Dismiss
Innovations
Everpure Simplifies Enterprise AI with Evergreen//One for AI and Data Stream Beta
Accelerate the transition from pilot to production with benchmark-proven performance, automated data pipelines, and a flexible consumption model.
Dismiss
June 16-18, Las Vegas
Pure Accelerate 2026
Discover how to unlock the true value of your data.
Dismiss
Innovation
A platform built for AI
Unified, automated, and ready to turn data into intelligence.
Parallel vs. Distributed Computing: An Overview
Parallel and distributed computing are foundational to modern high-performance computing (HPC), data analytics, and artificial intelligence (AI). Though related, they are distinct approaches with different architectures, advantages, and storage demands.
In this article, we’ll explore the fundamental differences between parallel and distributed computing—and how Everpure supports both with innovative storage solutions like Everpure FlashBlade® and the newest member of the FlashBlade family, FlashBlade//EXA™.
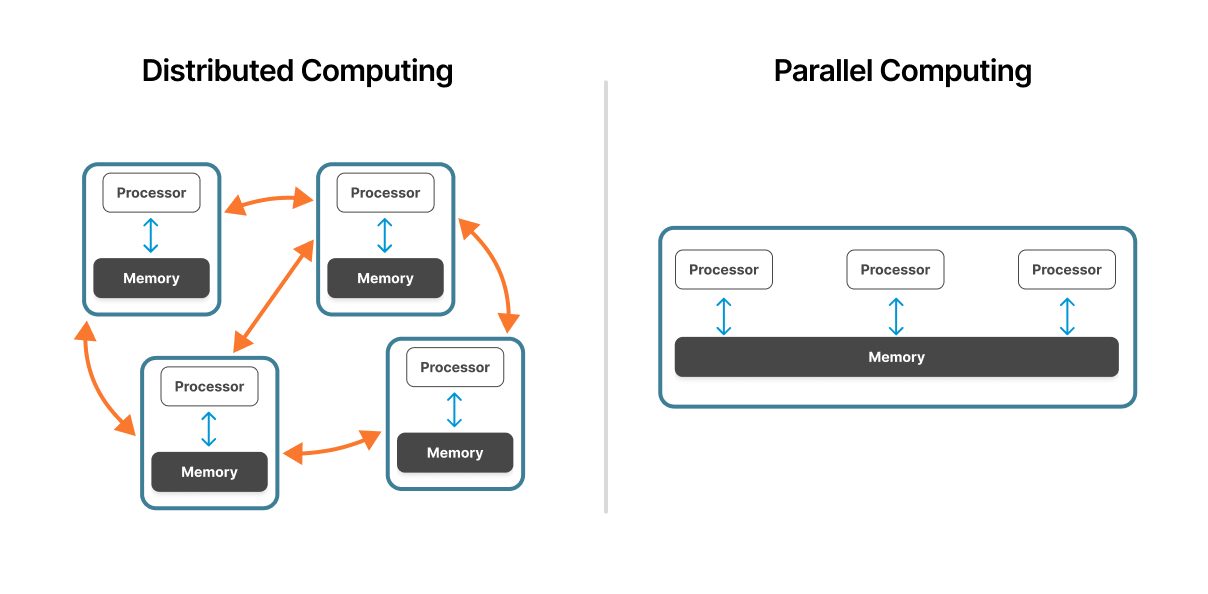
Figure 1: A distributed computing system compared to a parallel computing system.
Source: ResearchGate
What Is Parallel Computing?
Parallel computing involves breaking down a task into smaller subtasks that are processed simultaneously across multiple processors or cores within a single system.
Traditional examples include:
- Climate modeling
- Seismic surveying
- Computational astrophysics
In recent years, parallel computing has evolved beyond CPU-based multi-core processing into GPU-accelerated models. Modern AI/ML workloads now rely heavily on massively parallel GPU architectures—such as NVIDIA A100 or H100—that enable deep learning, natural language processing, and computer vision at scale.
Parallel computing is also at the heart of innovations like quantum computing and neuromorphic systems, which emulate neural architectures to process data more efficiently. Even mobile and edge devices now embed parallel processing capabilities to support real-time AI at the edge.


What Is Distributed Computing?
Distributed computing spreads tasks across multiple machines—often in different physical locations—networked together to function as a single system. Each node handles a portion of the workload and communicates results back to a central system.
Examples include:
- MapReduce and big data platforms like Apache Hadoop and Spark
- Distributed rendering in animation/VFX
- Multi-agent simulations in aerospace and automotive design
Distributed architectures are common in cloud computing, edge environments, and large-scale IoT systems, where scalability and geographic distribution are essential.
The lines between parallel and distributed computing are increasingly blurred in modern HPC and AI deployments, where disaggregated architectures leverage both approaches simultaneously. This convergence drives demand for storage platforms that support high bandwidth, low latency, and massive concurrency.
Parallel vs. Distributed: Key Differences
While both approaches break down complex problems into smaller tasks, they differ fundamentally in architecture and implementation.
System Architecture
Parallel computing operates within a single machine or tightly coupled cluster. Multiple processors share access to the same physical hardware with unified memory architecture, enabling rapid communication between processing units.
Distributed computing spans multiple independent computers connected via network. Each node operates autonomously with its own processor, memory, and operating system, coordinating through network protocols.
Memory Organization
In parallel systems, processors share a common memory space. This shared memory architecture enables fast data exchange—processors read and write to the same memory locations. However, this shared resource can become a bottleneck as processor count increases.
Distributed systems use independent memory at each node. Nodes communicate by passing messages containing needed data. This distributed memory model eliminates memory contention but introduces network communication overhead.
Communication Methods
Parallel computing relies on high-speed internal buses or interconnects. Communication happens at memory speed—nanoseconds for cache-to-cache transfers, microseconds for main memory access. This low latency makes parallel systems ideal for tightly coupled problems requiring frequent coordination.
Distributed systems communicate through network protocols. Network communication introduces latency, typically measured in milliseconds, depending on geographic distance. This means distributed systems work best for loosely coupled problems where tasks operate independently.
Scalability
Parallel computing scales vertically—adding more processors to a single system. This approach hits physical limits: memory bandwidth constraints, thermal limitations, and bus contention. Most parallel systems scale to hundreds of cores.
Distributed computing scales horizontally—adding more machines to the network. Systems can grow from a handful of nodes to thousands of machines. Cloud platforms routinely operate distributed systems spanning data centers worldwide.
Fault Tolerance
Parallel systems typically represent a single point of failure. If the machine fails, the entire computation stops.
Distributed systems offer inherent fault tolerance. When one node fails, other nodes continue processing. Well-designed distributed systems detect failures, reassign work, and maintain operation as individual machines go offline.
Geographic Distribution
Parallel computing concentrates processing in a single location. All processors reside in the same data center, connected by local infrastructure.
Distributed computing enables geographic distribution. Nodes can operate in different cities or continents, supporting use cases like content delivery networks and compliance with data residency regulations.
The lines between parallel and distributed computing are increasingly blurred in modern HPC and AI deployments, where disaggregated architectures leverage both approaches simultaneously.
Modern Applications of Parallel Computing
Beyond traditional scientific computing, parallelism powers many cutting-edge workloads:
- AI and machine learning: Training large models using data parallelism across GPU clusters
- Real-time analytics: Fraud detection, autonomous driving, and live recommendation engines
- High-frequency trading: Ultra-low latency transaction processing
- Cryptocurrency mining: Efficient hashing and consensus validation
- Aerospace and energy: Multiphysics simulations and predictive modeling
Everpure supports these industries with data platforms capable of sustaining multi-terabyte-per-second bandwidth across highly parallel compute clusters.
Hybrid Models and Convergence Trends
Modern workloads increasingly use hybrid models that combine parallel and distributed computing—for example, a distributed training framework like Horovod or PyTorch Lightning running on a GPU cluster using data-parallel methods.
FlashBlade and the newest member of the FlashBlade family, FlashBlade//EXA, are uniquely suited to these environments. With support for concurrent mixed workloads, multi-protocol access (NFS, S3), and elastic scalability, they eliminate the need to rearchitect storage systems for each computing paradigm.
The Role of Storage in Parallel and Distributed Computing
No matter how powerful your processors are, they’re only as effective as the data pipelines feeding them. Storage bottlenecks are often the limiting factor in both parallel and distributed environments.
FlashBlade and the newest member of the FlashBlade family, FlashBlade//EXA, are designed to overcome these limitations with:
- High-throughput, ultra-low-latency performance
- Massive parallelism across thousands of concurrent clients
- Scale-out file and object storage built for AI, analytics, and HPC
These platforms support both shared-memory parallelism (for GPU farms and tensor processors) and distributed file access (for large-scale AI/ML, genomics, and simulation workflows).
Conclusion
Understanding the differences between parallel and distributed computing is essential for architecting modern data infrastructure. Parallel computing delivers maximum performance for tightly coupled workloads requiring ultra-low latency communication within a single system. Distributed computing provides unlimited scalability and fault tolerance for loosely coupled problems spanning multiple machines or geographic regions.
The choice between these approaches depends on your specific requirements. When tasks need frequent coordination and sub-millisecond response times, parallel architectures excel. When applications must scale horizontally, tolerate failures gracefully, or process data across distributed locations, distributed systems are the answer. Many modern workloads leverage both—using parallel GPU clusters within distributed cloud infrastructures.
Storage performance determines whether your compute infrastructure reaches its potential. No matter how powerful your processors, they're only as effective as the data pipelines feeding them. FlashBlade and FlashBlade//EXA eliminate storage bottlenecks with high-throughput, ultra-low-latency performance designed for both parallel and distributed architectures. They support the massive concurrency, mixed workloads, and elastic scalability that modern HPC, AI, and data analytics demand.
Ready to eliminate storage bottlenecks? Explore FlashBlade solutions or contact Everpure to discuss your specific computing architecture.
We Also Recommend...
Browse key resources and events

TRADESHOW
Pure Accelerate 2026
June 16-18, 2026 | Resorts World Las Vegas
Get ready for the most valuable event you’ll attend this year.

PURE360 DEMOS
Explore, learn, and experience Everpure.
Access on-demand videos and demos to see what Everpure can do.

VIDEO
Watch: The value of an Enterprise Data Cloud
Charlie Giancarlo on why managing data—not storage—is the future. Discover how a unified approach transforms enterprise IT operations.

BLOG
What’s in a Net Promoter Score?
For nine consecutive years, Everpure has maintained a Net Promoter Score of over 80. Find out how we did it and what it means for our customers.
Personalize for Me