Dismiss
Innovación
Una plataforma diseñada para la IA
Unificada, automatizada y preparada para convertir los datos en inteligencia.
Dismiss
16-18 de junio, Las Vegas
Pure//Accelerate® 2026
Descubra cómo extraer el verdadero valor de sus datos.
Computación paralela frente a distribuida: Una descripción general
La informática paralela y distribuida es fundamental para la informática moderna de alto rendimiento (HPC), los análisis de datos y la Artificial Intelligence artificial (IA). Aunque están relacionadas, son enfoques distintos con diferentes arquitecturas, ventajas y demandas de almacenamiento.
En este artículo, exploraremos las diferencias fundamentales entre la computación paralela y la distribuida y cómo Everpure admite ambas soluciones de almacenamiento innovadoras, como Everpure FlashBlade® y el miembro más nuevo de la familia FlashBlade, FlashBlade//EXA™.
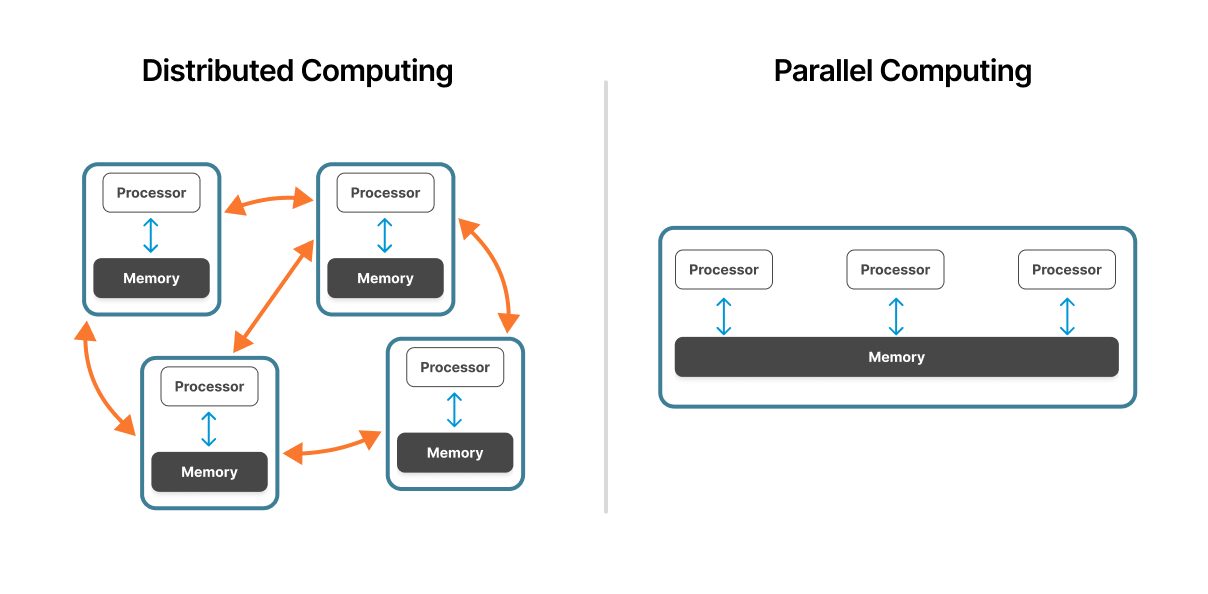
Figura 1: Un sistema informático distribuido comparado con un sistema informático paralelo.
Fuente: ResearchGate
¿Qué es la computación paralela?
La computación paralela implica dividir una tarea en subtareas más pequeñas que se procesan simultáneamente en múltiples procesadores o núcleos dentro de un único sistema.
Algunos ejemplos tradicionales son:
- Modelado climático
- Estudios sísmicos
- Astrofísica computacional
En los últimos años, la computación paralela ha evolucionado más allá del procesamiento multinúcleo basado en CPU y se ha convertido en modelos acelerados por GPU. Las cargas de trabajo de IA/ML modernas ahora dependen en gran medida de arquitecturas de GPU masivamente paralelas, como NVIDIA A100 o H100, que permiten el deep learning, el procesamiento del lenguaje natural y la visión artificial a escala.
La computación paralela también es el centro de innovaciones como la computación cuántica y los sistemas neuromórficos, que emulan las arquitecturas neuronales para procesar los datos de manera más eficiente. Incluso los dispositivos móviles y perimetrales ahora incorporan funcionalidades de procesamiento paralelo para soportar la IA en tiempo real en el borde.


¿Qué es la computación distribuida?
La computación distribuida distribuye las tareas en múltiples máquinas —a menudo en diferentes ubicaciones físicas— conectadas en red para funcionar como un único sistema. Cada nodo maneja una parte de la carga de trabajo y comunica los resultados a un sistema central.
Ejemplos de ello son:
- MapReduce y plataformas de macrodatos como Apache Hadoop y Spark
- Representación distribuida en animación/VFX
- Simulaciones multiagente en diseño aeroespacial y automovilístico
Las arquitecturas distribuidas son comunes en la computación en la nube, los entornos perimetrales y los sistemas de IoT a gran escala, donde la escalabilidad y la distribución geográfica son esenciales.
Las líneas entre la informática paralela y la distribuida están cada vez más borrosas en las implementaciones modernas de HPC e IA, en las que las arquitecturas desagregadas aprovechan ambos enfoques simultáneamente. Esta convergencia impulsa la demanda de plataformas de almacenamiento que admitan un gran ancho de banda, una baja latencia y una concurrencia masiva.
Paralelo frente a Distribuido: diferencias clave
Si bien ambos enfoques desglosan los problemas complejos en tareas más pequeñas, difieren fundamentalmente en arquitectura e implementación.
Arquitectura del sistema
La computación paralela funciona en una sola máquina o en un clúster estrechamente acoplado. Varios procesadores comparten el acceso al mismo hardware físico con una arquitectura de memoria unificada, lo que permite una comunicación rápida entre las unidades de procesamiento.
La computación distribuida abarca múltiples ordenadores independientes conectados a través de la red. Cada nodo funciona de manera autónoma con su propio procesador, memoria y Operating System, coordinando mediante protocolos de red.
Organización de memoria
En los sistemas paralelos, los procesadores comparten un espacio de memoria común. Esta arquitectura de memoria compartida permite un intercambio rápido de datos —los procesadores leen y escriben en las mismas ubicaciones de memoria—. Sin embargo, este recurso compartido puede convertirse en un cuello de botella a medida que aumenta el recuento de procesadores.
Los sistemas distribuidos utilizan memoria independiente en cada nodo. Los nodos se comunican transmitiendo mensajes que contienen los datos necesarios. Este modelo de memoria distribuida elimina la contención de la memoria, pero introduce la sobrecarga de comunicación de red.
Métodos de comunicación
La computación paralela se basa en buses internos o interconexiones de alta velocidad. La comunicación se produce a la velocidad de la memoria —nanosegundos para las transferencias de caché a caché, microsegundos para el acceso a la memoria principal—. Esta baja latencia hace que los sistemas paralelos sean ideales para los problemas estrechamente acoplados que requieren una coordinación frecuente.
Los sistemas distribuidos se comunican a través de protocolos de red. La comunicación en red introduce latencia, que normalmente se mide en milisegundos, en función de la distancia geográfica. Esto significa que los sistemas distribuidos funcionan mejor para los problemas que están unidos de manera vaga y en los que las tareas funcionan de manera independiente.
Escalabilidad
La computación paralela se escala verticalmente, añadiendo más procesadores a un solo sistema. Este enfoque alcanza límites físicos: limitaciones de ancho de banda de memoria, limitaciones térmicas y contención de bus. La mayoría de los sistemas paralelos se escalan a cientos de núcleos.
La computación distribuida se escala horizontalmente, añadiendo más máquinas a la red. Los sistemas pueden pasar de unos pocos nodos a miles de máquinas. Las plataformas en la nube operan de manera rutinaria sistemas distribuidos que abarcan centros de datos de todo el mundo.
Tolerancia a fallos
Los sistemas paralelos suelen representar un único punto de fallo. Si la máquina falla, todo el cálculo se detiene.
Los sistemas distribuidos ofrecen una tolerancia a los fallos inherente. Cuando un nodo falla, otros nodos continúan procesando. Los sistemas distribuidos bien diseñados detectan los fallos, reasignan el trabajo y mantienen el funcionamiento a medida que las máquinas individuales se desconectan.
Distribución geográfica
La computación paralela concentra el procesamiento en una única ubicación. Todos los procesadores residen en el mismo centro de datos, conectado por una infraestructura local.
La computación distribuida permite la distribución geográfica. Los nodos pueden operar en diferentes ciudades o continentes, lo que admite casos de uso como las redes de entrega de contenido y el cumplimiento de las normativas de residencia de los datos.
Las líneas entre la informática paralela y la distribuida están cada vez más borrosas en los despliegues modernos de HPC e IA , en los que las arquitecturas desagregadas aprovechan ambos enfoques simultáneamente.
Aplicaciones modernas de computación paralela
Más allá de la informática científica tradicional, el paralelismo impulsa muchas cargas de trabajo de vanguardia:
- IA y aprendizaje automático: Entrenar modelos grandes usando paralelismo de datos en clústeres GPU
- Análisis en tiempo real: Detección de fraudes, conducción autónoma y motores de recomendación en directo
- Comercio de alta frecuencia: Procesamiento de transacciones de latencia ultrabaja
- Minería de criptomonedas: Validación eficiente de hash y consenso
- Aeroespacial y energía: Simulaciones multifísicas y modelado predictivo
Everpure admite estos sectores con plataformas de datos capaces de mantener un ancho de banda de múltiples terabytes por segundo en clústeres de computación muy paralelos.
Modelos híbridos y tendencias convergentes
Las cargas de trabajo modernas utilizan cada vez más modelos híbridos que combinan computación paralela y distribuida —por ejemplo, un marco de entrenamiento distribuido como Horovod o PyTorch Lightning que se ejecuta en un clúster de GPU usando métodos paralelos a los datos—.
FlashBlade y el miembro más nuevo de la familia FlashBlade, FlashBlade//EXA, son especialmente adecuados para estos entornos. Con compatibilidad con cargas de trabajo mixtas concurrentes, acceso multiprotocolo (NFS, S3) y escalabilidad elástica, eliminan la necesidad de rediseñar los sistemas de almacenamiento para cada paradigma informático.
El papel del almacenamiento en la computación paralela y distribuida
No importa lo potentes que sean sus procesadores, son tan efectivos como los pipelines de datos que los alimentan. Los cuellos de botella del almacenamiento suelen ser el factor limitante tanto en entornos paralelos como distribuidos.
FlashBlade y el miembro más nuevo de la familia FlashBlade, FlashBlade//EXA, están diseñados para superar estas limitaciones con:
- Rendimiento de alto rendimiento y latencia ultrabaja
- Paralelismo masivo entre miles de clientes simultáneos
- Almacenamiento de archivos y objetos escalable horizontalmente creado para IA, analíticas y HPC
Estas plataformas admiten tanto el paralelismo de memoria compartida (para granjas de GPU y procesadores tensores) como el acceso a archivos distribuidos (para IA/ML a gran escala, genómica y flujos de trabajo de simulación).
Conclusión
Comprender las diferencias entre la computación paralela y la distribuida es esencial para diseñar una infraestructura de datos moderna. La computación paralela proporciona el máximo rendimiento para las cargas de trabajo estrechamente acopladas que requieren una comunicación de latencia ultrabaja dentro de un único sistema. La computación distribuida proporciona una escalabilidad y una tolerancia a fallos ilimitadas para los problemas que se encuentran unidos de manera vaga en múltiples máquinas o regiones geográficas.
La elección entre estos enfoques depende de sus requisitos específicos. Cuando las tareas necesitan una coordinación frecuente y unos tiempos de respuesta de submilisegundos, las arquitecturas paralelas sobresalen. Cuando las aplicaciones tienen que escalarse horizontalmente, tolerar los fallos con gracia o procesar los datos en ubicaciones distribuidas, los sistemas distribuidos son la respuesta. Muchas cargas de trabajo modernas aprovechan ambas —utilizando clústeres de GPU paralelos dentro de infraestructuras de nube distribuida.
El rendimiento del almacenamiento determina si su infraestructura de computación alcanza su máximo potencial. No importa lo potentes que sean sus procesadores, son tan efectivos como los pipelines de datos que los alimentan. FlashBlade y FlashBlade//EXA eliminan los cuellos de botella del almacenamiento con un rendimiento de alto rendimiento y ultrabaja latencia diseñado para arquitecturas paralelas y distribuidas. Admiten la concurrencia masiva, las cargas de trabajo mixtas y la escalabilidad elástica que exigen las HPC modernas, la IA y los análisis de datos.
¿Está preparado para eliminar los cuellos de botella del almacenamiento? Explore las soluciones FlashBlade o contacte con Everpure para hablar de su arquitectura informática específica.
Te recomendamos...
Explore los recursos y eventos clave

FERIA COMERCIAL
Pure//Accelerate® 2026
June 16-18, 2026 | Resorts World Las Vegas
Prepárese para el evento más valioso al que asistirá este año.

DEMOS DE PURE360
Explore, aprenda y experimente Everpure.
Acceda a vídeos y demostraciones bajo demanda para ver lo que Everpure puede hacer.

VÍDEO
Ver: El valor de Enterprise Data Cloud.
Charlie Giancarlo explica por qué la gestión de los datos —y no del almacenamiento— es el futuro. Descubra cómo un enfoque unificado transforma las operaciones de TI de la empresa.

RECURSO
El almacenamiento tradicional no puede impulsar el futuro.
Las cargas de trabajo modernas exigen velocidad, seguridad y escala preparadas para la IA. ¿Su stack está listo?
Personalize for Me