Dismiss
Inovação
Uma plataforma criada para IA
Unificado, automatizado e pronto para transformar dados em inteligência.
Dismiss
16-18 juni, Las Vegas
Pure//Accelerate® 2026
Ontdek hoe u de ware waarde van uw gegevens kunt ontsluiten.
Computação paralela x distribuída: Uma visão geral
A computação paralela e distribuída é a base da computação moderna de alto desempenho (HPC, High- Performance Computing), da análise de dados e da inteligência artificial (AI, Artificial Intelligence ). Embora relacionadas, são abordagens distintas com diferentes arquiteturas, vantagens e demandas de armazenamento.
Neste artigo, exploraremos as diferenças fundamentais entre computação paralela e distribuída, e como o Everpure dá suporte a ambos com soluções de armazenamento inovadoras, como o Everpure FlashBlade® e o mais novo membro da família FlashBlade, o FlashBlade//EXA .
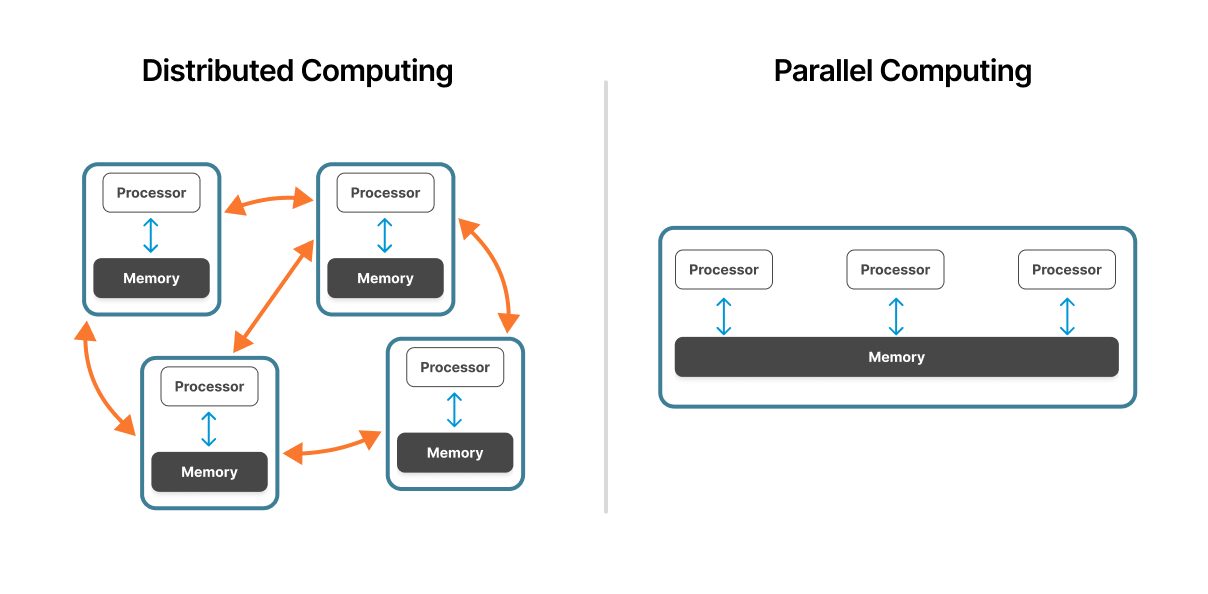
Figura 1: Um sistema de computação distribuído em comparação com um sistema de computação paralela.
Fonte: ResearchGate
O que é computação paralela?
A computação paralela envolve dividir uma tarefa em subtarefas menores que são processadas simultaneamente em vários processadores ou núcleos em um único sistema.
Exemplos tradicionais incluem:
- Modelagem climática
- Pesquisa sísmica
- Astrofísica computacional
Nos últimos anos, a computação paralela evoluiu além do processamento multinúcleo baseado em CPU para modelos acelerados por GPU. Agora, os workloads avançados de AI/ML dependem muito de arquiteturas de GPU extremamente paralelas, como NVIDIA A100 ou H100, que permitem aprendizagem profunda, processamento de linguagem natural e visão computacional em grande escala.
A computação paralela também está no centro de inovações, como computação quântica e sistemas neuromórficos, que emulam arquiteturas neurais para processar dados com mais eficiência. Até mesmo dispositivos móveis e de borda agora incorporam recursos de processamento paralelo para dar suporte à AI em tempo real na borda.


O que é computação distribuída?
A computação distribuída espalha tarefas em várias máquinas, muitas vezes em diferentes locais físicos, conectadas em rede para funcionar como um único sistema. Cada nó lida com uma parte da carga de trabalho e comunica os resultados de volta a um sistema central.
Exemplos incluem:
- Plataformas MapReduce e Big Data, como Apache Hadoop e Spark
- Renderização distribuída em animação/VFX
- Simulações com vários agentes em design aeroespacial e automotivo
Arquiteturas distribuídas são comuns em computação em nuvem, ambientes de borda e sistemas IoT de grande escala, onde escalabilidade e distribuição geográfica são essenciais.
As linhas entre a computação paralela e a computação distribuída estão cada vez mais turvas em implantações modernas de HPC e AI, onde as arquiteturas desagregadas aproveitam ambas as abordagens simultaneamente. Essa convergência impulsiona a demanda por plataformas de armazenamento que suportem alta largura de banda, baixa latência e grande simultaneidade.
Paralelo x distribuído: Principais diferenças
Embora ambas as abordagens dividam problemas complexos em tarefas menores, elas diferem fundamentalmente em arquitetura e implementação.
Arquitetura do sistema
A computação paralela opera em uma única máquina ou em um cluster bem acoplado. Vários processadores compartilham acesso ao mesmo hardware físico com arquitetura de memória unificada, permitindo uma comunicação rápida entre as unidades de processamento.
A computação distribuída abrange vários computadores independentes conectados por rede. Cada node opera de forma autônoma com seus próprios processadores, memórias e Operating System, coordenando por meio de protocolos de rede.
Organização de memória
Em sistemas paralelos, os processadores compartilham um espaço de memória comum. Essa arquitetura de memória compartilhada permite troca rápida de dados: os processadores leem e gravam nos mesmos locais de memória. No entanto, esse recurso compartilhado pode se tornar um gargalo à medida que a contagem de processadores aumenta.
Sistemas distribuídos usam memória independente em cada nó. Os nós se comunicam passando mensagens contendo os dados necessários. Esse modelo de memória distribuída elimina a contenção de memória, mas apresenta sobrecarga de comunicação de rede.
Métodos de comunicação
A computação paralela depende de interconexões ou barramentos internos de alta velocidade. A comunicação acontece na velocidade da memória: nanossegundos para transferências de cache para cache, microssegundos para acesso à memória principal. Essa baixa latência torna os sistemas paralelos ideais para problemas fortemente acoplados que exigem coordenação frequente.
Sistemas distribuídos se comunicam por meio de protocolos de rede. A comunicação de rede introduz latência, normalmente medida em milissegundos, dependendo da distância geográfica. Isso significa que os sistemas distribuídos funcionam melhor para problemas acoplados livremente onde as tarefas operam de forma independente.
Escalabilidade
A computação paralela expande verticalmente, adicionando mais processadores a um único sistema. Essa abordagem atinge limites físicos: restrições de largura de banda de memória, limitações térmicas e contenção de barramento. A maioria dos sistemas paralelos se expande para centenas de núcleos.
A computação distribuída expande horizontalmente, adicionando mais máquinas à rede. Os sistemas podem crescer de alguns nós para milhares de máquinas. As plataformas de nuvem normalmente operam sistemas distribuídos em datacenters em todo o mundo.
Tolerância a falhas
Sistemas paralelos normalmente representam um único ponto de falha. Se a máquina falhar, todo o cálculo será interrompido.
Sistemas distribuídos oferecem tolerância inerente a falhas. Quando um nó falha, outros nós continuam processando. Sistemas distribuídos bem projetados detectam falhas, reatribuem trabalhos e mantêm a operação conforme máquinas individuais ficam off-line.
Distribuição geográfica
A computação paralela concentra o processamento em um único local. Todos os processadores residem no mesmo datacenter, conectados pela infraestrutura local.
A computação distribuída permite a distribuição geográfica. Os nós podem operar em diferentes cidades ou continentes, dando suporte a casos de uso, como redes de entrega de conteúdo e conformidade com os regulamentos de residência de dados.
As linhas entre a computação paralela e a computação distribuída estão cada vez mais turvas em implantações modernas de HPC e AI , onde as arquiteturas desagregadas aproveitam ambas as abordagens simultaneamente.
Aplicativos avançados de computação paralela
Além da computação científica tradicional, o paralelismo potencializa muitas cargas de trabalho avançadas:
- AI e Machine Learning: Treinamento de grandes modelos usando paralelismo de dados em clusters de GPU
- Análise em tempo real: Detecção de fraude, direção autônoma e mecanismos de recomendação ao vivo
- Negociação de alta frequência: Processamento de transações de latência ultrabaixa
- Mineração de criptomoedas: Validação eficiente de hash e consenso
- Aeroespacial e energia: Simulações multifísicas e modelagem preditiva
O Everpure dá suporte a esses setores com plataformas de dados capazes de sustentar largura de banda de vários terabytes por segundo em clusters de computação altamente paralelos.
Tendências de convergência e modelos híbridos
As cargas de trabalho modernas usam cada vez mais modelos híbridos que combinam computação paralela e distribuída, por exemplo, uma estrutura de treinamento distribuída, como Horovod ou PyTorch Lightning, executada em um cluster de GPU usando métodos paralelos de dados.
O FlashBlade e o mais novo membro da família FlashBlade, FlashBlade//EXA, são exclusivamente adequados a esses ambientes. Com suporte para cargas de trabalho simultâneas mistas, acesso a vários protocolos (NFS, S3) e escalabilidade elástica, eles eliminam a necessidade de rearquitetar sistemas de armazenamento para cada paradigma de computação.
O papel do armazenamento na computação paralela e distribuída
Não importa o quanto seus processadores sejam potentes, eles são tão eficazes quanto os fluxos de dados que os alimentam. Os gargalos de armazenamento são frequentemente o fator limitante em ambientes paralelos e distribuídos.
O FlashBlade e o mais novo membro da família FlashBlade, o FlashBlade//EXA, foram desenvolvidos para superar essas limitações com:
- Desempenho de alta taxa de transferência e latência ultrabaixa
- Paralelismo em massa entre milhares de clientes simultâneos
- Expanda o armazenamento de arquivos e objetos para AI, análise e HPC
Essas plataformas são compatíveis com paralelismo de memória compartilhada (para farms de GPU e processadores tensores) e acesso a arquivos distribuídos (para fluxos de trabalho de AI/ML, genômica e simulação em larga escala).
Conclusão
Entender as diferenças entre computação paralela e distribuída é essencial para a arquitetura da infraestrutura avançada de dados. A computação paralela oferece desempenho máximo para cargas de trabalho fortemente acopladas que exigem comunicação de latência ultrabaixa em um único sistema. A computação distribuída oferece escalabilidade e tolerância a falhas ilimitadas para problemas acoplados livremente que abrangem várias máquinas ou regiões geográficas.
A escolha entre essas abordagens depende dos seus requisitos específicos. Quando as tarefas precisam de coordenação frequente e tempos de resposta inferiores a milissegundos, as arquiteturas paralelas se destacam. Quando os aplicativos precisam expandir horizontalmente, tolerar falhas com carência ou processar dados em locais distribuídos, os sistemas distribuídos são a resposta. Muitas cargas de trabalho modernas aproveitam ambas, usando clusters paralelos de GPU em infraestruturas de nuvem distribuída.
O desempenho do armazenamento determina se sua infraestrutura de computação atinge seu potencial. Não importa quão potentes sejam seus processadores, eles são tão eficazes quanto os fluxos de dados que os alimentam. O FlashBlade e o FlashBlade//EXA eliminam gargalos de armazenamento com desempenho de alta taxa de transferência e latência ultrabaixa, desenvolvidos para arquiteturas paralelas e distribuídas. Eles são compatíveis com a enorme simultaneidade, cargas de trabalho mistas e escalabilidade elástica que a HPC, AI e a análise de dados exigem.
Pronto para eliminar gargalos de armazenamento? Explore as soluções FlashBlade ou entre em contato com o Everpure para discutir sua arquitetura de computação específica.
Também recomendamos…
Confira os principais recursos e eventos

FEIRA DE NEGÓCIOS
Pure//Accelerate® 2.026
June 16-18, 2026 | Resorts World Las Vegas
Prepare-se para o evento mais valioso do ano.

DEMONSTRAÇÕES SOBRE O PURE360
Explore, conheça e teste a Everpure.
Acesse vídeos e demonstrações sob demanda para ver do que a Everpure é capaz.

VÍDEO
Assista: O valor de um Enterprise Data Cloud.
Charlie Giancarlo sobre o por que de gerenciar dados — e não o armazenamento — é o futuro. Descubra como uma abordagem unificada transforma as operações de TI corporativas.

RECURSO
O armazenamento legado não pode potencializar o futuro.
Cargas de trabalho avançadas exigem velocidade, segurança e escala compatíveis com a IA. Sua pilha está pronta?
Personalize for Me