並列コンピューティングと分散コンピューティングの境界は、分離型アーキテクチャが両方のアプローチを同時に活用する、最新の HPC や AI 環境においてますます曖昧になっています。このコンバージェンスは、高帯域幅、低レイテンシー、大規模な並行性をサポートするストレージ・プラットフォームの需要を促進します。
並列 と 分散:主な違い
どちらのアプローチも複雑な問題を小さなタスクに分解しますが、アーキテクチャと実装は根本的に異なります。
システム・アーキテクチャ
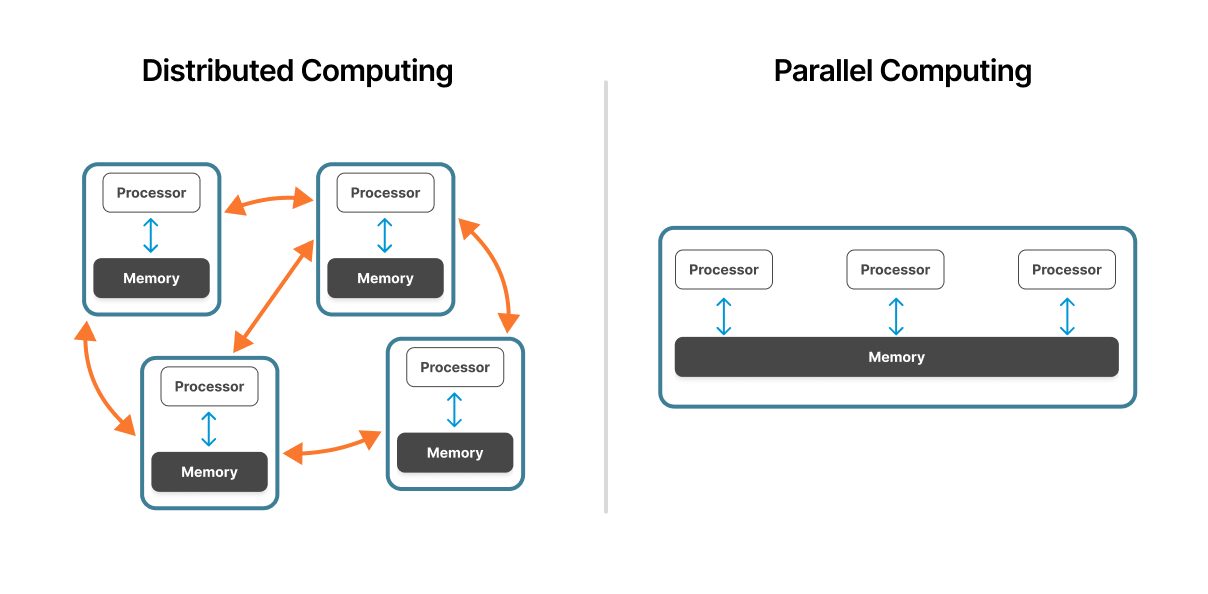
並列コンピューティングは、単一のマシンまたは緊密に結合されたクラスタ内で動作します。複数のプロセッサが同じ物理ハードウェアへのアクセスを統合メモリ・アーキテクチャで共有し、処理ユニット間の高速通信を可能にします。
分散コンピューティングは、ネットワークを介して接続された複数の独立したコンピュータに及びます。各ノードは、独自のプロセッサ、メモリ、OS を使用して自律的に動作し、ネットワーク・プロトコルを介して調整されます。
メモリ構成
並列システムでは、プロセッサは共通のメモリ・スペースを共有します。この共有メモリ・アーキテクチャは、高速なデータ交換を可能にします。プロセッサは同じメモリ領域に読み書きできます。しかし、プロセッサ数が増えると、この共有リソースはボトルネックになる可能性があります。
分散型システムは、各ノードで独立したメモリを使用します。ノードは、必要なデータを含むメッセージを渡して通信します。この分散型メモリ・モデルは、メモリの競合を排除しますが、ネットワーク通信のオーバーヘッドをもたらします。
通信方法
並列コンピューティングは、高速の内部バスや相互接続に依存しています。通信はメモリ速度で行われます。キャッシュ間の転送はナノ秒、メイン・メモリへのアクセスはマイクロ秒です。この低レイテンシーにより、並列システムは頻繁な連携を必要とする密結合型の問題に最適です。
分散システムは、ネットワーク・プロトコルを介して通信します。ネットワーク通信は、地理的距離に応じて、通常ミリ秒単位で測定されるレイテンシーが発生します。これは、タスクが独立して動作する疎結合型の問題では、分散システムが最も適していることを意味します。
スケーラビリティ
並列コンピューティングは垂直に拡張され、単一のシステムにより多くのプロセッサを追加します。このアプローチは、メモリ帯域幅の制約、熱的制限、バス競合といった物理的な限界にぶつかります。ほとんどの並列システムは、数百コアに拡張できます。
分散コンピューティングは水平に拡張されるため、ネットワークにマシンを追加できます。システムは、少数のノードから数千台のマシンにまで拡張できます。クラウド・プラットフォームは、世界中のデータセンターにまたがる分散システムを日常的に運用しています。
耐障害性
並列システムは、通常、単一の障害点を表します。マシンに障害が発生すると、計算全体が停止します。
分散型システムは、固有の耐障害性を提供します。1 つのノードに障害が発生すると、他のノードの処理が続行されます。適切に設計された分散型システムは、障害を検出し、作業を再割り当てし、個々のマシンがオフラインになるたびに動作を維持します。
地理的分布
並列コンピューティングは、処理を単一の場所に集約します。全てのプロセッサは、ローカル・インフラで接続された同じデータセンターに存在します。
分散コンピューティングは、地理的な分散を可能にします。ノードは、さまざまな都市や大陸で動作し、コンテンツ配信ネットワークやデータ・レジデンシー規制の遵守などのユースケースをサポートします。
並列コンピューティングと分散コンピューティングの境界は、分離型アーキテクチャが両方のアプローチを同時に活用する、最新の HPC や AI においてますます曖昧になっています。
並列コンピューティングのモダン・アプリケーション
従来の科学コンピューティング以外にも、並列処理は多くの最先端のワークロードを支えています。
- AI と機械学習:GPU クラスタ間のデータ並列性を使用した大規模モデルのトレーニング
- リアルタイム分析:不正検知、自動運転、ライブ・レコメンデーション・エンジン
- 高頻度取引:超低レイテンシーのトランザクション処理
- 仮想通貨マイニング:効率的なハッシュとコンセンサス検証
- 航空宇宙とエネルギー:マルチフィジックス・シミュレーションと予測モデリング
Everpure は、高度に並列なコンピューティング・クラスタ全体で毎秒数テラバイトの帯域幅を維持できるデータ・プラットフォームにより、これらの業界をサポートしています。
ハイブリッド・モデルとコンバージェンス・トレンド
モダンなワークロードでは、並列コンピューティングと分散コンピューティングを組み合わせたハイブリッド・モデルがますます利用されています。例えば、データ並列方式を使用して GPU クラスタ上で実行される Horovod や PyTorch Lightning などの分散トレーニング・フレームワークなどです。
FlashBlade と FlashBlade ファミリーの最新メンバーである FlashBlade//EXA は、これらの環境に特に適しています。混合ワークロード、マルチプロトコル・アクセス(NFS、S3)、柔軟なスケーラビリティを同時にサポートしているため、コンピューティング・パラダイムごとにストレージ・システムを再設計する必要はありません。
並列コンピューティングと分散コンピューティングにおけるストレージの役割
プロセッサがどれほど高性能であっても、データを供給するデータ・パイプラインの性能次第で、その能力が左右されます。ストレージのボトルネックは、多くの場合、並列環境と分散環境の両方で制限要因となります。
FlashBlade および FlashBlade ファミリーの最新メンバーである FlashBlade//EXA は、以下の機能によってこれらの制限を克服するように設計されています。
- 高スループット、超低レイテンシーの性能
- 数千の同時クライアントにわたる大規模な並列処理
- AI、分析、HPC 向けに構築されたスケールアウト・ファイル/オブジェクト・ストレージ
これらのプラットフォームは、共有メモリ型の並列処理(GPU ファームおよびテンソル・プロセッサ)と分散ファイル・アクセス(大規模な AI/ML、ゲノミクス、シミュレーション・ワークフロー)の両方をサポートしています。
まとめ
並列コンピューティングと分散コンピューティングの違いを理解することは、モダンなデータ・インフラの設計に不可欠です。並列コンピューティングは、単一システム内で超低レイテンシーの通信を必要とする密結合型ワークロードに対して、最大の性能を発揮します。分散コンピューティングは、複数のマシンや地理的領域にまたがる疎結合型の処理に対して、無制限のスケーラビリティと耐障害性を提供します。
これらのアプローチの選択は、特定の要件によって異なります。タスクの頻繁な調整とミリ秒未満の応答時間が必要な場合、並列アーキテクチャが優れています。アプリケーションが水平に拡張し、障害を正常に許容し、分散された場所全体でデータを処理する必要がある場合は、分散システムが答えとなります。モダンなワークロードの多くは、分散型クラウド・インフラ内で並列 GPU クラスタを使用することで、両方を活用しています。
ストレージの性能は、コンピューティング・インフラが潜在能力を発揮するかどうかを決定します。プロセッサのパワーは、データ・パイプラインの供給と同じくらい効果的です。FlashBlade と FlashBlade//EXA は、並列および分散アーキテクチャ向けに設計された高スループット、超低レイテンシーの性能により、ストレージのボトルネックを排除します。これらは、現代の HPC、AI、データ分析が要求する大規模な並行性、混合ワークロード、柔軟なスケーラビリティをサポートしています。
ストレージのボトルネックを解消する準備はできていますか?FlashBlade ソリューションをご覧いただくか、Everpure にお問い合わせのうえ、コンピューティング・アーキテクチャについてご相談ください。