Les frontières entre l’informatique parallèle et l’informatique distribuée sont de plus en plus floues dans les déploiements HPC et d’AI modernes, où les architectures désagrégées exploitent les deux approches simultanément. Cette convergence stimule la demande de plateformes de stockage qui prennent en charge une bande passante élevée, une latence faible et une simultanéité massive.
Parallèle ou distribué : principales différences
Bien que les deux approches décomposent les problèmes complexes en tâches plus petites, elles diffèrent fondamentalement en termes d’architecture et de mise en œuvre.
Architecture du système
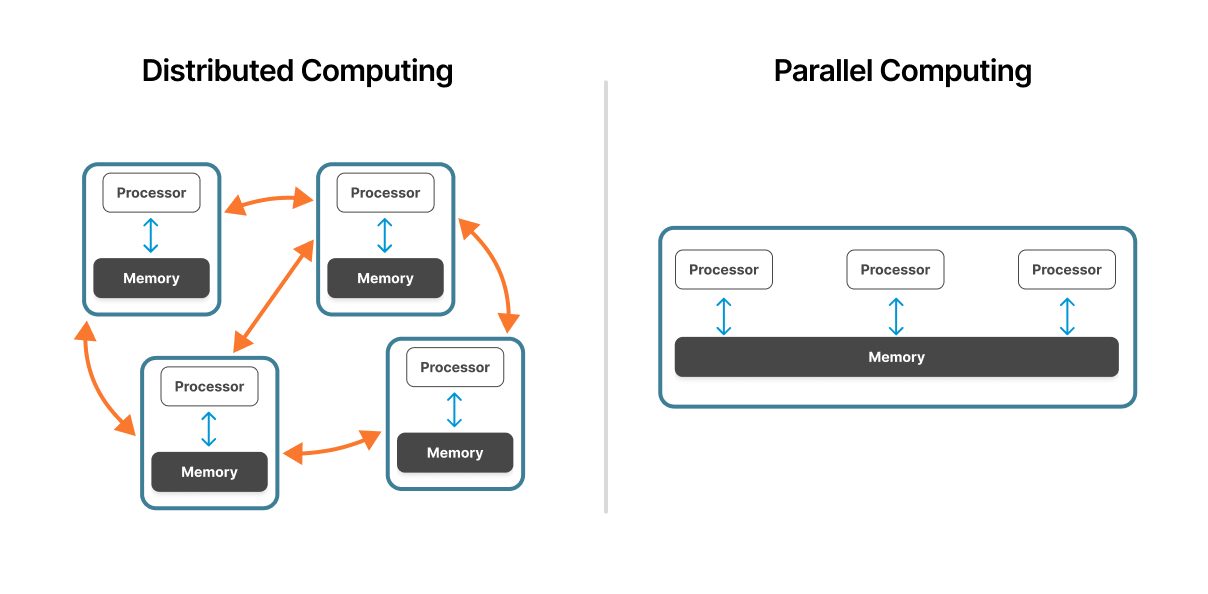
L’informatique parallèle fonctionne au sein d’une seule machine ou d’un cluster étroitement couplé. Plusieurs processeurs partagent l’accès au même matériel physique avec une architecture de mémoire unifiée, ce qui permet une communication rapide entre les unités de traitement.
L’informatique distribuée couvre plusieurs ordinateurs indépendants connectés via le réseau. Chaque nœud fonctionne de manière autonome avec son propre processeur, sa propre mémoire et son propre Operating System, en assurant la coordination via des protocoles réseau.
Organisation de la mémoire
Dans les systèmes parallèles, les processeurs partagent un espace mémoire commun. Cette architecture de mémoire partagée permet un échange de données rapide : les processeurs lisent et écrivent sur les mêmes emplacements de mémoire. Cependant, cette ressource partagée peut devenir un goulet d’étranglement à mesure que le nombre de processeurs augmente.
Les systèmes distribués utilisent une mémoire indépendante sur chaque nœud. Les nœuds communiquent en transmettant des messages contenant les données nécessaires. Ce modèle de mémoire distribuée élimine les conflits de mémoire, mais introduit des frais de communication réseau.
Méthodes de communication
L’informatique parallèle repose sur des bus ou des interconnexions internes haute vitesse. La communication se fait à la vitesse de la mémoire : des nanosecondes pour les transferts de cache à cache, des microsecondes pour l’accès à la mémoire principale. Cette faible latence rend les systèmes parallèles parfaits pour les problèmes étroitement liés nécessitant une coordination fréquente.
Les systèmes distribués communiquent via des protocoles réseau. La communication réseau introduit une latence, généralement mesurée en millisecondes, en fonction de la distance géographique. Cela signifie que les systèmes distribués fonctionnent mieux pour les problèmes peu couplés où les tâches fonctionnent indépendamment.
Évolutivité
L’informatique parallèle évolue verticalement, ce qui permet d’ajouter davantage de processeurs à un seul système. Cette approche atteint des limites physiques : contraintes de bande passante de la mémoire, limitations thermiques et conflits entre les bus. La plupart des systèmes parallèles s’adaptent à des centaines de cœurs.
L’informatique distribuée évolue horizontalement, ce qui permet d’ajouter davantage de machines au réseau. Les systèmes peuvent passer de quelques nœuds à des milliers de machines. Les plateformes cloud exploitent régulièrement des systèmes distribués couvrant des datacenters du monde entier.
Tolérance aux pannes
Les systèmes parallèles représentent généralement un point de défaillance unique. En cas de panne de la machine, le calcul s’arrête complètement.
Les systèmes distribués offrent une tolérance aux pannes inhérente. Lorsqu’un nœud tombe en panne, les autres nœuds poursuivent le traitement. Des systèmes distribués bien conçus détectent les pannes, réaffectent le travail et maintiennent le fonctionnement lorsque des machines individuelles sont hors ligne.
Répartition géographique
L’informatique parallèle concentre le traitement sur un seul emplacement. Tous les processeurs résident dans le même datacenter, connecté par une infrastructure locale.
L’informatique distribuée permet une distribution géographique. Les nœuds peuvent fonctionner dans différentes villes ou différents continents, prenant en charge des cas d’utilisation tels que les réseaux de diffusion de contenu et la conformité aux réglementations de résidence des données.
Les frontières entre l’informatique parallèle et l’informatique distribuée sont de plus en plus floues dans les déploiements HPC et d’ AI modernes, où les architectures désagrégées exploitent les deux approches simultanément.
Applications modernes de l’informatique parallèle
Au-delà de l’informatique scientifique traditionnelle, le parallélisme alimente de nombreuses charges de travail de pointe :
- IA et apprentissage machine : Entraînement de grands modèles à l’aide du parallélisme des données entre les clusters GPU
- Analytique en temps réel : Détection des fraudes, conduite autonome et moteurs de recommandation en direct
- Négociation haute fréquence : Traitement transactionnel à ultra-faible latence
- Extraction de cryptomonnaie : Un hachage efficace et une validation par consensus
- Aérospatiale et énergie : Simulations multiphysiques et modélisation prédictive
Everpure soutient ces secteurs avec des plateformes de données capables de maintenir une bande passante de plusieurs téraoctets par seconde sur des clusters de calcul hautement parallèles.
Modèles hybrides et tendances de convergence
Les charges de travail modernes utilisent de plus en plus des modèles hybrides qui combinent l’informatique parallèle et distribuée, par exemple, un framework d’entraînement distribué comme Horovod ou PyTorch Lightning exécuté sur un cluster GPU à l’aide de méthodes de données parallèles.
FlashBlade et le dernier membre de la famille FlashBlade, FlashBlade//EXA, sont parfaitement adaptés à ces environnements. Grâce à la prise en charge de charges de travail mixtes simultanées, à l’accès multiprotocole (NFS, S3) et à l’évolutivité élastique, ils éliminent la nécessité de repenser les systèmes de stockage pour chaque paradigme informatique.
Le rôle du stockage dans l’informatique parallèle et distribuée
Quelle que soit la puissance de vos processeurs, ils sont aussi efficaces que les pipelines de données qui les alimentent. Les goulets d’étranglement du stockage sont souvent le facteur limitant dans les environnements parallèles et distribués.
FlashBlade et le dernier membre de la famille FlashBlade, FlashBlade//EXA, sont conçus pour surmonter ces limites :
- Haut débit, ultra-faible latence
- Parallélisme massif sur des milliers de clients simultanés
- Stockage de fichiers et d’objets scale-out conçu pour l’AI, l’analytique et le HPC
Ces plateformes prennent en charge à la fois le parallélisme à mémoire partagée (pour les fermes GPU et les processeurs tenseurs) et l’accès distribué aux fichiers (pour les workflows d’AI/ML, de génomique et de simulation à grande échelle).
Conclusion
Il est essentiel de comprendre les différences entre l’informatique parallèle et l’informatique distribuée pour concevoir une infrastructure de données moderne. L’informatique parallèle offre des performances maximales pour les charges de travail étroitement couplées nécessitant une communication à latence ultra-faible au sein d’un seul système. L’informatique distribuée offre une évolutivité et une tolérance aux pannes illimitées pour les problèmes peu couplés couvrant plusieurs machines ou régions géographiques.
Le choix entre ces approches dépend de vos besoins spécifiques. Lorsque les tâches nécessitent une coordination fréquente et des temps de réponse inférieurs à la milliseconde, les architectures parallèles excellent. Lorsque les applications doivent évoluer horizontalement, tolérer gracieusement les défaillances ou traiter les données sur des sites distribués, les systèmes distribués sont la réponse. De nombreuses charges de travail modernes utilisent les deux, en utilisant des clusters GPU parallèles dans des infrastructures cloud distribuées.
Les performances de stockage déterminent si votre infrastructure de calcul atteint son potentiel. Quelle que soit la puissance de vos processeurs, ils sont aussi efficaces que les pipelines de données qui les alimentent. FlashBlade et FlashBlade//EXA éliminent les goulets d’étranglement du stockage grâce à des performances haut débit et à ultra-faible latence conçues pour les architectures parallèles et distribuées. Elles prennent en charge l’énorme simultanéité, les charges de travail mixtes et l’évolutivité élastique exigées par le HPC moderne, l’AI et l’analytique de données.
Prêt à éliminer les goulets d’étranglement liés au stockage ? Explorez les solutions FlashBlade ou contactez Everpure pour discuter de votre architecture informatique spécifique.