平行與分散式運算:總覽
並行和分散式運算是現代 高效能運算 (HPC)、 資料分析和 AI 的基礎。雖然有關聯性,但它們是具有不同架構、優勢和儲存需求的不同方法。
在本文章中,我們將探討平行運算與分散式運算之間的根本差異,以及 Everpure 如何透過創新儲存解決方案,如 Everpure FlashBlade® 和 FlashBlade 系列的最新成員 FlashBlade//EXA 來支援兩者。
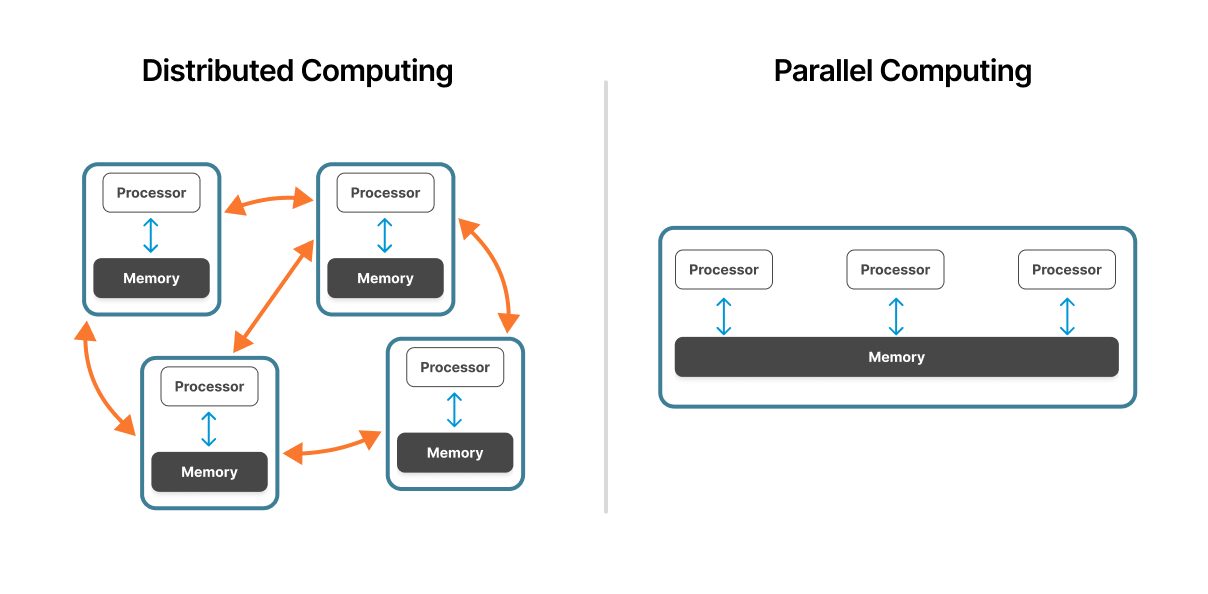
圖 1:相較於平行運算系統,分散式運算系統。
來源:ResearchGate
什麼是平行運算?
平行運算涉及將任務分解為較小的子任務,同時在單一系統中處理多個處理器或核心。
傳統範例包括:
- 氣候建模
- 地震測量
- 計算天文物理學
近年來,並行運算已經從 CPU 式多核心處理發展為 GPU 加速模型。現代 AI/ML 工作負載現在高度仰賴大規模平行 GPU 架構,例如 NVIDIA A100 或 H100,這些架構能夠大規模進行深度學習、自然語言處理和電腦視覺。
平行運算也是量子運算和神經形態系統等創新的核心,這些技術模擬神經架構,以更有效率地處理資料。即便是行動和邊緣裝置,現在也內建平行處理功能,以支援邊緣端的即時 AI。


什麼是分散式運算?
分散式運算可將任務分散到多台機器,通常分散在不同的實體位置,並連網運作,作為單一系統。每個節點處理部分工作負載,並將結果傳回中央系統。
範例包括:
- MapReduce 和大數據平台,如 Apache Hadoop 和 Spark
- 以動畫/VFX 進行分散式渲染
- 航太與汽車設計的多重代理模擬
分散式架構在 雲端運算、邊緣環境和大規模IoT系統中都很常見,因為在雲端中,擴充性和地理分佈是不可或缺的。
現代 HPC 和 AI 部署中,並行運算和分散式運算之間的界線越來越模糊,分解式基礎架構同時運用兩種方法。這種融合推動了對支援高頻寬、低延遲和大規模並行的儲存平台的需求。
平行與分散式:關鍵差異
雖然這兩種方法都能將複雜的問題分解為較小的任務,但它們在架構和實作上卻有根本上的不同。
系統架構
並行運算 可在單一機器或緊密耦合的叢集內運作。多個處理器透過整合式記憶體架構,共用相同的實體硬體,從而實現處理單元之間的快速通訊。
分散式運算涵蓋多個透過網路連線的獨立電腦。每個節點都使用自己的處理器、記憶體和作業系統自主運作,並透過網路協定進行協調。
記憶體組織
在並行系統中,處理器共享共同的記憶體空間。這種 共享記憶體架構 可實現快速的資料交換,處理器可讀寫至相同的記憶體位置。然而,隨著處理器數量的增加,這種共享資源可能會成為瓶頸。
分散式系統在每個節點使用獨立記憶體。節點透過傳遞包含所需資料的訊息進行通訊。這種分散式記憶體模式消除了記憶體的爭端,但帶來了網路通訊的負擔。
通訊方法
平行運算仰賴高速內部匯流排或互連技術。通訊以記憶體速度進行—快取至快取傳輸的毫秒數,主要記憶體存取的毫秒數。這種低延遲使平行系統成為需要頻繁協調的緊密結合問題的理想選擇。
分散式系統透過網路協定進行通訊。網路通訊帶來延遲,通常以毫秒為單位,視地理距離而定。這表示分散式系統最適合工作獨立運作時,鬆散的耦合問題。
可擴充性
平行運算垂直擴展,為單一系統新增更多處理器。這種方法達到了實體限制:記憶體頻寬限制、熱限制和匯流排爭用。大多數並行系統可擴充至數百個核心。
分散式運算水平擴展,為網路增加更多機器。系統可以從少數節點成長到數千台機器。雲端平台會定期運作橫跨全球資料中心的分散式系統。
容錯
並行系統通常代表單一故障點。如果機器故障,整個計算會停止。
分散式系統提供固有的容錯能力。當一個節點故障時,其他節點會繼續處理。精心設計的分散式系統可偵測故障、重新指派工作,並在個別機器離線時維持運作。
地理分佈
平行運算將處理集中在單一位置。所有處理器都位於同一個資料中心,由本地基礎架構連接。
分散式運算可實現地理分佈。節點可以在不同的城市或大陸運行,支援內容傳遞網路和資料居住法規的合規性等使用案例。
現代 HPC 和 AI 部署中,並行運算和分散式運算之間的界線越來越模糊,分解式基礎架構同時運用兩種方法。
平行運算的現代化應用程式
除了傳統科學運算之外,平行處理也驅動了許多尖端工作負載:
- AI 和機器學習:跨 GPU 叢集使用資料平行處理訓練大型模型
- 即時分析:詐騙偵測、自動駕駛和即時推薦引擎
- 高頻交易:超低延遲交易處理
- 虛擬加密貨幣挖礦:高效的雜湊與共識驗證
- 航太與能源:多重物理模擬和預測建模
Everpure 透過資料平台支援這些產業,能夠在高度平行的運算叢集中維持每秒多 TB 的頻寬。
混合模式與融合趨勢
現代工作負載越來越多地使用混合模式,結合平行和分散式運算,例如,使用資料平行方法在 GPU 叢集上執行的分散式訓練框架,如 Horovod 或 PyTorch Lightning。
FlashBlade 和 FlashBlade 系列的最新成員 FlashBlade//EXA 特別適合這些環境。同時支援混合工作負載、多重協定存取(NFS、S3)和彈性擴充性,因此無需重新調整儲存系統的架構,即可滿足每個運算模式的需求。
儲存系統在平行與分散式運算中扮演的角色
無論您的處理器功能有多強大,它們都只能和資料管道一樣有效。儲存瓶頸通常是平行和分散式環境中的限制因素。
FlashBlade 和 FlashBlade 系列的最新成員 FlashBlade//EXA 旨在克服這些限制:
- 高傳輸量、超低延遲效能
- 橫跨數千個並行客戶的大規模平行處理
- 專為 AI、分析和 HPC 打造的橫向擴充檔案和物件式資料儲存
這些平台支援共享記憶體平行處理(適用於 GPU 陣列和 Tensor 處理器)和分散式檔案存取(適用於大規模 AI/ML、基因組學和模擬工作流程)。
結論
了解並行運算與分散式運算之間的差異,對於建構現代化資料基礎架構至關重要。平行運算可為需要超低延遲通訊的緊密耦合工作負載,在單一系統中提供最高效能。分散式運算提供無限的可擴充性和容錯性,適用於跨多台機器或地理區域的鬆散耦合問題。
這些方法的選擇取決於您的具體需求。當任務需要頻繁的協調和毫秒以下的回應時間時,並行架構會更好。當應用程式必須水平擴展、優雅地容忍故障,或跨分散式位置處理資料時,分散式系統就是最佳選擇。許多現代工作負載都同時運用這兩項功能,在分散式雲端基礎架構中使用平行 GPU 叢集。
儲存效能可判斷您的運算基礎架構是否發揮潛力。無論您的處理器多強大,它們都只能與資料管道提供資料時一樣有效。 FlashBlade 和 FlashBlade//EXA 以專為平行和分散式基礎架構設計的高傳輸量、超低延遲效能,來消除儲存瓶頸。它們支援現代 HPC、AI 和資料分析所需的大規模並行、混合工作負載和彈性擴充性。
準備好消除儲存瓶頸了嗎? 請探索 FlashBlade 解決方案 ,或聯絡 Everpure 以討論您的特定運算架構。



