Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
35:13 Webinar
SQL Server 2022 Innovations on Everpure
You'll learn about the latest SQL features, how to perform application-consistent backup and restore using snapshots, and enabling data virtualization using S3 object storage.
This webinar first aired on June 14, 2023
The first 5 minute(s) of our recorded Webinars are open; however, if you are enjoying them, we’ll ask for a little information to finish watching.
Click to View Transcript
All right, let's get started. Team. Uh Thanks for coming, Shaq was pretty fun, right? It's hard to follow that. So at least there was like a half an hour between the funniness and shenanigans that occurred and me having to talk about database systems, right? So let's get going.
Uh We're gonna talk about sequel server 2022. Uh and how that maps to what we do at Pure, right? Uh So, I'm Anthony Sin. I'm a principal field solution architect at pure storage. I mostly specialize in system architecture and performance. Uh Before I came to pure, I was an independent consultant for 12 years.
Uh So a lot of the experience that I have working with customers uh I bring to the party at Pure, just kind of like I was joking around with Christopher here is that I worked with availability groups a lot in my career. Uh They're fantastic. I made a lot of money as a consultant because they're not easy to use and we'll talk about some of those challenges around that today and how we can make them better.
Um The cool thing is I get, I get to talk about products today. But really it's about the outcomes with the products. I'm a solution architect. So I get to play with really cool toys and put them together to build systems to help you all support your businesses. And so I took the session today and I broke it down into two big chunks.
We're gonna talk about snapshots for databases and then all the cool stuff that we can do with that on top of sequel server 2022 uh I will say this. Um one of the harder things to do with the database system is upgrade it. So I'm fully aware that it's challenging to move between versions of SQL server. But there are some really compelling features in 22 that people are evaluating it.
Um More than they have previous versions and we've seen some internal metrics uh that it's nearly two X of what it is for previous versions of SQL server from an adoption standpoint. So we good, sir. Cool. Awesome. And so let's talk about this. Uh who's using snapshots today on their arrays. OK? Who's using them to do things with database
systems to get access to data, to give developers copies of databases, ever anybody. All right. So half of y'all raise your hand about snapshots and three of y'all raise your hands about for getting access to data. And that's awesome because that's what this first part really is going to focus on.
And I like to say that this is our superpower as a as a device as a flash array device is that we basically break down the size of the data from the time it takes to get access to that data. Like we can give you a copy of a database instantly or a collection of data instantly, whether it's 10 gigabytes or 10 terabytes, right? Which is very powerful because that unlocks
some really cool outcomes from a business standpoint. I use this slide all the time when I talk to customers. And usually it's just this slide I talk about, it takes like 30 minutes to get through this. I'll do it a little faster today because you know, we got more content to go through. But when we talk about what snapshots do for a system on the top here,
that's the use cases. I'm not even going to start with the tech. I'm gonna talk about the value that's gonna add to your company, right? So we get the idea behind instantaneous data protection, right? If you gave me access to production and I did something stupid, we can revert that really quickly with a snapshot to a previous state,
right? So that's, that's pretty, that's a pretty clear cut use case. Uh One use case that we talk a lot with customers about is this uh let's say I do something bad to an individual subset of data, right? Which may require me to have to do a full database resto which is gonna take how long long right time.
So one of the use cases that we talk a lot about with customers in DBA specifically is, well, I can take a previous snapshot of that database clone it and attach that back to the same instance and just drag the data out that was accidentally deleted and stick it back into the production. Right. Doing this with backups means I have to land a backup somewhere and then get the data,
right? So one, I have to go get the backup, I have to land that database somewhere and then pull the data out. What's that? Take time and space, right? And so doing that with snaps and clones means I can do that instantly to get my business back into a better way than it was before.
Uh We talk a lot about dev test refresh. So the three of y'all get this, the rest of y'all. Let's look at this more closely. Oftentimes developers need a cut of data to do a thing, right? They need to build a new feature for your product. They might need to go and research a bug or an
anomaly in a platform. Uh One of the hardest things I've ever had to do as a, as an enterprise architect is I worked for a major health care system and we had to do a major upgrade where we had to change the data type of a money column from, I forget the exact data type, like data type A to data type B,
but it was a money column in the database, right? And that's very important because people had to do things like reports and have to do month end reporting and have to make sure their financial is balanced and the health care, it's complicated because you have fee schedules across different things. And so I had to test that upgrade over and over and over again.
And so I'd run the script that converted the data. I'd find a my bug. I had to go restore the database. I'd go do something else for a day. I'd come back and I'd run the rest of the script after I fixed the bug, right? And so what did that cost me time?
And I was out of context, I was switching, going, doing another thing and I had to come back to what I was doing. If I had snaps and clones at the time, I could run a script, find the bug, fix the bug, snap clone, stay in context in fixing that problem and iterating more quickly on that solution, right? And so what does that mean to your business if
you have developers or D BS that have to work with data in those contexts? Now, they don't have to wait around to go get access to that data, right? So your developers can build new features, they can fix new bugs, they can move the state of your business forward faster than they ever could. Right. I worked again in health care, uh who works in
a place where they get third party apps from other people that you have to support. Right. Pretty much all of us. And how many times does a company slid a script across the table and said run this in production? You're like, OK. Right. How many? Yeah, almost all of y'all right.
And you do it in DEV, you do it in, you do it in Q A happy, happy, happy, then you do it in what happens something breaks because never everything's never identical. So this another scenario that we talk about the customers is in that scenario when you go fill out your change management request and you put your roll back time,
you can put zero, right? Because you can instantaneously revert the platform back to the pre upgrade state, right? And that gives you a lot of confidence to get your business back if there's a failed upgrade on your weekend and give you the confidence to move forward. And so all the goodness that I'm talking about, it's kind of summarized in the bullet points below in that we can get access to this data
instantly, right? I don't have to move those bits and bytes across the wire. I don't have to burn the CPU cycles of the network throughput to get access to that data right snaps and clones consume very little space and will have no performance impact on the production workload. If I want to cut a copy of prod prod won't know.
Right. Let's clone that to dev. Now you do have to consider the workload, right? If I'm putting uh a snapping clone and putting workload on an additional array, of course, that counts because that's just IO that's gonna exist, right? And so in the end, what I want to talk about is how this can really unlock what you're gonna do and getting access to that data from an
automation standpoint because I'm the last person that wants to click a button on anything. I want to write the code to do a thing. The funny story about that is when I got hired up here, I went straight to doing everything in powershell, right? Because that's what I was used to using as a DB A and then I get about like nine months into working here and the customers like, can you show me how to do this in a gooey?
And I was like, I actually cannot, I have no idea, right? So it was kind of embarrassing for me as a, as a new employee. But then I had to go and learn how to do it in a go because I used my tool of choice, right? And that's kind of the idea here is like we're going to meet you where you are in your automation journey.
If you're like powershell, Python, rest answerable, whatever it is your jam to get access to build automation around these things, you can, right? So if you're building DeVos pipelines that you're going to do some sort of release in that release, you need a cut of data. That's cool. You can write C# against our rest API call that
as a library on your app or whatever it is that you need to do that, combining all of that with the goodness of safe mode. We're going to get the data protection for our data sets. Also question and comments throughout. Uh I'm gonna, I think it's a 45 minute session, but I'm planning to go about three hours.
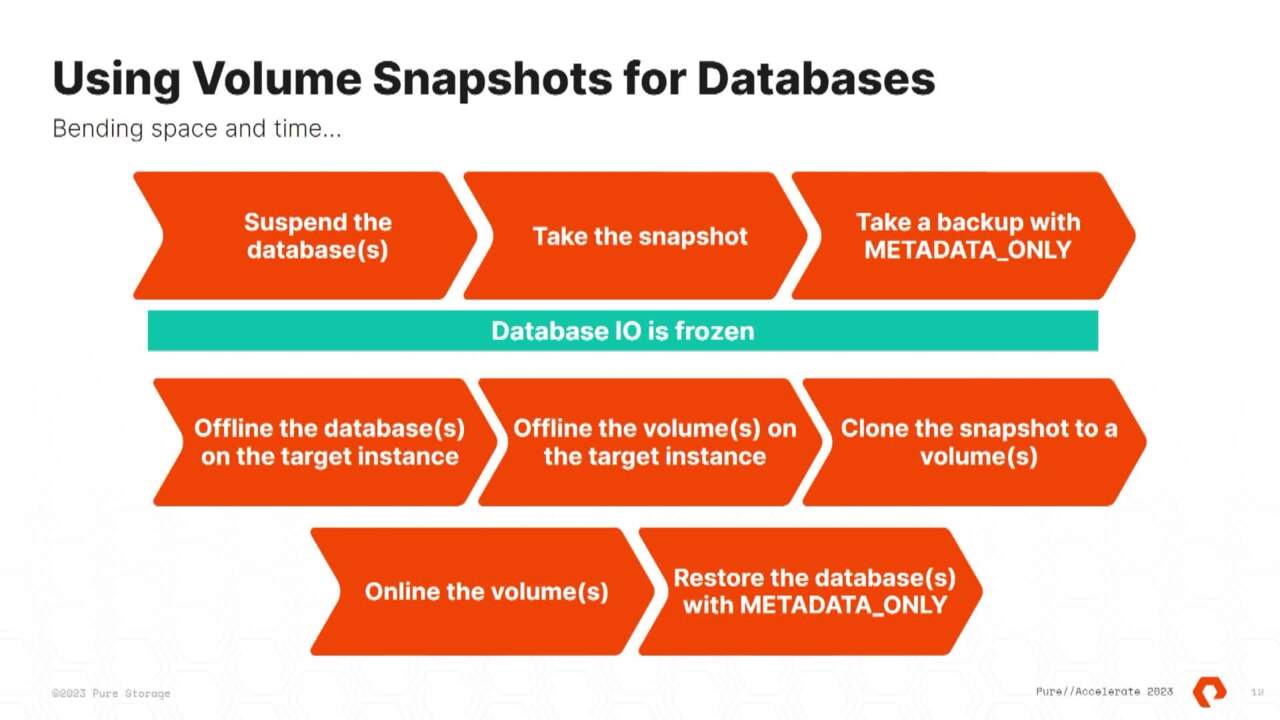
Just kidding. Right. If you ever speak, saw me speak before, I'm notorious for going along. Um, but the workflow looks like this. Uh When, if you're talking to your DB A S or you are a DB A, this is no different of workflow than you would see in, in a backup. Like if I had to restore a backup to a target
server to get access to that data. Well, I'm gonna take the backup, I'm gonna restore the database and I'm gonna get access to that data. But the workflow we're using snaps is I take the snap on the primary array right, offline the database on the target, right? You would do the same thing if you were doing
that on a restore, it's gonna offline the database, offline the volumes associated with that call, the Snap, online, snap online, the database, right? This is like six lines of powershell. And I'm gonna show you that here in a second, I think right now. So I realize this is a little bit small, but I'll talk you through it. So this is SQL server Management studio which
is the primary place, your D VA S and developers will live when working with data this database and I'll read it to you because again, I realize it's small is just about 3.5 terabytes, right? So it's pretty spicy, right? Not, not terrible in size. And I want to take that and I want to get a copy of it on the second SQL server here at the bottom and from a powershell standpoint,
again, it's a little tiny, but I'll walk you through the code is we use our Powershell module, which is available on the powershell gallery and we'll authenticate to the array which is what's happening here. First, this could be an API key. This could be pulled from a secret store. Clearly, I wouldn't want to type this interactively when I'm building into automation.
What I'm going to do first is I'm going to offline the database, which is what's happening on line 13. I'm going to offline the disk that supports that database. If this database spanned multiple volumes that would be wrapped up in a protection group and it's the same pattern after that, I'm going off to the array,
which is the next line of code here. It's a pleasure you see next door. And then this is kind of where the magic happens from a database standpoint. Uh It went too fast. Where did I go right there, right there is where the magic's happened.
So in a single line of code, what I'm going to do is I'm going to clone this source volume. I'm going to overwrite that target volume and that's all going to happen in one line of code and that's going to be instant metadata operation. So think about this, it's a 20 terabyte volume behind the scenes, it's a 3.5 terabyte database.
And the second when I run that code, that data is available to me on that target SQL server, right? And then I unroll what we just did. I online the volumes, I online the database and I'm going to go back into management studio after I do those steps. So online to database, flip back to management studio.
And then when I refresh that, we'll see that the database has the new the table I added, which is called big table, which is a very big table, right? Cool. And so this is the foundation of all the stuff that we're talking about today is the ability to get access to that instantaneously what's up? No, they don't have to be Vival that exact code that you looked at could be Vival rdm or
physical. The only variance is if you're in VMS because you have the, uh that's what I'm looking for. The abstraction of emfs bringing it to the party. Uh We do have sample code available for that too. It's a lot less sexy than that. Right, sir. So TDE actually is a really, really good
question. There's zero impact on TDE with the exception of the fact that when I clone from server A to server B the certificate chain that is encrypted on the primary instance is available on the secondary instance. So if you've ever done a backup and restore it to another instance with TDE, same pattern or availability group, same pattern, right?
Yeah, exactly. So and it doesn't have any impact on uh the portability of the data in the sense of um snaps and clones or replication. Uh But the data reduction isn't great in that sense, but two snaps or two clones of the same exact database presented to two volumes will data reduce. So, yeah, that's pretty cool.
Um I did a lot of work on that because I was like, I wanted to kind of feel where the sharp edges were around that because a lot of customers are interested in using TD even on our platforms. And so let's take that as the foundation of what's going on in sequel server 2022. Uh So what you just saw was a crash consistent snapshot of a volume,
right? And everybody on the planet conflates these terms, app consistent and crash consistent, right? All app consistent means is I've told the application I took a backup or a snapshot, right? But what's the core function of a relational database system? If I go up to a database server and I pull the
plug and I plug it back in, what's the expectation? Right? The data is gonna be there every time. Yeah, you have to take into consideration crash recovery. And so if I take a snap and clone, it's kind of the same thing. I'm basically taking the drives off of one server and sticking them into another,
but I'm doing it in metadata inside of arrays. And so the guarantee is a database will come back every single time, right? And I've tried to break in every possible condition. And if I snap and clone a SQL server database, I've seen it come back every single time. But what you don't get with crash is this if I take a crash,
what's my RP? Right? Is the snap, right? Snap now snap sometime in the future or in the past whatever direction you want to go, that's my recovery point is the snap. But what as a DBA I might need in between, right? And we can do that with application consistent snapshots.
I can take snaps along the way and then I can bring log backups or diffs to the party like normal sequel server data of log backups or dips. And then I can control my recovery point because now whenever I store the database from a snapshot, I can put it in restoring mode and then I can restore diffs and locks, right? And get to the exact point in time.
And the cool part about it in SQL server 22 is they push this into the database engine So you don't need VSS anymore. Tell me how much you love, VSS, right? Two things. One, there's no additional software needed. So this will just be in SQL server 22 you don't need anything special on our rays to execute
these actions, right? And the reason why Microsoft did this, it built this feature uh because in SQL server 2017, they rolled out a thing called SQL server on Linux, right, kind of hard to port VSS to Linux. And so they took 20 year old code from sequel server seven and brought that forward to now
and implemented this feature. And so they pushed that application consistency up into the database engine and we'll talk about that workflow in a second with T sequel snaps. Now, I can get a consistent recovery but I can also do really cool things like build log shipping replicas or build availability groups of snapshots or who uses a right about almost
half of y'all who likes seating availability groups. Because what does it take time, right? And space. And if you have a slow or high latency replication link to like ad R site, what's that take right time, even more time. And so we're gonna talk about how we solve that problem in availability groups here in a second.
The other thing that was cool in SQL server 22 that maps back really well to what we do as a platform is this thing called QAT. Qat Uh Quick Assist technology is used to be a physical PC I card. You could pop into a sequel server right now. It's part of the Sapphire Rapids chip set, which released earlier this year, which is also the foundation of our XR three,
our four platform that just came out what you can do with this card. It's 800 bucks, it takes up a PC I in your server is if I take a backup of a SQL server, I can offload the compression to this card, right? So in our lab, I had basically have a non blocking architecture to back up to a flash blade. It's really cool, right?
And that I could push it back up. And, and the actual um bottleneck in this platform is the CP US in the server and how fast I can push data out. It's a 24 core box, right? So I ran a backup with compression on the server and it pushed 24 cores to 60%. CPU no workload was running, right.
Turn on this feature, 6% CPU and a backup runs. Right. So if you're a 24 7 shop and you have people that have to deal with this pain while you're taking a backup, this solves that problem. The other thing that this solves is the backup file that gets spit out from.
This is a native backup and it's about 10% smaller than if you do it with SQL server, native compression. We sell storage for a living. That's cool, but that's really cool to have a 10% smaller backup file. If you have a multi terabyte database, right, you're taking backups over time. So back to volume snapshots of what that looks like from a workload standpoint,
we still have to suspend the database so we'll execute. There's some new T sequel that's exposed in 22 that you suspend the database. You take the snapshot and you take what's called a metadata only backup. That's a T SQL statement that has to occur, right? That's the duration of the IO freeze.
So in my lab, it takes 100 milliseconds to do all of that right? Freeze snap, write the file out. That's pretty awesome, especially compared to DS S right now. Once I have that done, I can get access to that data by offline in the target online, offline in the volumes clone online. And then there's new resource sequence or
restore syntax in T sequel that will read that file in, look at the volumes and then bring the database either online if you tell it or put it in restoring mode, right? Restoring mode means I can restore logs or I can build an availability group. So now if I want to go build an A G within an array, this is instant regardless of the size of data,
right? If it's in between two arrays, it's going to be data reduced replication. So the first time it ships it across, it's going to be 4 to 1, which is our average data reduction ratio for a database. So imagine that being able to take a 40 terabyte database and have it moved to another array four times faster, right? But if the bits and bytes are already there,
we're just going to baseline it and move the changes. So if you have to reed and the bits and bytes are already there, it's just the deltas, right? So the 40 terabyte database might move a couple of gigs or whatever is not resident on that target array. So within a data center that's kind of cool between data centers or between on prem and the
cloud. That's really cool, right? Because now I can put your business back in a better dr posture a lot faster than you ever could leveraging any other database or application, application level technologies. I had a customer that had a 200 terabyte database uh six or seven years ago. And they were around 2014 and if we used SQL server to replicate the data or a backup and
restore their receiving process took 67 days. Not great. Right. What's that mean to your business? You're right. We had to do some stuff. We made it work, we got it down to like a day, but I had to do a bunch of special stuff. Right. So that's, that's a very impactful things from
a business standpoint. So, yeah, just an architectural standpoint. This is what it would look like, getting the data between arrays. Um One of my colleagues, Andrew Sullivant wrote a paper on this called uh I have it in the links, but it's an intra cloud dr we've actually taken the same pattern and put it into the Azure and Aws. So having replication for is VMS on a cloud
block store, you can do the same thing between regions or between clouds, right? So this isn't just an on prem play. It's also a hybrid or a cloud only play too cool. So the other thing that was really neat to see in 22 is SQL server now talks object, right? Native S3.
And this adds a lot of value because now I can back up to an S3 target and we had to do some, I'll talk about some crazy things that we had to do over time with regards to rapid restore scenarios. But there's two key scenarios that I talked to customers about when we're talking about rapid restore. Everyone has like the one big database, it's like core to the business and it's kind of a
pain in the butt to back up. Right. And we're gonna talk about backup tuning today and what that means. And so leveraging flash blade N S3 and lever, even on the S and B side of the house, we can get some pretty good numbers of backing up a giant database fast, but more importantly, restoring the database fast. But one of the patterns that people I think or I forget to think about is when you're looking
at a large enterprise state of database and database instances or platform. What's the, what's a challenging thing to do is getting all your backups done in your backup window, right? And if you run all your backups and something goes wrong, you have to rerun a backup and it maybe bleeds into the business day.
Right. What's that? It's gonna do is gonna make end user sad, right? And who likes making end user sad? Right. And so a practical story is last summer. Uh One of our customers did a POC with this platform, they literally had four arrays of just four servers just packed full of js sds. They would land all their backups in there and
then they'd replicate them in the S3 and they had the that challenge. They had a hard time of getting everything done within their backup window literally took that code and just pointed it at a single flash blade and it reduced their backup window by four, right. So even if something went wrong, just run another backup and it's not going to bleed into
the business day. And then with the native replication of the device that was going in, it was going into S3 without any external tool and they had to write or use some crazy uh S3 file system mounts to r the things into the cloud. And so that became really valuable to them. The other thing that became very valuable to them is a single name space. All the backups are in one spot,
right? Rather than having to be load balanced across four because it had a basically like a shock absorber pattern into the storage. And so we help them solve two problems, right? Get the data off the primary storage and get it out of the data center as fast as possible, bringing qat to the party. Same thing, we're gonna have some high throughput with offloaded CPU even in the S3
object side of the house. And so uh at the bottom here, I do have a link that walks you through kind of the, the details of what that looks like. So the cool part about my job is I get to do things like this. Uh So I get some, I got a private preview of SQL server.
I got a brand new flash blade last summer. What are we gonna do? We're gonna do some testing, right? And so we put together a test suite. Uh It was a s 500 single chassis s 508 by 100 gigabit connected. And we had eight physical servers, all running VM ware,
but eight VM. So each VM on top of that, on each dedicated host and we ran a couple of scenarios, we ran a single SQL server database backup and we got eight terabytes an hour on backup, 12 terabytes an hour on restored. And so I showed my previous manager this chart and I'm like, look 62 terabytes an hour. That's cool.
And she was like, that's a terabyte a minute. I'm like, that's hot, right? But there's a couple of things I wanted to point out here. So these two charts are equal the backup and restart time. And generally you have one, either backups are really good or restarts are really good,
right? You don't get both and now you get both. And in this particular implementation, we actually ran out of compute, driving the workload. So we could have brought more VM host to the party to drive that number even further. Uh I know that the flash blade team gets a lot sicker numbers out of a flash blade, but this is literally SQL server,
native backups. No external tools, nothing special is happening except the fact that it was running over S3, right? Cool. Let's talk about how to do that, right. We're gonna get into some nerdy stuff about how SQL server backs up and how we have to deal with some legacy architectural decisions from SQL server,
even in this modern uh object storage platform that we're gonna be digging into today. Uh This syntax here is really, really powerful actually. So backup database T PC C 102 disc equals no, all that's gonna do is read the data from the database as fast as possible and throw it out. What does that tell me about my system?
It's as fast as I can read data. So that's my upper boundary. Like that's my what I want to shoot for when I'm tuning right and this is single threaded. So if I add a comma after null and just add more to dis equals null, that's going to bring more reader threads to the party under certain conditions which you talk about. How many of those do I want to try?
How many cores are in my server? Right? That's what I want to know because now I'm gonna have dedicated reader threads balanced across all of the CP us in my platform. So that's gonna be tell me how fast I can literally read the bits and bytes off of the disk. I'm gonna hit a upper boundary somewhere.
There's gonna be a bottleneck. It's either gonna be cores, network infrastructure, storage infrastructure, right? Something along the way is gonna choke. Right. And that's OK. Right. That's just your capabilities in your platform. And now you know what your, your upper boundary is to tune for when you start writing data out.
Right. And so what we get when we execute that statement is we read from the database on a reader thread, writes in a buffer and it writes into the backup file. Right? So now I'm going to get a reader thread and a writer thread, but flash blade thrives in concurrency, right?
So I want to bring more concurrency to the party when I do this. And so there's an architectural decision by Microsoft for eons ago that I'll only get one reader thread per volume. OK? And so what we wind up having to do with something like this as a DB A, I'm gonna take a database and I'm gonna split it across multiple
volumes. Now, this is the case where I want to drive insane concurrency out of a single database backup. OK? So I have multiple reader threads on the source side and I write the multiple backup files. So you can see that spread across here. And so now what I'm able to do is start driving concurrency reading and writing in a parallel
fashion. And this is where you're going to start to see some pretty cool gains. A lot of D BS do this. Well, they'll write the multiple files but they'll still, they won't do that on the left. Now, I'm not suggesting do this for every database in your, in your platform, right? Because this brings configuration complexity to
your systems, which isn't great. But in the condition that you need this kind of io this is the strategy that you're gonna take. I've been begging Microsoft P MS for about two years to give me a knob on the left. So let me define reader threads not tied to the number of volumes on my system. And so when I'm done, I'm left with something that looks like this,
right? I have a backup running. In this case, it's going to be to SMB split across multiple data VIPs across multiple backup files. And that's how I'm able to drive the concurrency reading from the source system driving to uh the target system S3, which I think is great. No external tools.
The only real change I have to make is the actual uh path, right? URL equals instead of disc equals. And then what I'm writing to since it's S3, I don't have to mess around with having multiple data VIPs anymore, which is what I would have to do because of the architecture of SMB that's going to be dangerous. A couple of nerd knobs though that you're going
to have to look at uh you'll get concurrency out of the threads. Each one of those threads will be independent TCP stream compression is going to be turned on by default if you define a max transfer size. And this is a very large number max transfer size used to cap out at four megabytes. That's 20 megabytes.
Uh And what that's going to do is read in larger chunks and write in larger chunks. And that's going to be a knob that you're gonna have to turn for this because S3 has a max object size when you're working with large databases or large files. If you don't do anything, the largest object size will be 100 gigabytes. But as a backup file.
So leveraging this pattern here, the largest backup set is 12.7 terabytes. So if you're using the backup D RL for a blob, you're probably familiar with that. If you're using um S3, that's the case here. I saw cringe 12.7 terabytes of backup data, right? Not source data, right? So compressed and then packed in what's up four
L the uh no, that will be the total. So you can have 64 URL S in total, which is where you'll get the 12.7 terabytes in total. So uh depending on what the compression ratio is of the source database, right? I know I know how big sp 18 terabytes of source data or backup data.
So that'll compress down probably to a lot less than that depending on what the source data is. And if it's not compressed already, if you talk to, OK, let's talk about it. Um, you're from my neck of the woods, right? Ok. Yeah. Yeah. Um yeah, so don't get scared by that. It's 12 terabytes of 12.7 terabytes of backup
data, not of source data to make that clear. So I just spent a whole lot of time talking a lot about concurrency out of a single database. But I think the real way to get concur concurrency out of a platform is if you looked at that original chart, what would we, what do we do? We run eight backups at the same time and that's the luxury that flash blade brings to
the party is you don't have to worry about saturating your backup target anymore. You can kick off 5, 10 50 instances of backups at the same time and Flash Blade just gonna deal with it as long as your network infrastructure is plumbed out in a way to support that kind of workload. And so that gets to that, that's for me really is the special sauce,
right? I'm going to do this every once in a while for the the one database that might be the pain. But the ability to shrink the backup window by having concurrency at the instance level is really the superpower there. Cool. This is actually something I want to play with so much.
But they have me doing other things, data virtualization or the ability to take SQL server and go read data from something else. Why is that important because your developers know T sequel, right? They know how to write reports in T sequel, then how to interact with the database. And so now I can, in the database level, I can access data wherever it lives,
right? So if I have a system that generates data and sticks it into object, well, I can write code, I can write T SQL code to bring that data in to the database engine. Now with no external tools, right? I have to go buy a thing and support a product, have another maintenance contract, learn another platform to bring that data into SQL
server. And the if I can land that data into object, the file formats that are supported today are CS V and DELTA, which are kind of standard file formats for machine generated data and also archiving data over time. And in the data science community, we can also read from other database engines, right?
So now I have this thing, the SQL server, it's kind of this data hub where my developers can go and they can access data that's an object in all those different file formats or any other what's called a poly bases enabled data source. So had doop oracle anything that's OD BC, right? So now I have this sequel server that can go get data wherever it is and bring that data in.
But the other thing that I think is really cool about this integration is the fact that it's already using tools and to tools and techniques that your user community is probably already familiar with, I think called open rows, set or external table, right? So I don't have to go and write code to read the thing. I just say external table, I define its
location on my network. I off to it and now I just have a table. It's like you can just select star from whatever and it'll read that data off of S3. And I don't have to have any external tools to do that. And then as data is generated, I don't have to go and refresh anything, it'll read it at run time. So as new stuff shows up and I go and access
that external table, I just go read that data at that point in time. This one I wanted to uh I think it is going to be another game changing piece of the S3 integration is how many of us have a database with transactions in it from like 1997 right? How much value does that add to your business? Right. Maybe somebody once a year runs a report,
it might hit that table, right? Or it might hit that part of that table. And so with this, there's a new syntax that was added to SQL server called create external table as select or uh or if you're from Texas, um that's actually a debate on how to actually pronounce that. But what we can do with this table or this
integration is this, I can take those rows, I can write a select statement and say, give me all this stuff from 1997 and stick it in this external table as parquet right now. It's an object and it's not on the hot and fast block storage, right? So what does that mean to you? Now, when I run a backup, I'm backing up the stuff that's important to me right now,
but I still have that data, which I would also protect by backing it up an object, right? With other other techniques. And so that simplifies kind of your data strategy over time because your developers and DB A s probably have to use, use things like partitioning or uh uh heavy indexing to get around the fact that they had all this old stuff sitting in a database.
And so we're adding simplicity by just taking what's less important data and sticking it over there or aged mature data and sticking it over there. And so the idea here is we can then build the database platform and focus on what's most important, which is the recent stuff. And when I do go access the stuff from 1997 I don't have to change code. It's just going to be an external table which I
can bring together and present back to the users. They would literally never know the engine handles the plumbing underneath before you. When I say engine, I mean, specifically SQL server. Cool. The other part about that talk a lot about is if I had 1997 1998 1999 I can take that data and I can put that in a different parquet files
and then I'll have to read all of that at once. And so at the bottom here, we can traverse, not we, but SQL server can traverse that file data underneath and figure out and eliminate what it doesn't need. So we'll get some performance benefits out of that. Cool. Now, when I see this or, or from an implementation standpoint, if you're installing SQL server 22 you do have to do some things you
have to install and enable poly base, right? Which is uh just the check box when you're installing SQL server, which I don't actually install in the anymore. It's just an option. You can feed in at the command line, you need a database and you create what's called a database scoped credential. That scoped credential is basically the API key
to talk to the S3 store, right? So in this case, that would come from your flash blade, you create an external data source, uh which is gonna define the network location plus the credential, right? Simple as that. And then when I create the external table or external file format,
that's going to define what I'm reading par K CS V delta, right? Uh Parque and delta are fixed format. I don't have any control of the scheme is built into the actual file format. But it's, if it's CS V, I have to define the structure, right? And that would be some really hairy t sequel syntax if you've ever done that for um open
rows, and then I can access the data, either ad hoc with open a row set or I can define what's called an external table and it lives as any other object. So you can literally type select star from whatever the table name is and it'll read it from object, right? So your developers don't have any friction on getting access to that data.
And then from there, if I need to create external table as select, I would just select from insert to the external table. So that surface area is literally as easy as reading from one table and sticking it in another. So I end it a little quickly. So I'll just open it up for Q and A for y'all. We've got about 10 minutes left.
So.
SQL Server 2022 has innovative features that enhance performance, scalability, and availability. This demo-heavy session explores the latest innovations, including using storage-based snapshots for data protection and building Always On availability groups. You'll learn about the latest SQL features, how to perform application-consistent backup and restore using snapshots, and enabling data virtualization using S3 object storage.
We Also Recommend...
Personalize for Me