병렬 컴퓨팅과 분산 컴퓨팅 간의 경계는 현대적 HPC 및 AI 배포에서 점점 더 흐려지고 있으며, 분산 아키텍처는 두 가지 접근 방식을 동시에 활용합니다. 이러한 융합은 고대역폭, 낮은 지연 시간 및 대규모 동시성을 지원하는 스토리지 플랫폼에 대한 수요를 창출합니다.
병렬 vs. 분산: 주요 차이점
두 가지 접근 방식은 복잡한 문제를 더 작은 작업으로 세분화하지만, 아키텍처와 구현은 근본적으로 다릅니다.
시스템 아키텍처
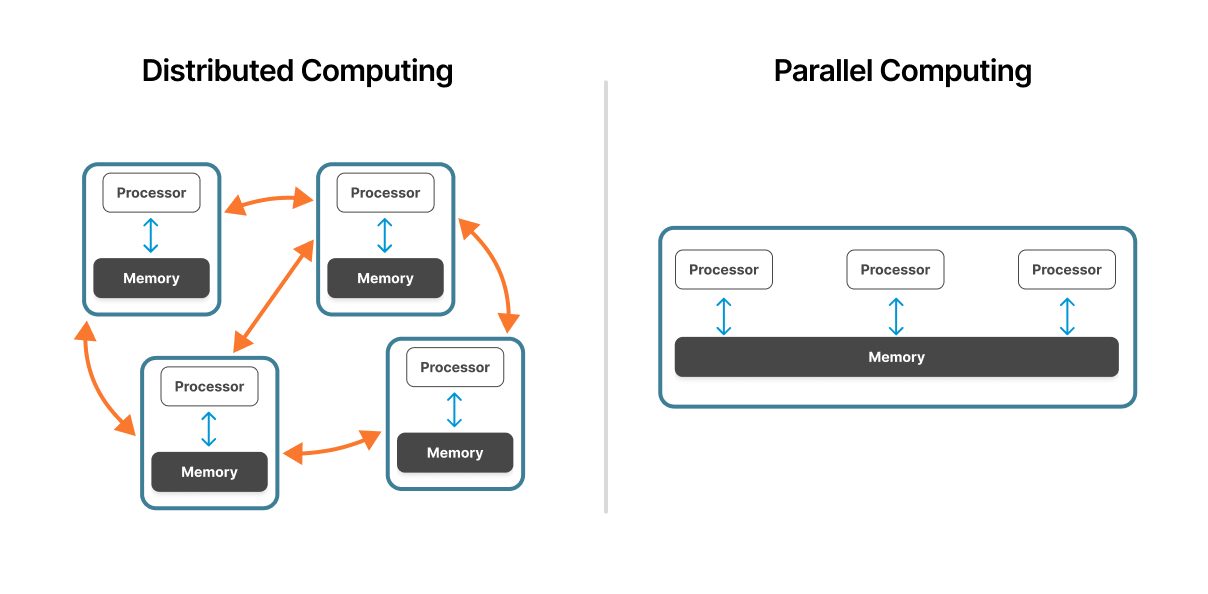
병렬 컴퓨팅 은 단일 시스템 또는 단단히 결합된 클러스터 내에서 작동합니다. 여러 프로세서가 통합 메모리 아키텍처를 통해 동일한 물리적 하드웨어에 대한 액세스를 공유하여 처리 장치 간의 신속한 통신을 지원합니다.
분산 컴퓨팅은 네트워크를 통해 연결된 여러 독립 컴퓨터에 걸쳐 있습니다. 각 노드는 자체 프로세서, 메모리 및 Operating System로 자율적으로 작동하며 네트워크 프로토콜을 통해 조정됩니다.
메모리 조직
병렬 시스템에서 프로세서는 공통 메모리 공간을 공유합니다. 이러한 공유 메모리 아키텍처 는 빠른 데이터 교환을 가능하게 합니다. 프로세서는 동일한 메모리 위치에 읽고 쓸 수 있습니다. 그러나 프로세서 수가 증가함에 따라 이러한 공유 리소스는 병목 현상이 될 수 있습니다.
분산 시스템은 각 노드에서 독립 메모리를 사용합니다. 노드는 필요한 데이터가 포함된 메시지를 전달하여 통신합니다. 이 분산 메모리 모델은 메모리 경합을 제거하지만 네트워크 통신 오버헤드를 발생시킵니다.
커뮤니케이션 방법
병렬 컴퓨팅은 고속 내부 버스 또는 인터커넥트에 의존합니다. 통신은 캐시-투-캐시 전송의 경우 나노초, 메인 메모리 액세스의 경우 마이크로초 등 메모리 속도로 이루어집니다. 이러한 낮은 지연 시간으로 인해 병렬 시스템은 빈번한 조정이 필요한 긴밀하게 결합된 문제에 이상적입니다.
분산 시스템은 네트워크 프로토콜을 통해 통신합니다. 네트워크 통신은 지리적 거리에 따라 일반적으로 밀리초 단위로 측정되는 레이턴시를 도입합니다. 즉, 분산 시스템은 작업이 독립적으로 작동하는 느슨하게 결합된 문제에 가장 적합합니다.
확장성
병렬 컴퓨팅은 수직으로 확장되어 단일 시스템에 더 많은 프로세서를 추가합니다. 이러한 접근 방식은 메모리 대역폭 제한, 열 제한 및 버스 경합과 같은 물리적 한계를 극복합니다. 대부분의 병렬 시스템은 수백 개의 코어로 확장됩니다.
분산 컴퓨팅은 수평으로 확장되어 네트워크에 더 많은 장비를 추가합니다. 시스템은 소수의 노드에서 수천 대의 기계로 확장할 수 있습니다. 클라우드 플랫폼은 전 세계 데이터센터에 분산된 시스템을 일상적으로 운영합니다.
폴트 허용 오차
병렬 시스템은 일반적으로 단일 장애 지점을 나타냅니다. 기계가 고장나면 전체 계산이 중단됩니다.
분산 시스템은 내재된 내결함성을 제공합니다. 한 노드가 실패하면 다른 노드는 계속 처리됩니다. 잘 설계된 분산 시스템은 고장을 감지하고, 작업을 재할당하며, 개별 기계가 오프라인 상태가 되면 운영을 유지합니다.
지리적 분포
병렬 컴퓨팅은 단일 위치에서 처리를 집중합니다. 모든 프로세서는 로컬 인프라로 연결된 동일한 데이터센터에 상주합니다.
분산 컴퓨팅은 지리적인 분산을 가능하게 합니다. 노드는 여러 도시 또는 대륙에서 운영될 수 있으며, 콘텐츠 전송 네트워크 및 데이터 상주 규정 준수와 같은 사용 사례를 지원합니다.
병렬 컴퓨팅과 분산 컴퓨팅 간의 경계는 현대적 HPC 및 AI 구축에서 점점 더 흐려지고 있으며, 분산 아키텍처는 두 가지 접근 방식을 동시에 활용합니다.
병렬 컴퓨팅의 현대적인 애플리케이션
병렬 처리는 기존의 과학 컴퓨팅 외에도 많은 최첨단 워크로드를 지원합니다.
- AI 및 Machine Learning: GPU 클러스터 전반에서 데이터 병렬 처리를 사용하여 대규모 모델 트레이닝
- 실시간 분석: 사기 탐지, 자율 주행 및 실시간 추천 엔진
- 고주파 거래: 초저지연 트랜잭션 처리
- 암호화폐 채굴: 효율적인 해싱 및 컨센서스 검증
- 항공우주 및 에너지: 다중물리 시뮬레이션 및 예측 모델링
Everpure는 병렬 컴퓨팅 클러스터 전반에서 초당 수테라바이트 대역폭을 유지할 수 있는 데이터 플랫폼을 통해 이러한 산업을 지원합니다.
하이브리드 모델 및 컨버지드 트렌드
현대 워크로드는 병렬 및 분산 컴퓨팅을 결합한 하이브리드 모델을 점점 더 많이 사용합니다. 예를 들어, 데이터 병렬 방식을 사용하여 GPU 클러스터에서 실행되는 Horovod 또는 PyTorch Lightning과 같은 분산 교육 프레임워크가 있습니다.
플래시블레이드(FlashBlade) 와 플래시블레이드(FlashBlade) 제품군의 최신 제품인 FlashBlade//EXA는 이러한 환경에 매우 적합합니다. 동시 혼합 워크로드, 다중 프로토콜 액세스(NFS, S3) 및 탄력적인 확장성을 지원하므로 각 컴퓨팅 패러다임을 위한 스토리지 시스템을 재설계할 필요가 없습니다.
병렬 및 분산 컴퓨팅에서 스토리지의 역할
프로세서가 아무리 강력하더라도, 프로세서에 공급하는 데이터 파이프라인만큼만 효과적입니다. 스토리지 병목 현상은 병렬 및 분산 환경 모두에서 종종 제한 요인입니다.
플래시블레이드(FlashBlade)와 플래시블레이드(FlashBlade) 제품군의 최신 제품인 FlashBlade//EXA는 다음과 같은 한계를 극복하도록 설계되었습니다.
- 고처리량, 초저대기 시간 성능
- 수천 개의 동시 클라이언트에 대한 대규모 병렬 처리
- AI, 분석 및 HPC를 위해 구축된 스케일-아웃 파일 및 오브젝트 스토리지
이러한 플랫폼은 공유 메모리 병렬 처리(GPU 팜 및 Tensor 프로세서용)와 분산 파일 액세스(대규모 AI/ML, 유전체학 및 시뮬레이션 워크플로우용)를 모두 지원합니다.
결론
병렬 컴퓨팅과 분산 컴퓨팅의 차이점을 이해하는 것은 현대적인 데이터 인프라를 설계하는 데 필수적입니다. 병렬 컴퓨팅은 단일 시스템 내에서 초저지연 통신이 필요한 긴밀하게 결합된 워크로드에 최대 성능을 제공합니다. 분산 컴퓨팅은 여러 시스템 또는 지리적 지역에 걸쳐 느슨하게 결합된 문제에 대해 무제한 확장성과 내결함성을 제공합니다.
이러한 접근 방식들 간의 선택은 특정 요구사항에 따라 달라집니다. 작업을 자주 조정하고 밀리초 미만의 응답 시간을 필요로 하는 경우 병렬 아키텍처가 탁월합니다. 애플리케이션이 수평으로 확장되거나, 장애를 정상적으로 허용하거나, 분산된 위치에 걸쳐 데이터를 처리해야 하는 경우, 분산 시스템이 해답입니다. 많은 현대적 워크로드는 분산 클라우드 인프라 내에서 병렬 GPU 클러스터를 사용하여 두 가지 모두를 활용합니다.
스토리지 성능은 컴퓨팅 인프라가 잠재력을 달성하는지 여부를 결정합니다. 프로세서가 아무리 강력하더라도 데이터 파이프라인만큼만 효과적입니다. 플래시블레이드(FlashBlade) 및 FlashBlade//EXA 는 병렬 및 분산 아키텍처를 위해 설계된 높은 처리량과 초저지연 성능으로 스토리지 병목 현상을 제거합니다. 또한, 현대적인 HPC, AI 및 데이터 분석에 필요한 대규모 동시성, 혼합 워크로드 및 탄력적인 확장성을 지원합니다.
스토리지 병목 현상을 제거할 준비가 되셨나요? 플래시블레이드(FlashBlade) 솔루션을 살펴보 거나 Everpure에 문의하여 특정 컴퓨팅 아키텍처에 대해 논의하세요.