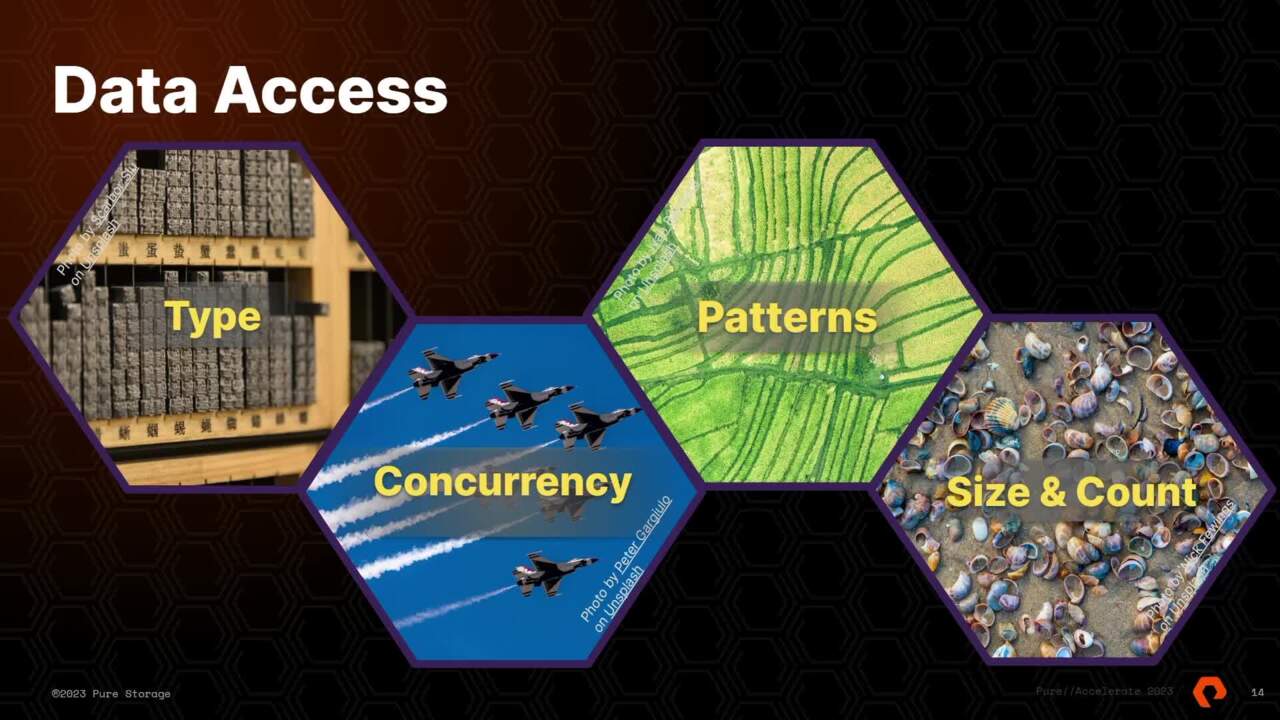
that I think is important is data access. And I see those as broadly falling into these four categories, right? So the data type, the data access patterns, the concurrency of the data streams and then the size and count of the data that you're working with.
So for data type, it's you know, fairly straightforward there tend to be data operations and metadata operations. And for each one, there's essentially reads and rights. So you have data reads, data rights for metadata, it's a little bit different. You we usually talk about like modifying and non modifying metadata operations,
right? Which is sort of equivalent to reads and rights. And then in any application access stream or phase, there is some mix of them. It's very rarely 100% 1 or the other. But you can look at the characteristics of your application by asking like, what does that mix look like? What percentage of the mix are data reads
versus data rights, metadata updates versus metadata accesses. The next one is patterns. Um Again, you know, I've been doing this for a while, patterns just speaks to like what is the access pattern for the data, you know, layout? Is it random or sequential for a lot of
analytic applications? There's a lot of sequential access, there's a lot of streams, a lot of data getting sort of like laid down as it's coming in or accessed in the same way it's laid down. But you know, we're a flash company. So for flash and a lot of modern systems random and sequential don't really matter that much.
If you remember you've been doing this long enough, you remember there were like cashing controllers and like pre fetch algorithms and it really made a big deal whether the controller was smart enough to do like, you know, skip sequential and recognize patterns where you, like read 100 bits and then you skipped 1000 bits and read another 100 bits. Like that's less of a deal. Now, it's just like less important to recognize
those patterns. And cache and controllers still have a role to play. But with the underlying medium, um there, the axis pattern is less important but it's still something to think about next is concurrency. And that's, you know, also fairly straightforward for your application, how many streams of IO are happening at the same time,
right? There are certain situations where you have your application running on a single node or there's an important component of your application, like let's say the name node, right? And it's doing a certain level of IO but it's one node doing IO and you have a single stream, it might be a single A I workstation that a researcher is using.
So there's one stream of IO but it might be gigabytes per second, right? So one stream might be a cluster of like four of these NVIDIA DGX servers. So you have a small number of nodes each doing some pretty intense IO So that's another aspect of concurrency. Or for most of these very large analytic applications, you have dozens or hundreds of
nodes, they're all doing lots of IO at the same time, you have hundreds of streams in the system. Each one might have like hundreds of outstanding IOS asynchronously launched and being tracked by the system. So that's another level of concurrency. Um When you have that concurrency, another thing to think about is sorry.
Wow. Um Another thing to think about with the concurrency is how synchronized are these streams, right? Like if you're talking about a farm or like a data center with thousands of nodes, but each one of these nodes is essentially a workstation that some human is using for data exploration.
Chances are those requests are not very synchronized, they're sort of driven by humans. But if you have an application that is doing some heavy duty processing to build up a dashboard or a report, and those requests are each being spread out across dozens of nodes, those requests and that concurrency is synchronized. So you basically have spikes in IO that are correlated across potentially hundreds of
threads and applications. That's something to keep in mind. Then there's size and count. Like how big are the objects that are being accessed? Right? Like are we talking about tiny little objects that represent some small amount of state in the system or are you talking about, you know,
potentially gigabyte sized objects that represent very large chunks of a data set? Um You know, there's more and more lakehouse formats where you're using parquet files, you know, iceberg files to organize the data where these objects might be many gigabytes in size and then count there are data sets that are made up of, you know, thousands of fairly large objects and files and other data sets that literally have
billions of objects in them. So we have like one customer that I think has something like 67 billion objects on one of their flash plates. Um you know, that is a different kind of data set, right? So keeping track of the count of objects in your data set and also how they're organized if that matters, right? Like if you are using a S3 storage with a
bucket, the organization of that data might not be that important. But if you're using a file system and trying to manage, you know, billions of objects, how you organize those files might matter for your application. Um You know, thankfully something like flash blade handles all of that without having to worry too much about it, but your application might not and that brings us to the
applications. So for application storage, every application out there tends to have some mix of this, right? So there is a data store settings or configurations, some level of cash for analytic applications and then miscellaneous storage that, you know, I wanted to keep it to four and just sort of mix them together because this stuff is sort of mixed up. So the data store is where this application
keeps its persistent storage. This is sort of what you query, what you update, where cleaned and ingested data eventually ends up the settings are the configuration settings for your application. But a lot of times for these distributed applications, this is also essentially your cluster state.
And it represents how the different pieces of your cluster, the different nodes and their roles are kept many of the open source applications essentially keep this stuff on each node. So each node keeps track of its own configuration. So like elastic search tends to have, you know, each node has its own config um but there are other applications that use a service
like Zookeeper or CD to keep the state in some other service, right? But either way you have to keep track of the configurations in the state of the cluster. And this becomes very important for dealing with things like upgrade and failure scenarios. If you're trying to deal with what happens when a node goes away,
how do you restore? Like let's say your note is implemented as a VM, right? Something happens to that server, the VM goes down or whatever happens, right? You create, you stand up a new VM that might take you a minute. How do you bring it back into the cluster to
replace the failed one? Or how do you unplug, you know a commodity server and plug in a new one and get it to come back and do what the previous failed node is doing. So you need some way of tracking these settings in a distributed way and ideally automatically repopulating them in failure scenarios.
Um I mentioned cash before a lot of the design patterns we see in analytic applications these days is to disaggregate storage from compute, right? So whereas the original kind of big data applications had distributed dad, so each server had a bunch of direct attached storage, it would hold the the data and then that data would be broken up into shards and the shards replicated across partner
nodes in a smart way, right? That has a certain simplicity appeal, but it has limitations in terms of flexibility, agility efficiency. So more and more applications are following this design pattern where they're persisting their data in something like S3 object storage and then they're cashing the most relevant hot
data on the local nodes and building the application network. So when you're cashing, you need some fast place to put the data and you need to keep track of this notion of working set size, right? So like what is the hot data that is going to be sitting in the cash? How large should your cash be relative to your needs and access patterns? All of that is part of what you consider when
allocating the cash and sizing. And then finally, there's my odd luggage of miscellaneous that tends to be things like temp space or spill. Like a lot of times if you're doing things like large table joints that just don't fit into your memory, you need to be able to spill somewhere while that operation completes.
So you need some storage, chances are it could be ephemeral. Um A lot of times if you're using that distributed as it's, it's never like just an attached block device, there's always a file system. Many of the file systems that are used for analytic applications tend to have things like log structured file systems or right ahead logs. So you might need some local storage for
your right ahead log if you're using local storage. But hey, if you use pure storage and you disaggregate and separate your storage from compute, you might not have to worry about that, right? Um Some of the other things are like checkpoint restarts. Many of these analytic A I jobs or A I jobs especially can run for like days or maybe even
weeks. So in case there's a failure, you don't want to lose all of that previous work. So these applications will eventually check. So, you know, let's say every hour they'll write their state to persistent storage. So if there's a failure, they can just restore from the checkpoint and keep going. So, you know, part of what you might need to worry about is checkpoint restart storage as
well, right? So these are the 12 kind of lenses that you can use to look at any application and look at the mix of those different applications and that mix shows up in the pipelines. So these applications are almost never used in isolation, even if it's an all encompassing app like elastic search that has the ingest and the cleaning and the,
you know, reporting and visualization built into one ecosystem. There's still a pipeline that the data flows through. You know, a lot of times we talk about it sort of looking like this in terms of data interest, cleaning and transforming that data exploring it interactively by data scientists and analysts to understand how to apply that data to the business problems you're trying to solve
and then deploying them whether that's kind of batch reporting or you know, live dashboards that are dealing with streams of data or your data centric applications that are working with kind of immediate live data streams. But what you can see is whatever those applications are in the different pieces, they all have different characteristics and you need to kind of keep that in mind.
Um and those applications kind of talk to each other, they have a dependency on each other, even if it's just sort of like one is a source for the others out in A I. It's also pipelines, it looks a little bit different, you know, this is probably way over simplified but the pipelines and access patterns and the flow of data is different. But the whole concept that there are different
applications and different access patterns at different stages of the pipeline applies. So you can use those 12 lenses of fundamentals to look at the applications in your pipelines. Um Part of what we've been preaching for a long time is the benefit of using external storage to break down data silos. So one of the things that happens in this space is we have these applications that are
architected with distributed direct attached storage and that makes it very easy to create silos of storage, those data stores for each application end up being siloed. And that means that your pipeline requires a lot of copying of data from one application in one silo to another. And you end up with multiple silos that are not that efficient to manage.
By breaking down those silos, you get a lot more efficiency and agility in terms of your pipelines and not only do your pipelines run more efficiently, but it's easier to add pipelines. So as you have ideas, as you need to add pipelines to your overall data platforms, it becomes easier when you separate storage.
One way the pure helps make that easier is we offer a small number of data, you know, arrays that each have the capability to handle a very large or I should say a broad range of applications and workloads, right? So we talked about all of those different fundamentals. When it comes to flash array and flash blade, each one can handle a very broad range of all
of those different characteristics. Some need low latency and flash array is really great for that. Some need, you know, tens of gigabytes worth of throughput. Flash blade is great for that. Some applications and stages need cost optimized storage where you can keep your cool,
colder data, colder data for a long time and flash array C flash array E now uh that was exciting and flash blade E provide great low cost storage for archiving and kind of the frozen tiers. Um So each one of them can handle a very broad range of analytic and A I applications when you want to separate storage from compute,
but it gets even better if you're working in a kubernetes environment and you've containerized your applications because now what you can do is use pork works as an abstraction layer and you can start building different storage classes and service classes on top of that small number of foundation platforms. And now your applications are simply given a storage class that is mapped to a service level
that they need and expect for all of those different types of storage that the application needs, right? So for some of your miscellaneous or your temp storage, you don't necessarily need persistence, other places you need persistence, but you need different types of persistence and different access patterns of persistence with port works, you can carve out those different storage classes and present them to your
kubernetes application in a very simple logical way where a lot of your, you know pipeline deployment ends up being just a small collection of YAML files and you can handle all of the, you know, pod replacement in an automated fashion. So, you know, I how many of you are already familiar with pork works? OK. So a few folks, um essentially Kubernetes is a
powerful, you know, ever more popular orchestration framework for clusters of containerized applications. And in that environment, it was essentially designed and built for ephemeral storage, there's really, it's built to be stateless. And the idea is that if you need state in your applications, you you know,
use a service that is a state full service. So this is part of that whole, you know, micro services architecture that ends up with a giant web of interconnections. And it's hard to manage in some like, you know, totally pure way uh or totally simple way. II I don't know, pure gets a little abused here, but um doing kind of like, you know, true micro services
is hard. It's a lot easier when you can add state fullness and persistence to your applications. That way you don't have to like factor it into dozens of little micro services with, you know, dedicated state full micro services. You can just do what comes naturally and what people are relatively familiar with from a logical perspective, port works makes that easy. So port works makes it easy to have persistent
volumes, persistence and state fullness in your applications. And then it adds the ability to back that application up in a very, you know, pretty much effortless way. You can build ad R version of your application either in a cloud or in a different data center. You can migrate your entire application in a very simple way between different data centers
and locations and cloud providers. Um All of that essentially comes for, well, not for free, but it comes with port works and what port works enterprise can do. So with that, let me hand things back to Jan to wrap up. Thank you. So I'm going to wrap up and I promised you that
towards the end, we would share with you some examples of customers that we've been able to help in this space. We've worked together with them to understand what it is they're trying to do and help them deliver. And there's a few examples I am going to focus on out of the several that you see here. The one in the lower left hand corner macarthur lab 24 times faster data
analysis around speeding drug discovery. You think that makes a difference? Sure it does. And then we have options technology when you take a look at what they're able to do, cutting job run times by 54%. What does that mean? Well, it means that you know,
it frees up analyst time and guess what? They're going to be asked to do more. We all know it, right? And then analytic health systems. Another one that I like to highlight 100% up time but run time for key reports and insights cut by more than 80% when time is of the essence our customers like yourselves.
Tell us that these things matter. We've had some technical difficulty with this part of it. Here we go. Ok. The moral to the story is if you click enough times, you finally get there. I talked to you earlier about the opportunity Miroslav
shared with you. The things that you need to think about when you're thinking about the infrastructure, the architecture that will support these efforts. And it is our hope that you are beginning to connect the dots. And you can see if we work together what we might be able to accomplish for you. It's all about competitive advantage in the market today and you want to be the leader.
We talked about consolidating data, we talked about accelerated time to insight, which means time to action. We talked about simplifying things in this very complex space. But at the same time, you want to make sure that you're agile and flexible and that what you deploy today will carry you through as things change in the future.
This is our last slide. And I think the QR code is designed to point you to the location on our website where you can find more information, but take away this no matter where you are in your journey. If you're just starting or if you're, you know, you're at the high end of that, that curve up into the right pure can help you.
So talk to your sales teams, engage them and give us the opportunity to help you be even more successful. And with that, I thank you for your time. And I think if, if time does allow we have an opportunity to take some questions. Oh, sure. Thank you.
Data scientists and analysts are critical for a competitive advantage in any industry. In this session, learn how data-centric applications use storage, how pipeline stages have varied demands, and how you can use storage to your advantage. IT will learn to map infrastructure capabilities to customer needs, and data engineers will better understand how their choices are impacted by the infrastructure they depend on.

Test Drive Modern Storage for Analytics and AI
No hardware, no set up, no cost–no problem. Take a free test drive and see how easy it is to scale every tool from ingest to visualization.
We Also Recommend...
Personalize for Me