Dismiss
Innovazione
Una piattaforma creata per l'AI
Unificata, automatizzata e pronta a trasformare i dati in intelligence.
Dismiss
16-18 giugno, Las Vegas
Pure//Accelerate® 2026
Scopri come trarre il massimo dai tuoi dati.
Calcolo parallelo e calcolo distribuito a confronto: una panoramica
Il calcolo parallelo e distribuito è fondamentale per il calcolo moderno a performance elevate (HPC), i data analytics e l' Artificial Intelligence (AI). Anche se correlati, sono approcci distinti con architetture, vantaggi e richieste di storage diversi.
In questo articolo esploreremo le differenze fondamentali tra il calcolo parallelo e quello distribuito e come Everpure supporta entrambi con soluzioni di storage innovative come Everpure FlashBlade® e FlashBlade//EXA™, il nuovo membro della famiglia FlashBlade.
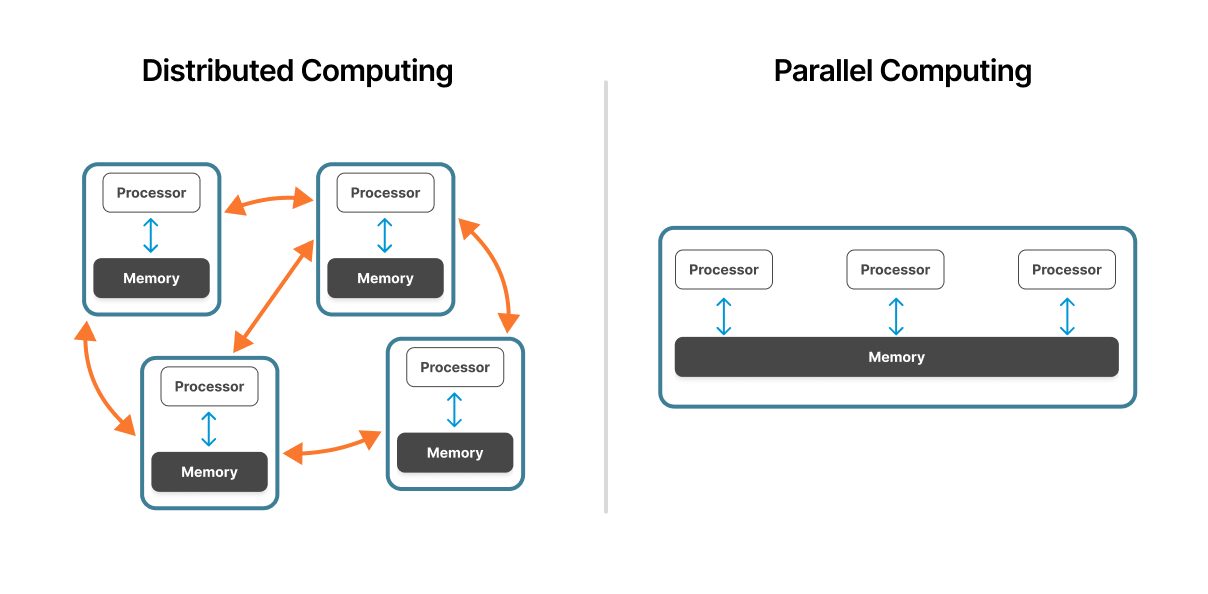
Figura 1: Un sistema di calcolo distribuito rispetto a un sistema di calcolo parallelo.
Fonte: ResearchGate
Che cos'è il calcolo parallelo?
Il calcolo parallelo comporta la suddivisione di un'attività in attività secondarie più piccole che vengono elaborate contemporaneamente tra più processori o core all'interno di un singolo sistema.
Gli esempi tradizionali includono:
- Modellazione climatica
- Indagine sismica
- Astrofia computazionale
Negli ultimi anni, il calcolo parallelo si è evoluto oltre l'elaborazione multi-core basata su CPU in modelli accelerati da GPU. I moderni workload AI/ML ora si basano su architetture GPU parallele, come NVIDIA A100 o H100, che consentono il deep learning, l'elaborazione del linguaggio naturale e la visione artificiale su vasta scala.
Il calcolo parallelo è anche al centro di innovazioni come il calcolo quantistico e i sistemi neuromorfici, che emulano le architetture neurali per elaborare i dati in modo più efficiente. Persino i dispositivi mobili ed edge ora integrano funzionalità di elaborazione parallela per supportare l'AI in tempo reale all'edge.


Che cos'è il calcolo distribuito?
Il calcolo distribuito distribuisce le attività su più macchine, spesso in posizioni fisiche diverse, collegate in rete per funzionare come un unico sistema. Ogni nodo gestisce una parte del workload e comunica i risultati a un sistema centrale.
Alcuni esempi:
- MapReduce e piattaforme di Big Data come Apache Hadoop e Spark
- Rendering distribuito in animazioni/VFX
- Simulazioni multi-agente nella progettazione aerospaziale e automobilistica
Le architetture distribuite sono comuni nel cloud computing, negli ambienti edge e nei sistemi IoT su larga scala, dove la scalabilità e la distribuzione geografica sono essenziali.
I confini tra calcolo parallelo e distribuito sono sempre più sfocati nei moderni deployment HPC e AI, dove le architetture disaggregate sfruttano entrambi gli approcci contemporaneamente. Questa convergenza determina la domanda di piattaforme di storage che supportino larghezza di banda elevata, bassa latenza e simultaneità enorme.
Parallelo e distribuito: differenze chiave
Entrambi gli approcci suddividono i problemi complessi in attività più piccole, ma si distinguono fondamentalmente per architettura e implementazione.
Architettura di sistema
Il calcolo parallelo opera all'interno di una singola macchina o di un cluster strettamente accoppiato. Più processori condividono l'accesso allo stesso hardware fisico con un'architettura di memoria unificata, consentendo una comunicazione rapida tra le unità di elaborazione.
Il calcolo distribuito si estende su più computer indipendenti connessi in rete. Ogni nodo opera in modo autonomo con il proprio processore, memoria e Operating System, coordinandosi attraverso i protocolli di rete.
Organizzazione della memoria
Nei sistemi paralleli, i processori condividono uno spazio di memoria comune. Questa architettura di memoria condivisa consente uno scambio rapido dei dati: i processori leggono e scrivono nelle stesse posizioni di memoria. Tuttavia, questa risorsa condivisa può diventare un collo di bottiglia man mano che il numero di processori aumenta.
I sistemi distribuiti utilizzano una memoria indipendente per ciascun nodo. I nodi comunicano trasmettendo i messaggi contenenti i dati necessari. Questo modello di memoria distribuita elimina il conflitto di memoria, ma introduce i costi generali di comunicazione di rete.
Metodi di comunicazione
Il calcolo parallelo si basa su bus interni o interconnessioni ad alta velocità. La comunicazione avviene alla velocità della memoria, ovvero in nanosecondi per i trasferimenti da cache a cache, in microsecondi per l'accesso alla memoria principale. Questa bassa latenza rende i sistemi paralleli ideali per i problemi strettamente collegati che richiedono una coordinazione frequente.
I sistemi distribuiti comunicano tramite protocolli di rete. La comunicazione di rete introduce latenza, misurata in millisecondi, a seconda della distanza geografica. Ciò significa che i sistemi distribuiti funzionano meglio per i problemi di accoppiamento inadeguato in cui le attività operano in modo indipendente.
Scalabilità
Il calcolo parallelo scala verticalmente, aggiungendo più processori a un singolo sistema. Questo approccio raggiunge i limiti fisici: vincoli di larghezza di banda della memoria, limitazioni termiche e conflitti tra bus. La maggior parte dei sistemi paralleli è scalabile a centinaia di core.
Il calcolo distribuito scala orizzontalmente, aggiungendo più macchine alla rete. I sistemi possono crescere da pochi nodi a migliaia di macchine. Le piattaforme cloud gestiscono regolarmente sistemi distribuiti che coprono data center in tutto il mondo.
Tolleranza ai guasti
I sistemi paralleli rappresentano in genere un singolo punto di guasto. Se la macchina si guasta, l'intero calcolo si interrompe.
I sistemi distribuiti offrono una tolleranza intrinseca ai guasti. Quando un nodo si guasta, gli altri continuano l'elaborazione. I sistemi distribuiti ben progettati rilevano i guasti, riassegnano il lavoro e mantengono il funzionamento man mano che le singole macchine passano offline.
Distribuzione geografica
Il calcolo parallelo concentra l'elaborazione in un'unica posizione. Tutti i processori risiedono nello stesso data center, connesso dall'infrastruttura locale.
Il calcolo distribuito consente la distribuzione geografica. I nodi possono operare in città o continenti diversi, supportando casi d'uso come le reti di distribuzione dei contenuti e la conformità alle normative sulla residenza dei dati.
I confini tra calcolo parallelo e calcolo distribuito sono sempre più sfocati nei moderni deployment HPC e AI , dove le architetture disaggregate sfruttano entrambi gli approcci contemporaneamente.
Applicazioni moderne di calcolo parallelo
Oltre al calcolo scientifico tradizionale, il parallelismo alimenta molti workload all'avanguardia:
- AI e machine learning: Addestramento di modelli di grandi dimensioni utilizzando il parallelismo dei dati tra i cluster GPU
- Analytics in tempo reale: Rilevamento delle frodi, guida autonoma e motori di raccomandazione in tempo reale
- trading ad alta frequenza: Elaborazione delle transazioni a latenza ultra-bassa
- mining di criptovalute: Hashing efficiente e convalida del consenso
- Settore aerospaziale ed energetico: Simulazioni multifisiche e modellazione predittiva
Everpure supporta questi settori con piattaforme di dati in grado di sostenere larghezza di banda di più terabyte al secondo in cluster di elaborazione altamente paralleli.
Modelli ibridi e tendenze di convergenza
I workload moderni utilizzano sempre più modelli ibridi che combinano il calcolo parallelo e distribuito, ad esempio un framework di addestramento distribuito come Horovod o PyTorch Lightning eseguito su un cluster GPU utilizzando metodi data-parallel.
FlashBlade e il nuovo membro della famiglia FlashBlade, FlashBlade//EXA, sono particolarmente adatti a questi ambienti. Grazie al supporto di workload misti simultanei, all'accesso multiprotocollo (NFS, S3) e alla scalabilità elastica, eliminano la necessità di riprogettare i sistemi di storage per ogni paradigma di calcolo.
Il ruolo dello storage nel calcolo parallelo e distribuito
Non importa quanto siano potenti i processori, sono efficaci solo quanto le pipeline di dati che li alimentano. I colli di bottiglia dello storage sono spesso il fattore limitante sia negli ambienti paralleli che in quelli distribuiti.
FlashBlade e il nuovo membro della famiglia FlashBlade, FlashBlade//EXA, sono progettati per superare questi limiti con:
- Performance a velocità di trasmissione elevata e latenza estremamente bassa
- Parallelismo su migliaia di client simultanei
- File storage e object storage scale-out progettato per AI, analytics e HPC
Queste piattaforme supportano il parallelismo a memoria condivisa (per le GPU farm e i processori a tensore) e l'accesso distribuito ai file (per i workflow di AI/ML, genomica e simulazione su larga scala).
Conclusione
Comprendere le differenze tra il calcolo parallelo e quello distribuito è essenziale per progettare un'infrastruttura dati moderna. Il calcolo parallelo offre massime performance per i workload strettamente accoppiati che richiedono una comunicazione a latenza ultra bassa all'interno di un singolo sistema. Il calcolo distribuito offre scalabilità illimitata e tolleranza ai guasti per i problemi di accoppiamento non corretto che coprono più macchine o aree geografiche.
La scelta tra questi approcci dipende dai requisiti specifici. Quando le attività richiedono un coordinamento frequente e tempi di risposta inferiori al millisecondo, le architetture parallele eccellono. Quando le applicazioni devono essere scalate orizzontalmente, tollerare i guasti con grazia o elaborare i dati in posizioni distribuite, i sistemi distribuiti sono la risposta. Molti workload moderni sfruttano entrambi, utilizzando cluster GPU paralleli all'interno di infrastrutture cloud distribuite.
Le performance dello storage determinano se l'infrastruttura di elaborazione raggiunge il suo potenziale. Indipendentemente dalla potenza dei processori, sono efficaci solo come le pipeline di dati che li alimentano. FlashBlade e FlashBlade//EXA eliminano i colli di bottiglia dello storage con performance di velocità di trasmissione e latenza ultra-bassa progettate per architetture parallele e distribuite. Supportano l'enorme simultaneità, i workload misti e la scalabilità elastica richiesti dalle moderne tecnologie HPC, AI e data analytics.
Sei pronto a eliminare i colli di bottiglia dello storage? Esplora le soluzioni FlashBlade o contatta Everpure per discutere della tua architettura di calcolo specifica.
Potrebbe interessarti anche...
Esplora risorse ed eventi principali

TRADESHOW
Pure//Accelerate® 2026
June 16-18, 2026 | Resorts World Las Vegas
Preparati all'evento più importante a cui parteciperai quest'anno.

DEMO DI PURE360
Esplora, scopri e prova Pure Storage.
Accedi a video e demo on demand per scoprire i vantaggi che Pure Storage ti offre.

VIDEO
Guarda: Il valore di un Enterprise Data Cloud (EDC).
Charlie Giancarlo spiega perché il futuro è nella gestione dei dati, non dello storage. Scopri in che modo un approccio unificato trasforma le operazioni IT aziendali.

RISORSA
Lo storage legacy non può alimentare il futuro.
I workload moderni richiedono velocità, sicurezza e scalabilità AI-ready. Il tuo stack è pronto?
Personalize for Me