Dismiss
Innovatie
Een platform, gebouwd voor AI
Unified, geautomatiseerd en klaar om data om te zetten in informatie.
Dismiss
16-18 juni, Las Vegas
Pure//Accelerate® 2026
Ontdek hoe u de ware waarde van uw gegevens kunt ontsluiten.
Parallel vs. gedistribueerd computergebruik: Een overzicht
Parallelle en gedistribueerde computing zijn fundamenteel voor moderne high-performance computing (HPC), data-analytics en Artificial Intelligence (AI). Hoewel het gerelateerd is, zijn het verschillende benaderingen met verschillende architecturen, voordelen en opslagvereisten.
In dit artikel bekijken we de fundamentele verschillen tussen parallelle en gedistribueerde computing - en hoe Everpure beide ondersteunt met innovatieve opslagoplossingen zoals Everpure FLASHBLADE® en het nieuwste lid van de FLASHBLADE-familie, FlashBlade//EXA™.
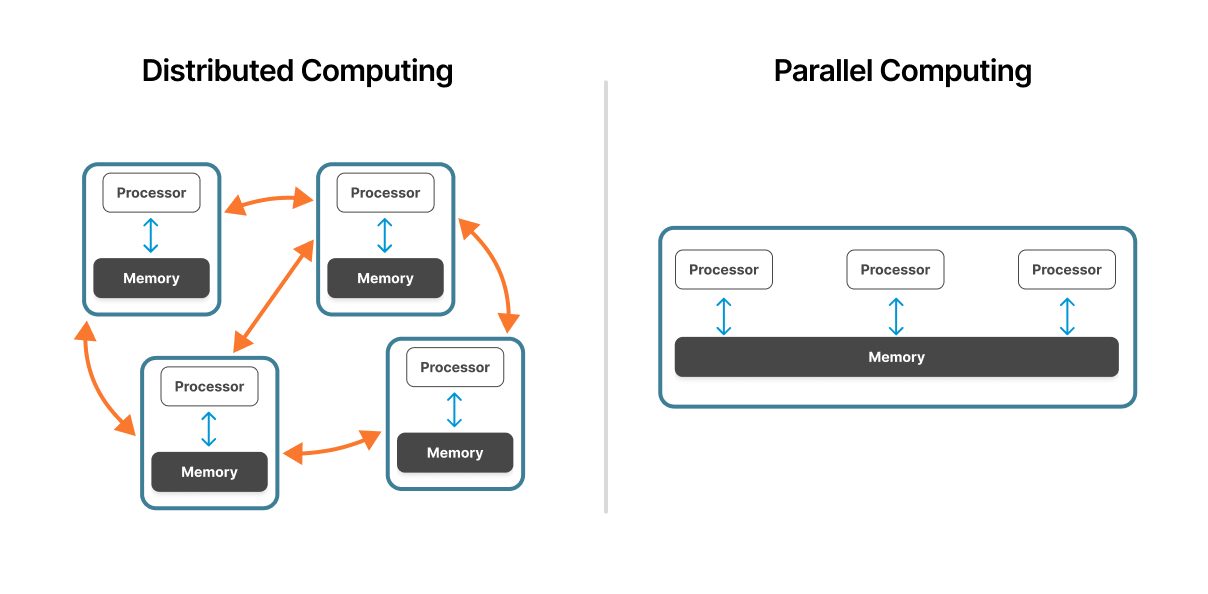
Afbeelding 1: Een gedistribueerd computersysteem in vergelijking met een parallel computersysteem.
Bron: ResearchGate
Wat is parallel computing?
Parallel computing omvat het opsplitsen van een taak in kleinere subtaken die tegelijkertijd over meerdere processors of cores binnen één systeem worden verwerkt.
Traditionele voorbeelden zijn onder andere:
- Klimaatmodellering
- Seismisch onderzoek
- Computationele astrofysica
In de afgelopen jaren is parallel computing geëvolueerd van CPU-gebaseerde multi-core verwerking naar GPU-versnelde modellen. Moderne AI/ML-workloads zijn nu sterk afhankelijk van massaal parallelle GPU-architecturen, zoals NVIDIA A100 of H100, die Deep learning, natuurlijke taalverwerking en computervisie op schaal mogelijk maken.
Parallel computing vormt ook de kern van innovaties zoals kwantumcomputing en neuromorfe systemen, die neurale architecturen imiteren om data efficiënter te verwerken. Zelfs mobiele apparaten en edge-apparaten integreren nu parallelle verwerkingscapaciteiten om realtime AI aan de edge te ondersteunen.


Wat is gedistribueerd computergebruik?
Gedistribueerd computergebruik verspreidt taken over meerdere machines - vaak op verschillende fysieke locaties - die met elkaar zijn verbonden om als één systeem te functioneren. Elke node verwerkt een deel van de workload en communiceert de resultaten terug naar een centraal systeem.
Voorbeelden zijn:
- MapReduce- en big data-platforms zoals Apache Hadoop en Spark
- Gedistribueerde rendering in animatie/VFX
- Multi-agent simulaties in ruimtevaart en automotive design
Gedistribueerde architecturen komen veel voor in cloud computing, edge-omgevingen en grootschalige IoT-systemen, waar schaalbaarheid en geografische distributie essentieel zijn.
De lijnen tussen parallelle en gedistribueerde computing worden steeds waziger in moderne HPC- en AI-implementaties, waarbij uitgesplitste architecturen beide benaderingen tegelijkertijd gebruiken. Deze convergentie stimuleert de vraag naar opslagplatforms die een hoge bandbreedte, lage latentie en enorme gelijktijdigheid ondersteunen.
Parallel vs. gedistribueerd: Belangrijke verschillen
Hoewel beide benaderingen complexe problemen opsplitsen in kleinere taken, verschillen ze fundamenteel in architectuur en implementatie.
Systeemarchitectuur
Parallel computing werkt binnen één enkele machine of nauw gekoppeld cluster. Meerdere processors delen toegang tot dezelfde fysieke hardware met een uniforme geheugenarchitectuur, waardoor snelle communicatie tussen verwerkingseenheden mogelijk is.
Distributed computing omvat meerdere onafhankelijke computers die via het netwerk zijn verbonden. Elke node werkt autonoom met zijn eigen processor, geheugen en Operating System en coördineert via netwerkprotocollen.
Geheugenorganisatie
In parallelle systemen delen processors een gemeenschappelijke geheugenruimte. Deze gedeelde geheugenarchitectuur maakt snelle data-uitwisseling mogelijk - processoren lezen en schrijven naar dezelfde geheugenlocaties. Deze gedeelde bron kan echter een knelpunt worden naarmate het aantal processoren toeneemt.
Gedistribueerde systemen maken gebruik van onafhankelijk geheugen op elke node. Knooppunten communiceren door berichten met de benodigde data door te geven. Dit gedistribueerde geheugenmodel elimineert geheugenproblemen, maar introduceert overhead voor netwerkcommunicatie.
Communicatiemethoden
Parallel computing is afhankelijk van snelle interne bussen of interconnecties. Communicatie gebeurt op geheugensnelheid - nanoseconden voor cache-naar-cache-overdrachten, microseconden voor toegang tot het hoofdgeheugen. Deze lage latency maakt parallelle systemen ideaal voor nauw gekoppelde problemen die frequente coördinatie vereisen.
Gedistribueerde systemen communiceren via netwerkprotocollen. Netwerkcommunicatie introduceert latency, meestal gemeten in milliseconden, afhankelijk van de geografische afstand. Dit betekent dat gedistribueerde systemen het beste werken voor losjes gekoppelde problemen waarbij taken onafhankelijk werken.
Schaalbaarheid
Parallelle computing schaalt verticaal - meer processors worden toegevoegd aan één systeem. Deze aanpak bereikt fysieke grenzen: beperkingen van de geheugenbandbreedte, thermische beperkingen en buscontroverse. De meeste parallelle systemen schalen naar honderden cores.
Gedistribueerde computing schaalt horizontaal, waardoor meer machines aan het netwerk worden toegevoegd. Systemen kunnen groeien van een handvol nodes naar duizenden machines. Cloudplatforms bedienen routinematig gedistribueerde systemen die datacenters over de hele wereld bestrijken.
Fouttolerantie
Parallelle systemen vertegenwoordigen doorgaans één enkel storingspunt. Als de machine uitvalt, stopt de volledige berekening.
Gedistribueerde systemen bieden inherente fouttolerantie. Wanneer één node uitvalt, blijven andere nodes doorgaan met verwerken. Goed ontworpen gedistribueerde systemen detecteren storingen, wijzen werk opnieuw toe en behouden de werking terwijl individuele machines offline gaan.
Geografische distributie
Parallel computing concentreert de verwerking op één locatie. Alle processors bevinden zich in hetzelfde datacenter, verbonden door de lokale infrastructuur.
Gedistribueerde computing maakt geografische distributie mogelijk. Nodes kunnen in verschillende steden of continenten actief zijn, waardoor gebruikssituaties zoals netwerken voor het leveren van content en de naleving van de regelgeving voor data-residentie worden ondersteund.
De lijnen tussen parallelle en gedistribueerde computing worden steeds waziger in moderne HPC - en AI- implementaties, waarbij uitgesplitste architecturen beide benaderingen tegelijkertijd gebruiken.
Moderne applicaties van parallelle computing
Naast traditioneel wetenschappelijk computergebruik is parallellisme de drijvende kracht achter veel geavanceerde workloads:
- AI en machine learning: Opleiden van grote modellen met behulp van dataparalleliteit tussen GPU-clusters
- Realtime analytics: Fraudedetectie, autonoom rijden en live aanbevelingsengines
- Hoogfrequente handel: Transactieverwerking met ultralage latency
- Mining van cryptovaluta: Efficiënte hashing en consensusvalidatie
- Luchtvaart en energie: Multifysicasimulaties en voorspellende modellering
Everpure ondersteunt deze industrieën met dataplatforms die in staat zijn om multi-terabyte-per-seconde bandbreedte te ondersteunen over zeer parallelle computeclusters.
Hybride modellen en convergentietrends
Moderne workloads maken steeds vaker gebruik van hybride modellen die parallelle en gedistribueerde computing combineren, bijvoorbeeld een gedistribueerd trainingskader zoals Horovod of PyTorch Lightning dat op een GPU-cluster draait met behulp van dataparallelmethoden.
FLASHBLADE en het nieuwste lid van de FLASHBLADE-familie, FlashBlade//EXA, zijn bij uitstek geschikt voor deze omgevingen. Met ondersteuning voor gelijktijdige mixed workloads, multi-protocol access (NFS, S3) en elastische schaalbaarheid elimineren ze de noodzaak om opslagsystemen voor elk computerparadigma opnieuw te ontwerpen.
De rol van opslag in parallelle en gedistribueerde computing
Hoe krachtig uw processors ook zijn, ze zijn slechts zo effectief als de datapijplijnen die ze voeden. Knelpunten in opslag zijn vaak de beperkende factor in zowel parallelle als gedistribueerde omgevingen.
FLASHBLADE en het nieuwste lid van de FLASHBLADE-familie, FlashBlade//EXA, zijn ontworpen om deze beperkingen te overwinnen met:
- Prestaties met hoge verwerkingscapaciteit en ultralage latency
- Enorm parallellisme over duizenden gelijktijdige klanten
- Scale-out file- en objectopslag gebouwd voor AI, analytics en HPC
Deze platforms ondersteunen zowel het parallellisme van het gedeelde geheugen (voor GPU-boerderijen en tensorprocessors) als gedistribueerde bestandstoegang (voor grootschalige AI/ML, genomica en simulatieworkflows).
Conclusie
Het begrijpen van de verschillen tussen parallelle en gedistribueerde computing is essentieel voor het ontwerpen van een moderne data-infrastructuur. Parallel computing levert maximale prestaties voor strak gekoppelde workloads die communicatie met ultralage latency binnen één systeem vereisen. Gedistribueerd computergebruik biedt onbeperkte schaalbaarheid en fouttolerantie voor losjes gekoppelde problemen in meerdere machines of geografische regio's.
De keuze tussen deze benaderingen hangt af van uw specifieke vereisten. Wanneer taken frequente coördinatie en responstijden van minder dan een milliseconde vereisen, blinken parallelle architecturen uit. Wanneer applicaties horizontaal moeten schalen, storingen gracieus moeten tolereren of data op gedistribueerde locaties moeten verwerken, zijn gedistribueerde systemen het antwoord. Veel moderne workloads maken gebruik van beide - met behulp van parallelle GPU-clusters binnen gedistribueerde cloudinfrastructuren.
Opslagprestaties bepalen of uw computerinfrastructuur zijn potentieel bereikt. Hoe krachtig uw processors ook zijn, ze zijn slechts zo effectief als de datapijplijnen die ze voeden. FLASHBLADE en FlashBlade//EXA elimineren knelpunten in de opslag met prestaties met een hoge verwerkingscapaciteit en ultralage latency, ontworpen voor zowel parallelle als gedistribueerde architecturen. Ze ondersteunen de enorme gelijktijdigheid, gemengde workloads en elastische schaalbaarheid die moderne HPC, AI en data-analytics vereisen.
Klaar om opslagknelpunten te elimineren? Ontdek FLASHBLADE-oplossingen of neem contact op met Everpure om uw specifieke computerarchitectuur te bespreken.
Wij bevelen ook aan...
Blader door belangrijke resources en evenementen

BEURS
Pure//Accelerate® 2026
June 16-18, 2026 | Resorts World Las Vegas
Maak je klaar voor het meest waardevolle evenement dat je dit jaar zult bijwonen.

PURE360 DEMO’S
Ontdek, leer en ervaar Everpure.
Krijg toegang tot on-demand video's en demo's om te zien wat Everpure kan doen.

VIDEO
Bekijk: De waarde van een Enterprise Data Cloud
Charlie Giancarlo over waarom het beheren van data en niet opslag de toekomst zal zijn. Ontdek hoe een uniforme aanpak de IT-activiteiten van bedrijven transformeert.

RESOURCE
Legacy-storage kan de toekomst niet aandrijven.
Moderne workloads vragen om AI-ready snelheid, beveiliging en schaalbaarheid. Is uw stack er klaar voor?
Personalize for Me