Die Grenzen zwischen parallelem und verteiltem Computing verwischen sich in modernen HPC- und AI-Implementierungen, bei denen disaggregierte Architekturen beide Ansätze gleichzeitig nutzen. Diese Konvergenz treibt die Nachfrage nach Storage-Plattformen voran, die eine hohe Bandbreite, geringe Latenz und massive Parallelität unterstützen.
Parallel vs. verteilt: Wichtige Unterschiede
Während beide Ansätze komplexe Probleme in kleinere Aufgaben aufteilen, unterscheiden sie sich grundlegend in Architektur und Implementierung.
Systemarchitektur
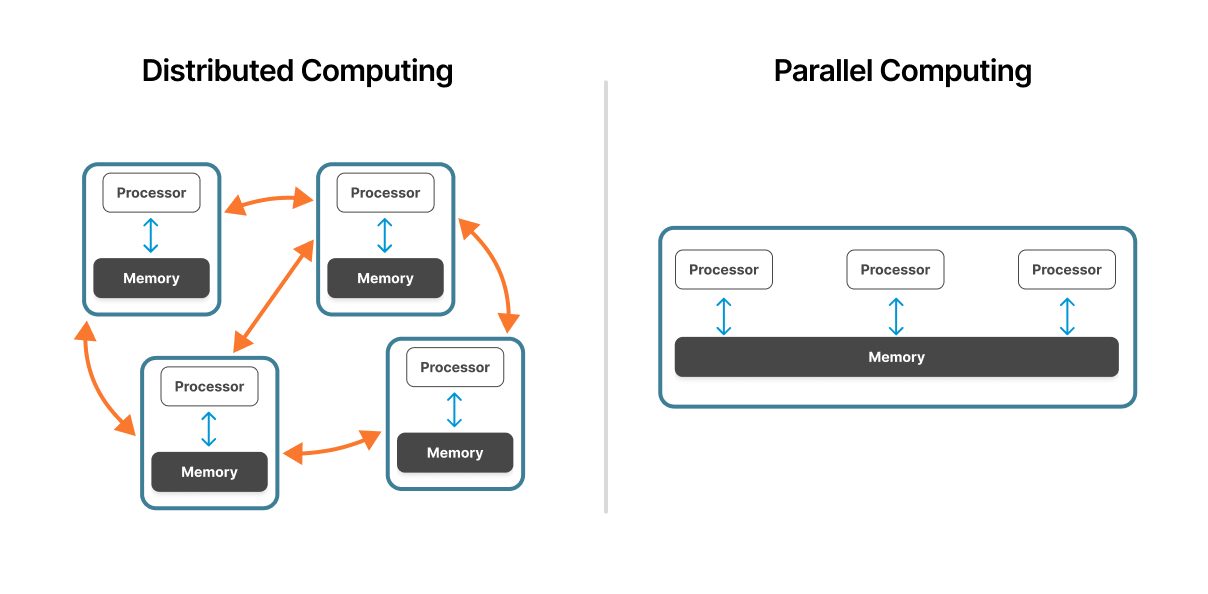
Paralleles Computing funktioniert innerhalb einer einzigen Maschine oder eines eng gekoppelten Clusters. Mehrere Prozessoren nutzen den Zugriff auf dieselbe physische Hardware mit einheitlicher Speicherarchitektur, was eine schnelle Kommunikation zwischen den Verarbeitungseinheiten ermöglicht.
Verteiltes Computing umfasst mehrere unabhängige Computer, die über ein Netzwerk verbunden sind. Jeder Knoten arbeitet autonom mit seinem eigenen Prozessor, Speicher und Betriebssystem und koordiniert dies über Netzwerkprotokolle.
Memory-Organisation
In parallelen Systemen haben Prozessoren einen gemeinsamen Speicherplatz. Diese Shared-Memory-Architektur ermöglicht einen schnellen Datenaustausch – Prozessoren lesen und schreiben an denselben Speicherorten. Diese gemeinsam genutzte Ressource kann jedoch zu einem Engpass werden, wenn die Anzahl der Prozessoren zunimmt.
Verteilte Systeme verwenden an jedem Knoten unabhängigen Speicher. Knoten kommunizieren, indem sie Nachrichten mit den erforderlichen Daten weiterleiten. Dieses Modell für verteilten Speicher eliminiert zwar den Speicherkonflikt, führt aber zu einem Overhead bei der Netzwerkkommunikation.
Kommunikationsmethoden
Paralleles Computing basiert auf internen Hochgeschwindigkeitsbussen oder -verbindungen. Die Kommunikation erfolgt mit Speichergeschwindigkeit – in Sekundenschnelle für Cache-zu-Cache-Übertragungen, in Mikrosekunden für den Zugriff auf den Hauptspeicher. Diese geringe Latenz macht parallele Systeme ideal für eng gekoppelte Probleme, die eine häufige Koordination erfordern.
Verteilte Systeme kommunizieren über Netzwerkprotokolle. Netzwerkkommunikation führt zu Latenzzeiten, die in der Regel in Millisekunden gemessen werden, je nach geografischer Entfernung. Das bedeutet, dass verteilte Systeme am besten für lose gekoppelte Probleme geeignet sind, bei denen Aufgaben unabhängig voneinander ausgeführt werden.
Skalierbarkeit
Paralleles Computing skaliert vertikal und fügt mehr Prozessoren zu einem einzigen System hinzu. Dieser Ansatz erreicht physische Grenzen: Einschränkungen der Speicherbandbreite, thermische Einschränkungen und Buskonflikt. Die meisten parallelen Systeme skalieren auf Hunderte von Kernen.
Verteiltes Computing lässt sich horizontal skalieren und fügt dem Netzwerk mehr Maschinen hinzu. Systeme können von einer Handvoll Knoten auf Tausende von Maschinen wachsen. Cloud-Plattformen betreiben routinemäßig verteilte Systeme, die Rechenzentren weltweit umfassen.
Fehlertoleranz
Parallele Systeme stellen in der Regel einen einzigen Ausfallpunkt dar. Wenn die Maschine ausfällt, stoppt die gesamte Berechnung.
Verteilte Systeme bieten eine inhärente Fehlertoleranz. Wenn ein Knoten ausfällt, werden andere Knoten weiter verarbeitet. Gut konzipierte verteilte Systeme erkennen Ausfälle, weisen Arbeiten neu zu und warten den Betrieb, wenn einzelne Maschinen offline gehen.
Geografische Verteilung
Paralleles Computing konzentriert die Verarbeitung an einem einzigen Ort. Alle Prozessoren befinden sich im selben Rechenzentrum, das über eine lokale Infrastruktur verbunden ist.
Verteiltes Computing ermöglicht geografische Verteilung. Knoten können in verschiedenen Städten oder Kontinenten betrieben werden und unterstützen Anwendungsfälle wie Content Delivery Networks und die Einhaltung der Vorschriften zur Datenresidenz.
Die Grenzen zwischen parallelem und verteiltem Computing verwischen sich in modernen HPC - und AI -Implementierungen, bei denen disaggregierte Architekturen beide Ansätze gleichzeitig nutzen.
Moderne Anwendungen von Parallel Computing
Neben der herkömmlichen wissenschaftlichen Datenverarbeitung unterstützt Parallelität viele hochmoderne Workloads:
- KI und maschinelles Lernen: Trainieren großer Modelle mit Datenparallelität über GPU-Cluster hinweg
- Echtzeitanalysen: Betrugserkennung, autonomes Fahren und Live-Empfehlungsengines
- Hochfrequenzhandel: Transaktionsverarbeitung mit extrem niedriger Latenz
- Kryptowährungsabbau: Effizientes Hashing und Konsensvalidierung
- Luft- und Raumfahrt und Energie: Multiphysik-Simulationen und vorausschauende Modellierung
Everpure unterstützt diese Branchen mit Datenplattformen, die in der Lage sind, eine Bandbreite von mehreren Terabyte pro Sekunde über hochparallele Rechencluster hinweg aufrechtzuerhalten.
Hybridmodelle und Konvergenztrends
Moderne Workloads verwenden zunehmend hybride Modelle, die paralleles und verteiltes Computing kombinieren, z. B. ein verteiltes Trainings-Framework wie Horovod oder PyTorch Lightning, das auf einem GPU-Cluster mit datenparallelen Methoden ausgeführt wird.
FlashBlade und das neueste Mitglied der FlashBlade-Familie, FlashBlade//EXA, sind einzigartig für diese Umgebungen geeignet. Dank der Unterstützung für gleichzeitige gemischte Workloads, des Zugriffs auf mehrere Protokolle (NFS, S3) und der elastischen Skalierbarkeit müssen Storage-Systeme für jedes Rechenparadigma nicht neu gestaltet werden.
Die Rolle von Storage bei parallelem und verteiltem Computing
Unabhängig davon, wie leistungsstark Ihre Prozessoren sind, sind sie nur so effektiv wie die Datenpipelines, die sie versorgen. Storage-Engpässe sind oft der einschränkende Faktor sowohl in parallelen als auch in verteilten Umgebungen.
FlashBlade und das neueste Mitglied der FlashBlade-Familie, FlashBlade//EXA, wurden entwickelt, um diese Einschränkungen zu überwinden:
- Performance mit hohem Durchsatz und extrem geringer Latenz
- Massive Parallelität über Tausende gleichzeitiger Clients hinweg
- Scale-out-Datei- und Objekt-Storage für AI, Analysen und HPC
Diese Plattformen unterstützen sowohl Parallelität mit gemeinsamem Speicher (für GPU-Farmen und Tensor-Prozessoren) als auch verteilten Dateizugriff (für umfangreiche AI/ML-, Genomik- und Simulationsworkflows).
Fazit
Das Verständnis der Unterschiede zwischen parallelem und verteiltem Computing ist für die Entwicklung einer modernen Dateninfrastruktur unerlässlich. Paralleles Computing bietet maximale Performance für eng gekoppelte Workloads, die eine Kommunikation mit extrem niedriger Latenzzeit in einem einzigen System erfordern. Distributed Computing bietet unbegrenzte Skalierbarkeit und Fehlertoleranz für lose gekoppelte Probleme, die mehrere Maschinen oder geografische Regionen umfassen.
Die Wahl zwischen diesen Ansätzen hängt von Ihren spezifischen Anforderungen ab. Wenn Aufgaben häufige Koordination und Reaktionszeiten von weniger als Millisekunden erfordern, zeichnen sich parallele Architekturen aus. Wenn Anwendungen horizontal skaliert werden müssen, Ausfälle anständig tolerieren oder Daten über verteilte Standorte hinweg verarbeiten müssen, sind verteilte Systeme die Antwort. Viele moderne Workloads nutzen beides und verwenden parallele GPU-Cluster in verteilten Cloud-Infrastrukturen.
Storage-Performance bestimmt, ob Ihre Recheninfrastruktur ihr Potenzial ausschöpft. Unabhängig davon, wie leistungsstark Ihre Prozessoren sind, sind sie nur so effektiv wie die Datenpipelines, die sie versorgen. FlashBlade und FlashBlade//EXA beseitigen Storage-Engpässe mit Performance mit hohem Durchsatz und extrem niedriger Latenz, die sowohl für parallele als auch für verteilte Architekturen entwickelt wurde. Sie unterstützen die massive Parallelität, gemischte Workloads und elastische Skalierbarkeit, die moderne HPC, AI und Datenanalysen erfordern.
Sind Sie bereit, Storage-Engpässe zu beseitigen? Entdecken Sie FlashBlade-Lösungen oder kontaktieren Sie Everpure, um Ihre spezifische Computing-Architektur zu besprechen.